Why Zero-Hallucination LLMs Remain Impossible: Autoregressive Limits and Benchmark Ceilings in 2026
Table of Contents
ELI5
Language models predict the next word by probability, not truth. Hallucination isn’t a bug to patch — it’s a mathematical consequence of how prediction works, and no amount of scaling eliminates it.
A model scores 0.7% on a hallucination benchmark, and headlines declare the problem nearly solved. Then the same class of model, tested on longer enterprise documents, hallucinates above 10%. The benchmark changed — the model didn’t — and that gap between the two numbers is where the real story lives.
The Proof Nobody Wanted
Every few months, a new model announcement includes a line about “dramatically reduced hallucination rates.” The framing implies that Hallucination is a disease and that we are approaching the cure. But in 2024, a formal proof arrived that reframed the question entirely.
Can AI hallucination be completely eliminated
No. And the reason is not engineering debt — it is a mathematical boundary.
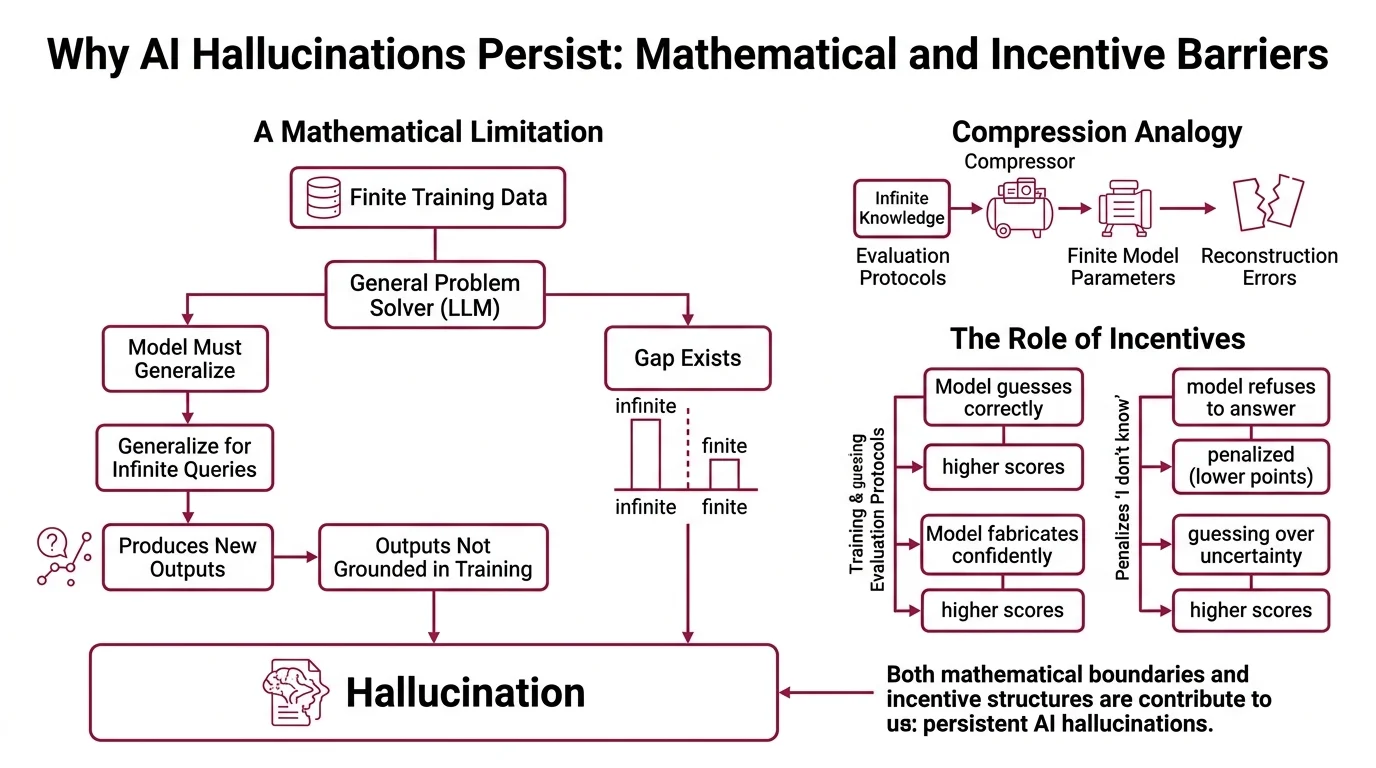
Xu, Jain, and Kankanhalli demonstrated that any LLM functioning as a general problem solver cannot learn all computable functions (Xu et al.). The proof hinges on a fundamental constraint: for a model trained on finite data to generalize across infinite possible queries, it must at some point produce outputs not grounded in its training distribution. That production is hallucination.
Think of it like a compression algorithm applied to all human knowledge. No matter how sophisticated the codec, compressing infinite information into finite parameters guarantees reconstruction errors. The question was never “will errors exist?” The question was always “where will they appear and how often?”
This constraint is not specific to transformers, to autoregressive generation, or to any particular architecture. It applies to any system that generates outputs from learned statistical patterns over finite data. Even a hypothetically perfect training corpus would not eliminate the problem, because the gap between finite training and infinite queries is the source of the error itself.
A second mechanism compounds the mathematical one: the training process actively rewards hallucination. Kalai, Nachum, Vempala, and Zhang showed that current training and evaluation protocols incentivize guessing over acknowledging uncertainty (Kalai et al.). Benchmarks penalize “I don’t know.” Models that refuse to answer lose points. Models that confidently fabricate — even incorrectly — score higher on most evaluation frameworks.
The incentive structure doesn’t merely fail to prevent hallucination.
It selects for it.
Why do larger language models still hallucinate despite more parameters and training data
The intuition that bigger models should hallucinate less has surface-level plausibility. More parameters mean more capacity for storing factual relationships. More training data means fewer gaps in coverage. And the historical trend partly supports this: hallucination rates dropped from 21.8% in 2021 to as low as 0.7% in best-case scenarios by 2025 — a 96% improvement (All About AI).
But that best-case figure obscures a structural problem.
The 0.7% rate — achieved by Gemini-2.0-Flash — was measured on the original HHEM dataset of relatively short, simple documents. On the upgraded HHEM dataset containing enterprise-length documents up to 24,000 words, frontier models tell a different story. Claude Sonnet 4.6 hallucinates at 10.6%, GPT-5.2 xhigh at 10.8%, and Claude Opus 4.6 at 12.2% (Suprmind). Scale compresses the error rate on familiar territory, but the rate floor never reaches zero — it asymptotes toward a value that depends on task complexity, document length, and the distance between query and training distribution.
And here is where the anomaly becomes genuinely revealing.
Reasoning models — the architectures specifically engineered to “think harder” — perform worse on grounded summarization tasks. The o3-Pro model, OpenAI’s most capable reasoning system at the time of testing, hallucinated at 23.3% on the HHEM benchmark (Vectara GitHub). The system designed for accuracy on complex problems introduces more fabrication when asked to faithfully reproduce existing information.
Not a paradox. A trade-off.
Reasoning models allocate additional computation to constructing plausible chains of inference. That extended Chain-of-Thought generation surface creates more moments where the probability distribution drifts from the source material. Each intermediate step is another point where the model may prioritize coherent reasoning over faithful Grounding — producing an answer that is internally consistent but externally invented. The chain itself becomes the hallucination vector.
Measuring What You Cannot Define
The word “hallucination” suggests a single phenomenon. It is not. It is an umbrella covering at least four distinct failure modes, and the benchmarks designed to measure them diverge so dramatically that a model can rank first on one and mediocre on another.
What are the limits of hallucination benchmarks like Vectara HHEM in 2026
The Vectara HHEM benchmark — currently at version 2.3 commercially and 2.1-Open for open source — measures one specific thing: Factual Consistency in document summarization (Vectara GitHub). It tests whether a model’s summary contains only information present in the source document. It does not test whether the model knows facts about the world, whether it can distinguish reliable from unreliable sources, or whether its expressed confidence matches its actual accuracy.
The upgraded HHEM dataset now covers 7,700+ articles ranging from 50 to 24,000 words — a significant expansion beyond the original short-document set, and one that makes older leaderboard scores incomparable to current ones. As of March 2026, the top performer is Antgroup/Finix_s1_32b at 1.8% (Vectara GitHub). But that number measures summarization faithfulness on a specific corpus, not “hallucination” in the way most people use the term.
Other benchmarks target entirely different failure surfaces. FACTS evaluates multi-dimensional factuality across several capability axes, and its top score — Gemini 3 Pro at 68.8 — sits well below 100, revealing a hard ceiling on truthfulness that no model has approached (Suprmind). AA-Omniscience tests knowledge calibration; at least one model achieved a reported 0% hallucination rate on it, but only through an aggressive refusal strategy — it doesn’t hallucinate because it declines to answer uncertain questions. CJR measures citation accuracy, yet another orthogonal dimension entirely.
No single benchmark captures what “hallucination” means. Treating any individual score as “the hallucination rate” is itself a category error — a measurement hallucination, if you will.
The definitional problem runs deeper than methodology. A model that summarizes documents faithfully but invents facts about the world is “non-hallucinating” by HHEM and “hallucinating” by knowledge benchmarks. A model that refuses uncertain questions scores well on calibration tests and poorly on helpfulness metrics. These benchmarks measure different projections of the same high-dimensional problem, and that problem has no single number that captures all its faces.
The Asymptote and What It Predicts
If hallucination cannot be eliminated, the engineering question shifts from “how do we reach zero?” to “how do we build systems that remain reliable despite a non-zero error floor?”
Retrieval Augmented Generation reduces hallucination rates by roughly 71% with proper implementation (Lakera). That improvement is substantial — but RAG introduces its own dual failure points: the retrieval step can miss relevant documents, and the generation step can still fabricate even when given correct context. Grounding techniques anchor outputs to verified data, but they work only as well as the retrieval pipeline feeding them.
Meanwhile, model confidence remains poorly calibrated. Models express high certainty even when their internal representations are ambiguous, and tool-augmented models with web search access show worse calibration than unaugmented ones — not better. Adding external tools does not teach a model what it doesn’t know. It gives the model more material to be confidently wrong about.
If a task demands factual precision, treating language model output as a draft rather than a source is not excessive caution. It is the mathematically honest position.
Rule of thumb: Treat hallucination rate as a function of task complexity and document length, not as a fixed model property. The same architecture that scores 1.8% on short summaries can exceed 10% on enterprise documents.
When it breaks: Any pipeline that treats LLM output as authoritative without downstream verification inherits the model’s full hallucination rate. For enterprise document processing at scale, frontier models on realistic benchmarks sit between 10% and 23% — not the sub-1% figures from simpler test sets.
The Data Says
Hallucination is not a temporary deficiency in current language models. It is a structural consequence of finite models attempting to generalize across infinite queries — proven mathematically, confirmed empirically, and resistant to scaling. Rates have dropped dramatically over five years, but the floor remains above zero and shifts upward with task complexity. The productive engineering response is not to chase elimination but to architect systems that assume non-zero error and verify accordingly.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors