Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Table of Contents
ELI5
Every token must attend to every other token. Double the sequence length, and the math doesn’t double — it quadruples. That’s the wall.
The Misconception
Myth: Context windows are growing fast enough that memory limits will soon be irrelevant.
Reality: Advertised context windows are growing. The quadratic cost of filling them is growing faster.
Symptom in the wild: A model accepts your 100K-token prompt without complaint — then returns answers that ignore everything in the middle third.
How It Actually Works
The Transformer Architecture processes sequences by letting every token look at every other token through a mechanism called self-attention. Picture a room where every person must shake hands with every other person. Add one more person, and the number of handshakes doesn’t grow by one — it grows by the number of people already in the room. That handshake ceremony is the computational heart of the architecture, and it determines everything about what these models can and cannot do at scale.
Why does transformer self-attention scale quadratically with sequence length?
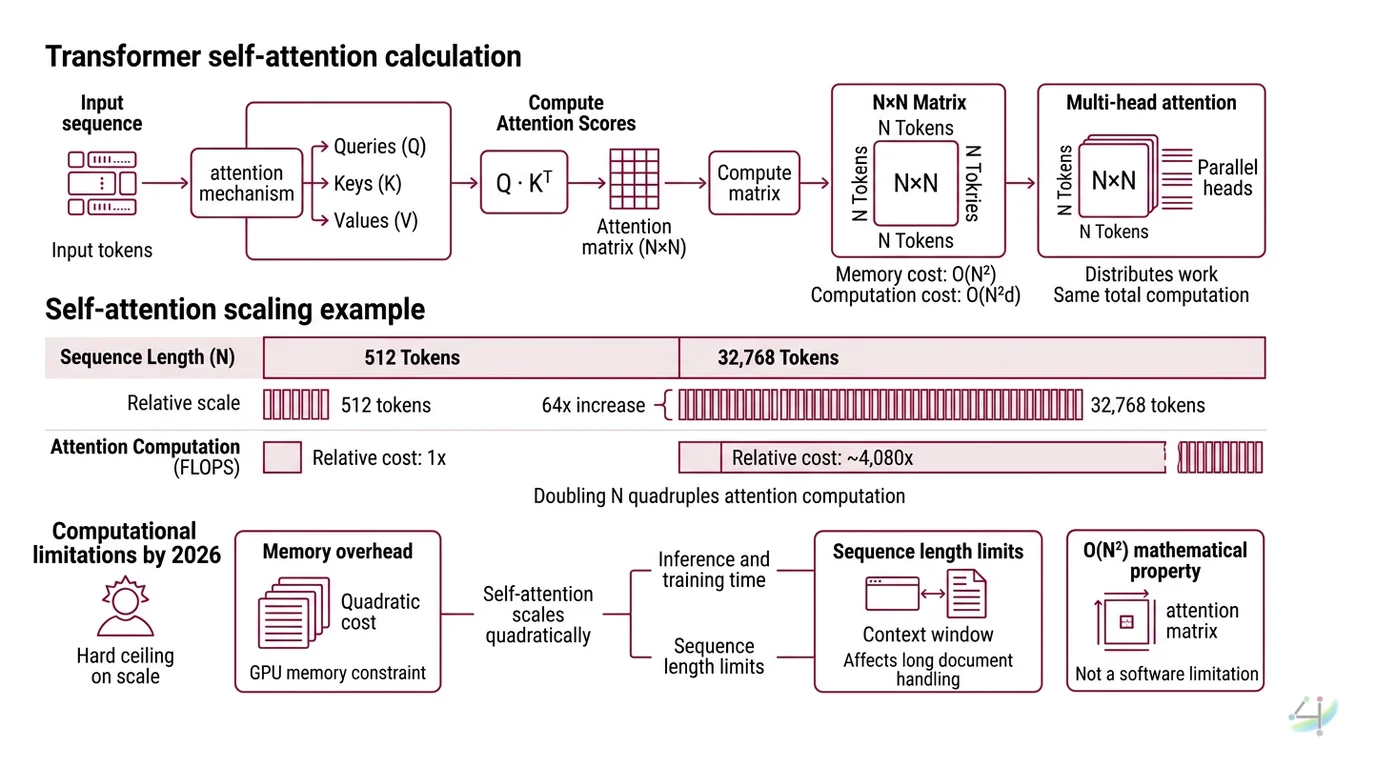
Self-attention, as described in the original “Attention Is All You Need” paper (Vaswani et al.), computes three matrices — queries, keys, and values — from the input sequence. The attention score matrix is the dot product of queries and keys: an n-by-n matrix, where n is the number of tokens.
Every entry in that matrix represents a relationship between two tokens. The computation requires O(n²d) floating-point operations, where d is the model dimension, and the attention matrix itself demands O(n²) memory (Brenndoerfer).
The growth is not gentle.
Going from 512 tokens to 32,768 tokens — a factor of 64 in sequence length — multiplies the required FLOPs by roughly 4,080 times (Brenndoerfer). Not 64 times. Not 640 times. Over four thousand times, because each doubling of n quadruples the attention computation.
This is not a software limitation waiting for a clever optimization. It is a mathematical property of the attention mechanism itself. Multi Head Attention splits the computation across parallel heads, but each head still computes its own n-by-n attention matrix. More heads distribute the work — they do not reduce the total.
What are the computational limitations of transformer models in 2026?
The quadratic cost creates a hard ceiling on what fits inside a single GPU’s memory. At 32,768 tokens with 12 attention heads in FP16 precision, a single layer’s attention matrices alone require approximately 288 GB of memory (Brenndoerfer). An 80 GB GPU — the current high-end standard — can practically train with standard attention on roughly 16,000 to 32,000 tokens before running out of memory.
During inference, the bottleneck shifts from attention matrices to the KV cache. The key-value cache stores the computed keys and values for all previous tokens so the model doesn’t recompute them at each generation step. Its memory footprint grows linearly with sequence length but accumulates across every layer and every attention head.
For a model like LLaMA 7B at 128,000 tokens in FP16, the KV cache alone consumes approximately 64 GB (Brenndoerfer). That is the cache. Not the model weights. Not the activations. Just the running memory of what the model has already seen.
Quantized caches — FP8 or FP4 — can reduce this footprint, but the reduction comes with accuracy trade-offs that are still being characterized.
As of 2026, context window sizes have continued expanding: Llama 4 Scout reaches 10 million tokens, Gemini 3 Pro offers 10 million, GPT-4.1 supports 1 million, and Claude 4 Sonnet provides 200,000 (Elvex). But advertised length and effective length are not the same thing. Approximately 60 to 70 percent of the advertised window is effectively used; retrieval accuracy for information placed in the middle of long contexts degrades to 76 to 82 percent accuracy (Elvex). The tokens are there. The attention is not evenly distributed across them.
How does the memory bottleneck in transformers limit context window size?
The memory wall operates at two timescales.
During training, the full n-by-n attention matrix must be materialized — or at least tiled efficiently — for backpropagation. This is why training on million-token contexts requires either distributed systems that shard attention across many GPUs, or architectural modifications that approximate the full attention pattern.
During inference, the KV cache is the binding constraint. Every token generated extends the cache, and the memory grows with each step. A model serving multiple users simultaneously multiplies this cost by the batch size. The formula is precise: 2 (keys and values) multiplied by the number of layers, batch size, sequence length, number of KV heads, head dimension, and bytes per element (Brenndoerfer).
This is why Context Window sizes remain a defining engineering challenge even as raw model capabilities improve. The window is not limited by what the model can learn — it is limited by what the hardware can remember.
What This Mechanism Predicts
- If you double the context length of a standard transformer, expect the attention computation to quadruple — and plan GPU memory accordingly.
- If retrieval accuracy matters for your task, the failure mode is the “lost in the middle” effect: information placed in the center of long contexts is systematically under-attended.
- If you adopt KV cache quantization (FP8, FP4) for longer contexts, the trade-off is measurable accuracy degradation that varies by task and model.
What the Math Tells Us
The quadratic wall has spawned two families of solutions, and they solve different parts of the problem.
FlashAttention — now at version 4 with Blackwell GPU support — doesn’t change the O(n²) complexity. It changes where the computation happens. By tiling the attention computation to fit within GPU SRAM rather than relying on slower HBM, FlashAttention-3 achieved 1.5 to 2 times the speed of its predecessor, reaching 740 TFLOPS at 75 percent H100 utilization (Tri Dao). FlashAttention-4 extends this to Blackwell architecture, running up to 22 percent faster than cuDNN (Tri Dao). These are engineering triumphs — faster quadratics, but still quadratics.
The alternative is to abandon quadratic attention entirely. State-space models like Mamba achieve linear-time inference with reported throughput gains of 5 times over standard transformers (Gu & Dao). Mamba-3, published at ICLR 2026, introduced complex-valued states that improved accuracy by 0.6 percentage points at the 1.5-billion parameter scale while halving the state size compared to Mamba-2. Hybrid architectures like AI21’s Jamba combine Mamba layers with transformer layers and Mixture Of Experts routing — 398 billion total parameters with 94 billion active — to maintain attention’s strength on recall-heavy tasks while keeping inference tractable at 256,000 tokens (AI21 Blog).
The constraint is mathematical, not just engineering.
Rule of thumb: When evaluating whether a model can handle your context length, calculate the KV cache memory separately from the model weights. If the cache exceeds half your available GPU memory, you will hit throughput problems before you hit accuracy problems.
When it breaks: Standard self-attention becomes impractical beyond roughly 32,000 tokens on a single 80 GB GPU for training workloads. Beyond that threshold, you need either attention approximations (which sacrifice some recall accuracy), distributed sharding (which adds latency), or non-attention architectures (which sacrifice the global token-to-token visibility that makes transformers powerful in the first place).
Security & compatibility notes:
- FlashAttention-4: Currently supports forward pass only (inference); backward pass support is planned. FA-3 remains in beta; FA-2 is integrated into PyTorch core.
- Mamba SSM (HiSPA vulnerability): A hidden state poisoning attack vector has been identified for SSM-based models, though production severity remains unclear.
One More Thing
Positional Encoding — the mechanism that tells the model where each token sits in the sequence — was originally designed for fixed-length inputs. Rotary positional embeddings and ALiBi extended the reach, but they are still approximations of position over sequences far longer than any training set covered. The model’s sense of “where” degrades before its sense of “what.”
The Encoder Decoder architecture from the original transformer paper splits the quadratic cost across two smaller attention computations — encoder self-attention and decoder cross-attention — which is why encoder-decoder models historically handled longer sequences more efficiently than decoder-only designs. The industry’s shift toward decoder-only architectures traded that structural advantage for simpler training dynamics and better scaling properties.
Tokenization efficiency compounds the problem: a tokenizer that breaks a word into three tokens instead of one effectively triples the sequence length the attention mechanism must process. Fine Tuning on long-context data doesn’t change the quadratic cost — it teaches the model to use the available attention budget more wisely, but the budget itself remains fixed by architecture and hardware.
The Data Says
The quadratic scaling of self-attention is not a bug to be patched — it is a structural property of global token-to-token comparison. Every approach to extending context windows trades one constraint for another: FlashAttention trades memory layout for speed without changing complexity; SSMs trade global attention for linear inference; hybrids trade architectural simplicity for the best of both. The wall is real. The question is which detour costs you the least for your specific workload.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors