Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Table of Contents
ELI5
Standard attention compares every word to every other word. Double the text, quadruple the cost. That math stops working at long documents.
The Misconception
Myth: Long-context failures are an engineering problem — throw more GPUs at the model and it handles longer inputs.
Reality: The bottleneck is algorithmic. Standard self-attention grows as the square of sequence length, so hardware alone cannot outrun the curve.
Symptom in the wild: A model that handles 8K tokens fluently starts producing incoherent summaries at 64K — not because it forgot, but because the compute budget exploded sixty-four-fold.
How It Actually Works
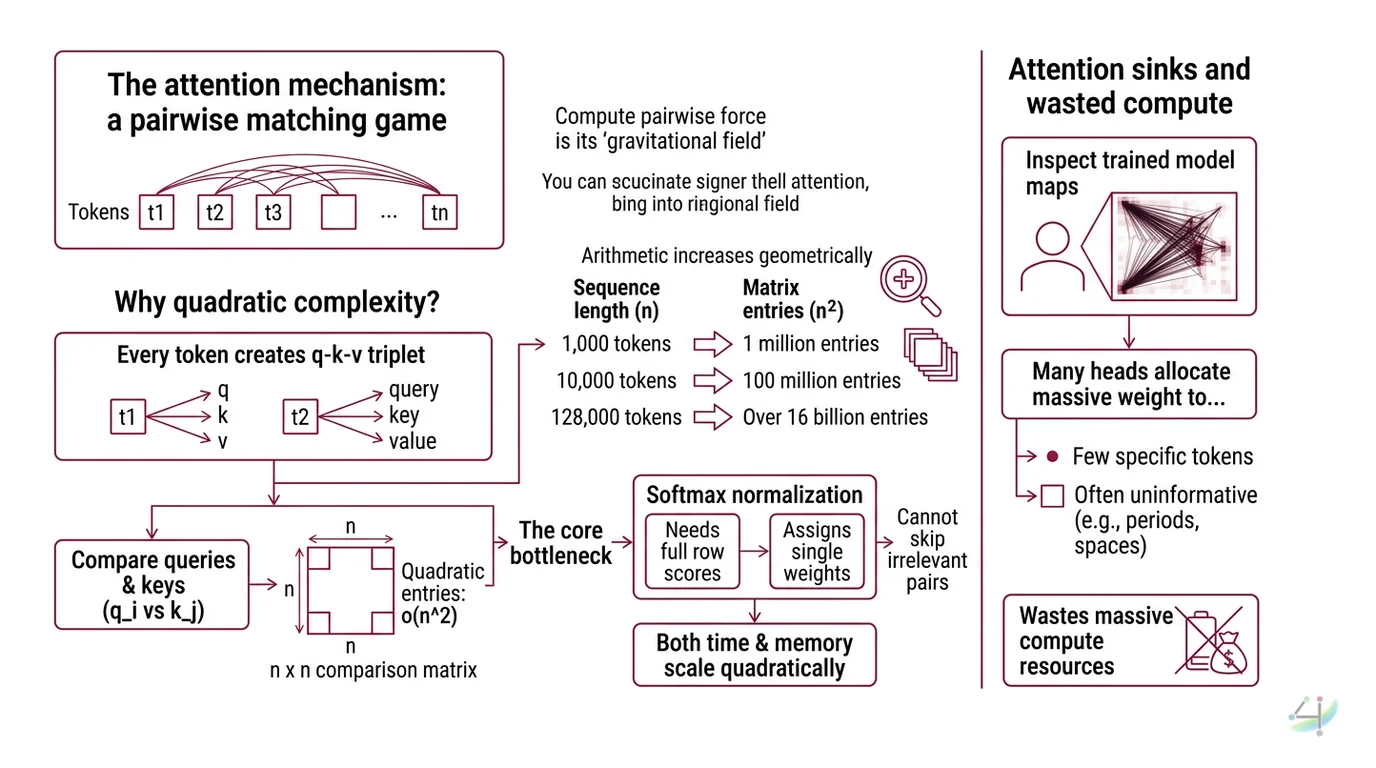
The Attention Mechanism is, at bottom, a matching game played across every pair of tokens in a sequence. Think of it as a gravitational field: each token exerts a pull on every other token, and the system must compute every single pairwise force before deciding which connections matter. That pairwise structure is what makes attention powerful — and what makes it expensive. The cost does not grow gently; it grows geometrically.
Why does attention have quadratic complexity with sequence length?
Every token in a sequence produces a Query Key Value triplet. The query from position i is compared against the key at every position j to produce an attention score. For a sequence of n tokens, that comparison matrix has n × n entries.
The arithmetic is relentless. At 1,000 tokens, the matrix has one million entries. At 10,000 tokens: one hundred million. At 128,000 tokens — a length modern models advertise — the matrix holds over sixteen billion entries. Each entry requires a dot product, a Softmax normalization, and a weighted sum.
This is the O(n²) complexity described in the original Transformer Architecture paper (Vaswani et al.). Both time and memory scale quadratically with n. The relationship is not approximate; it is structural. Double the sequence, quadruple the work. No constant-factor optimization changes the exponent.
Why not just skip irrelevant pairs? Because softmax normalization requires the full row of scores before it can assign any single weight. Every token must see every other token’s score to decide how much to attend to any one of them. The bottleneck is not in the comparison — it is in the normalization.
What are attention sinks and why do they waste compute?
Here is something that should bother you.
Take a trained language model. Feed it a long sequence. Inspect the attention maps. You will find that many heads allocate enormous weight to the very first token — regardless of what that token says.
Xiao et al. identified this phenomenon and named it “attention sinks” (ICLR 2024). The initial tokens act as statistical dumping grounds. When a head has no strong preference for any particular token, softmax forces it to place probability mass somewhere. The first tokens, encountered during every training sequence, become default attractors.
Not a bug. A training artifact.
The waste is real. Compute cycles spent attending to a semantically vacuous anchor token produce no useful information flow. In streaming inference — where old tokens are evicted from the context window — removing those initial anchors destabilizes the entire attention distribution. The model does not degrade gracefully; it collapses.
The practical consequence: systems like StreamingLLM retain a handful of initial-token key-value pairs as fixed anchors, enabling stable inference up to 4 million tokens with a 22.2× memory reduction versus sliding-window recomputation (Xiao et al.).
The deeper question — why sinks emerge at all — is still being investigated. Recent work presented at ICLR 2025 links their formation to active-dormant head switching during pre-training, suggesting they are not accidental but a learned optimization strategy.
What are the memory limitations of standard attention in 2026?
The quadratic cost is not only a compute problem. It is a memory problem, and in practice, memory hits the wall first.
Every token in the context carries a key and a value vector that must be stored for the duration of inference. This key-value cache grows linearly with sequence length per layer, but a model with dozens of layers accumulates enormous state. For Llama 3.1 70B at 128K context, the KV cache alone consumes approximately 40 GB for a single request. Near 32K tokens, the KV cache memory equals the memory occupied by the model’s weights themselves.
That crossover point is where standard attention becomes memory-bound rather than compute-bound. Adding more FLOPS does not help when the GPU cannot hold the intermediate state.
The constraint shapes everything downstream: batch sizes shrink, throughput drops, and the cost-per-token climbs steeply with context length. A model that serves a thousand concurrent 4K requests might serve fewer than a hundred at 32K — not because the silicon slowed down, but because the memory filled up.
What This Mechanism Predicts
- If you double your context length, expect roughly four times the latency and memory for the attention layers — plan GPU allocation accordingly.
- If you strip initial tokens from a long-running inference session, the failure mode is sudden distribution collapse, not gradual quality loss.
- If you adopt Flash Attention, you reduce the memory overhead through tiling — but the fundamental O(n²) operation count remains unchanged.
What the Math Tells Us
FlashAttention does not change the exponent. It reorganizes memory access patterns so that the GPU’s SRAM, rather than slow HBM, handles intermediate results. FlashAttention-3 achieves up to 740 TFLOPS on H100 — roughly 75% hardware utilization — representing a 1.5-2x speedup over its predecessor (PyTorch Blog). That is a substantial constant-factor improvement. The quadratic curve simply runs faster.
The real escape route requires changing the algorithm. Linear Attention approaches replace softmax with kernel-based approximations, collapsing O(n²) to O(n). But removing softmax eliminates the sharp competition between tokens — the winner-take-most dynamic that gives standard attention its selectivity. The result, in many configurations, is context collapse: the model attends to everything equally, which is equivalent to attending to nothing.
Newer hybrid architectures are attempting to recover that selectivity at linear cost. Softmax Linear Attention (2026) applies linearity within each attention head while preserving softmax competition across heads (SLA paper). Kimi Linear targets KV cache reduction and improved decoding throughput at million-token scale (Kimi Linear paper). These are promising signals, but the trade-off remains: every shortcut past O(n²) sacrifices some degree of token-level precision.
Rule of thumb: Below 32K tokens, standard attention with FlashAttention is fast enough that the quadratic cost rarely matters in practice. Above 32K, memory becomes the binding constraint and architectural alternatives become necessary.
When it breaks: At context lengths beyond 128K tokens, even FlashAttention-class optimizations cannot prevent KV cache from consuming the majority of GPU memory, forcing either aggressive cache eviction — which risks losing critical context — or multi-node distribution, which introduces inter-node latency that erodes throughput gains.
One More Thing
There is an irony embedded in the attention sink phenomenon. The tokens that receive the most attention weight in a typical long sequence are often the least informative — punctuation marks, BOS tokens, structural markers. The mechanism that was designed to find relevance has learned, as a side effect, to create irrelevance anchors. The model does not attend to the first token because it matters. It attends there because softmax demands that probability mass go somewhere, and the first token is always available.
Not a failure of design. A consequence of the constraint.
The Data Says
Standard attention’s O(n²) scaling is not a fixable inefficiency — it is a structural property of pairwise comparison under softmax normalization. Hardware optimizations like FlashAttention improve constants but preserve the exponent. Attention sinks reveal that even within the quadratic budget, substantial compute is spent on semantically empty anchors. The path forward runs through hybrid architectures that trade some of softmax’s sharp selectivity for linear scaling — a trade-off that, as of 2026, no design has fully resolved.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors