Why RAG Still Fails in Production: Retrieval, Chunking, Grounding

ELI5
Retrieval Augmented Generation pipelines fail in production for three structural reasons: retrieval misses the right chunk, the model under-reads documents in the middle of long context, and the model’s parametric knowledge overrides what was retrieved.
The standard pitch for RAG is that bolting retrieval onto a language model fixes hallucinations — give the model the document, and it will tell the truth. Teams ship that version, run it against real users, and watch the failures arrive in shapes the pitch did not predict. Wrong chunk retrieved. Right chunk retrieved but ignored. Right chunk retrieved, read, and overruled by something the model already believed. The failures are not implementation defects. They are the architecture being honest about what it can and cannot do.
Retrieval Is the First Failure Surface
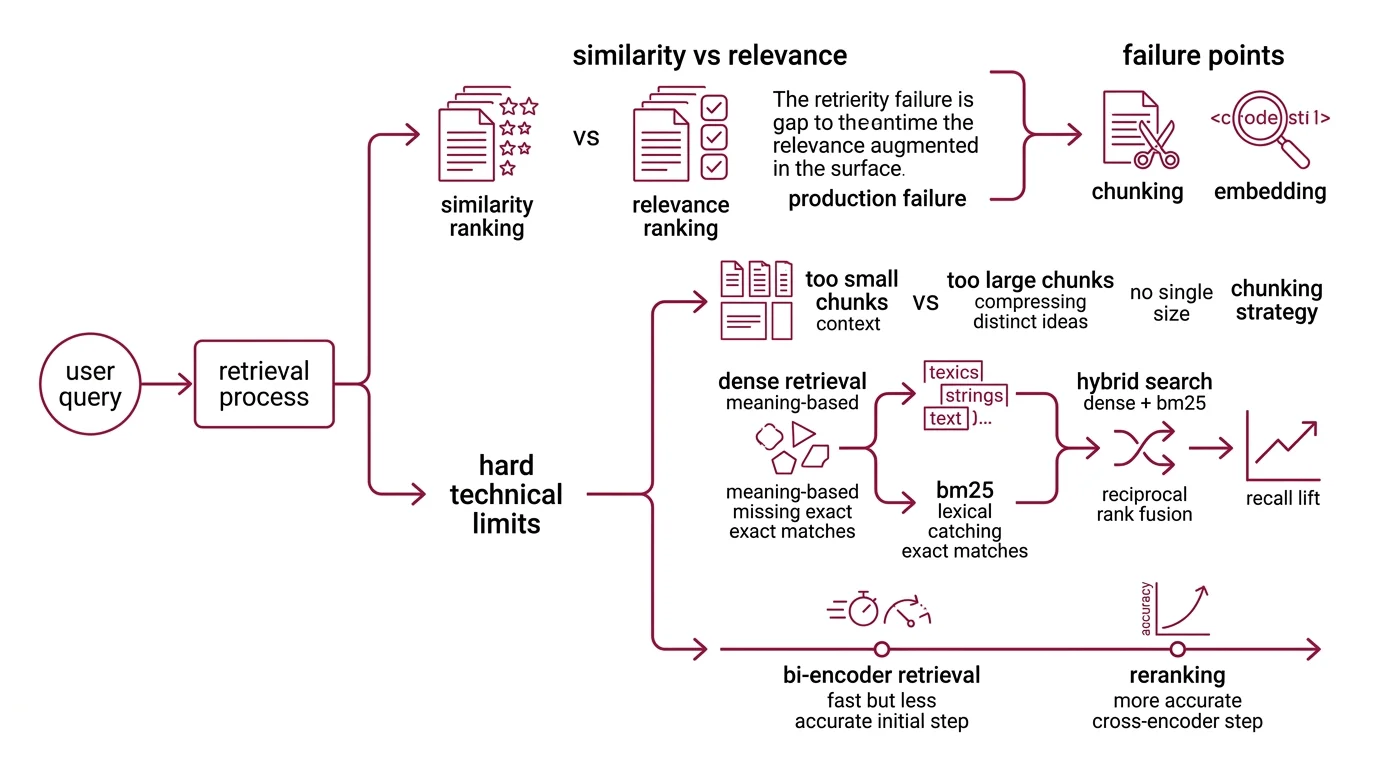
The retriever is doing something narrower than the marketing implies. Given a query embedding, it returns the k chunks whose vectors are closest in some learned space. That is a similarity ranking, not a relevance ranking, and the gap between the two is where the first class of production failures lives. Barnett et al. mapped this systematically — their study of three deployed systems identified seven distinct failure points spanning chunking, embedding, ranking, and downstream generation (Barnett et al. 2024).
What are the hard technical limits of retrieval-augmented generation?
The first hard limit is set by Chunking Strategy. Documents have to be cut into pieces small enough to fit alongside the query in the context window, and every cut is a bet about where the meaning lives. Cut too small, and a chunk no longer contains the surrounding clauses that disambiguate it; cut too large, and the embedding has to compress too many distinct ideas into one vector, blurring the signal the retriever needs. There is no chunk size correct for every document type. Adaptive and semantic chunkers improve recall in published comparisons, but the gains are domain-dependent — they shift the failure distribution rather than eliminate it.
The second hard limit lives in the embedding itself. Dense vector retrieval encodes meaning, but it discards exact lexical matches that BM25 would catch instantly. Acronyms, product codes, version strings, and anything else that depends on character-level identity tend to leak through dense-only setups. Hybrid Search — combining BM25 with dense retrieval and fusing the results via Reciprocal Rank Fusion — closes much of that gap, and recall@10 lifts from the mid-60s into the low-90s are routinely reported. The exact number is dataset-dependent. The direction is not.
The third limit is reranking. Bi-encoder retrieval is fast because it embeds query and document independently, but that independence is also why it ranks badly under load. A cross-encoder re-scores the top-k by reading query and candidate together, and any production system aiming above proof-of-concept has to bolt one on. Cohere Rerank 3.5 ships a single multilingual cross-encoder with a 4096-token context window, supporting more than 100 languages on the same weights (Cohere Docs). It does not solve relevance. It moves the relevance burden out of the bi-encoder, where it never fit.
What this leaves you with is a stack — chunker, embedder, hybrid retriever, reranker — where every layer is a dial that has to be tuned against the actual document and query distribution. Frameworks like LangChain and LlamaIndex make the layers composable, not optional. Skip a layer and the failure rate stops being something a prompt change can fix.
The Geometry of Long Context Has a Middle Problem
The next failure surface is one that most teams meet only after they have fixed retrieval. Suppose you do retrieve the right chunk. Now the orchestration layer drops it into a prompt alongside nine others, the model reads the whole thing, and the answer is still wrong because the model effectively did not read your chunk.
Liu et al. documented the shape of this failure on multi-document question answering: model accuracy drops by more than 30 percentage points when the relevant document sits in the middle of a 20-document context window, compared to the same document at the very beginning or end (Liu et al. 2024 (TACL)). The U-shaped curve held across multiple model families. The effect is model-agnostic — a property of how transformer attention allocates probability mass over long sequences, not of any specific architecture. Frontier models with million-token windows shrink the magnitude of the dip but do not erase it; the phenomenon is documented across model generations rather than fixed at one number.
The mechanism, plausibly, is that attention is not uniformly informative across positions. Positional encodings give the model strong access to the start (where instructions usually live) and to the recent past (where the answer usually lives), and weaker access to the geometric middle of a long input. When your reranker places the gold chunk at rank seven of ten, the model is reading it through a lens that systematically under-weights position seven. The retrieval succeeded. The utilization did not.
This has a clean operational consequence. The order in which you assemble retrieved context is part of your retrieval system, not a cosmetic choice. Putting the highest-ranked chunk last — or first, with explicit “Use this document” framing — is not a hack. It is a workaround for a position bias that is baked into the model.
Grounding Is Not Faithfulness
The third failure surface is the one that survives perfect retrieval. The model has the right chunk, the right position, the right context — and answers something the chunk does not say. This is the failure that earned RAG its bad reputation, and it has nothing to do with the retriever.
Why does RAG still hallucinate even when it retrieves real documents?
Because Grounding is not faithfulness. Grounding means the retrieved evidence is in the prompt; faithfulness means the generated answer is supported by it. The two come apart whenever the model’s parametric prior — what it absorbed during pre-training — disagrees with what the retrieval just provided. The ReDeEP team, working from mechanistic interpretability rather than benchmark observation, traced the failure to a specific dynamic inside the transformer: certain feed-forward layers over-emphasize parametric knowledge in the residual stream while the attention heads responsible for copying retrieved tokens fail to integrate them (ReDeEP (ICLR 2025 Spotlight)). The model has the document in context. The model also has a strong prior. The prior wins.
This makes RAG hallucinations qualitatively different from vanilla LLM hallucinations. The 2025 wave of conflict-aware methods names the situation explicitly. FaithfulRAG resolves disagreements at the fact level by forcing a “self-thinking” pass before generation, so the model reasons about the conflict rather than averaging through it (FaithfulRAG). Adjacent work taxonomizes representative knowledge-conflict scenarios and matches each to a targeted resolution strategy. The fact that an academic taxonomy of conflict types now exists tells you the problem is not exotic — it is the default behavior of a generator trained on the open internet and now being asked to defer to a private document.
Faithfulness has to be measured, not assumed. The Agentic RAG pattern responds to this by adding a verification step: a second pass where an evaluator model checks whether each generated claim is entailed by the retrieved evidence, and re-queries or refuses where it is not. The cost is latency. The benefit is that “the answer cites a source” stops being a proxy for “the answer is true.” The standard production telemetry lives in RAG-specific evaluation frameworks like RAGAS, which exposes Faithfulness, Context Precision, Context Recall, and Answer Relevancy as core metrics — and only Context Recall requires ground-truth labels, which means the others can run on production traffic continuously (Ragas Docs).
What the Failure Surfaces Predict
The three mechanisms are not independent. They compose, and once you see the composition, the symptoms resolve into something predictable rather than mysterious.
- If your retrieval recall on a labeled eval set is weak, no amount of prompt engineering downstream will close the gap — you have a hybrid-retrieval and reranker problem first.
- If retrieval recall is strong but production faithfulness is volatile, the problem is probably position bias and conflict — fix context ordering and add a faithfulness gate before you blame the chunker.
- If faithfulness is good on factual questions but degrades on ones where the model has strong priors (common product names, well-known historical claims), the parametric prior is overruling the retrieval — that is a conflict-resolution problem, not a retrieval problem, and it needs explicit instruction or a verification pass.
- If your system performs on the eval set and degrades on production traffic, your eval distribution does not match the query distribution — fix the eval before you fix the model.
Rule of thumb: measure retrieval recall and answer faithfulness as separate quantities; never collapse them into a single “RAG quality” score, because the fixes for each are different.
When it breaks: the architecture has no built-in mechanism to decide what the model should do when its parametric prior disagrees with the retrieved evidence. Until you write that disagreement protocol into the system — as explicit prompt instruction, an evaluator pass, or fact-level conflict modeling — your RAG pipeline will hallucinate in exactly the cases where the user most needs it not to.
A note on stack currency: as of 2026, Pinecone Serverless v2 is the default architecture and pod-based indexes are legacy; Cohere has consolidated its rerank offering into the single multilingual rerank-v3.5 model, superseding the earlier English-only and multilingual v2 split. Older RAG tutorials pinning to those products are describing a stack that no longer exists in its original form.
The Data Says
RAG production failures are not implementation bugs to be patched out — they are structural consequences of bolting retrieval onto a generator without specifying how the two should disagree. Retrieval misses, position bias, and knowledge conflict are each well-mapped phenomena with their own research literatures, their own mitigations, and their own failure modes when those mitigations are skipped. The systems that work in production are the ones that treat each as a separate engineering surface with its own eval gate.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors