Why RAG Grounding Still Fails: The Hallucination Detection Ceiling

Table of Contents
ELI5
Modern RAG pipelines bolt on detectors—HHEM, Lynx, TruLens, NeMo—to catch Hallucination before it reaches users. They help. But research now shows a measurable detection ceiling the hardest fabrications walk straight through.
A legal team runs every retrieved answer through a groundedness scorer. The dashboard is green. A junior associate finally checks one citation by hand: the case exists, the holding does not. The detector approved a fabrication that quoted real text and invented its meaning. This is not a failure of engineering effort. It is a failure of what the math can see.
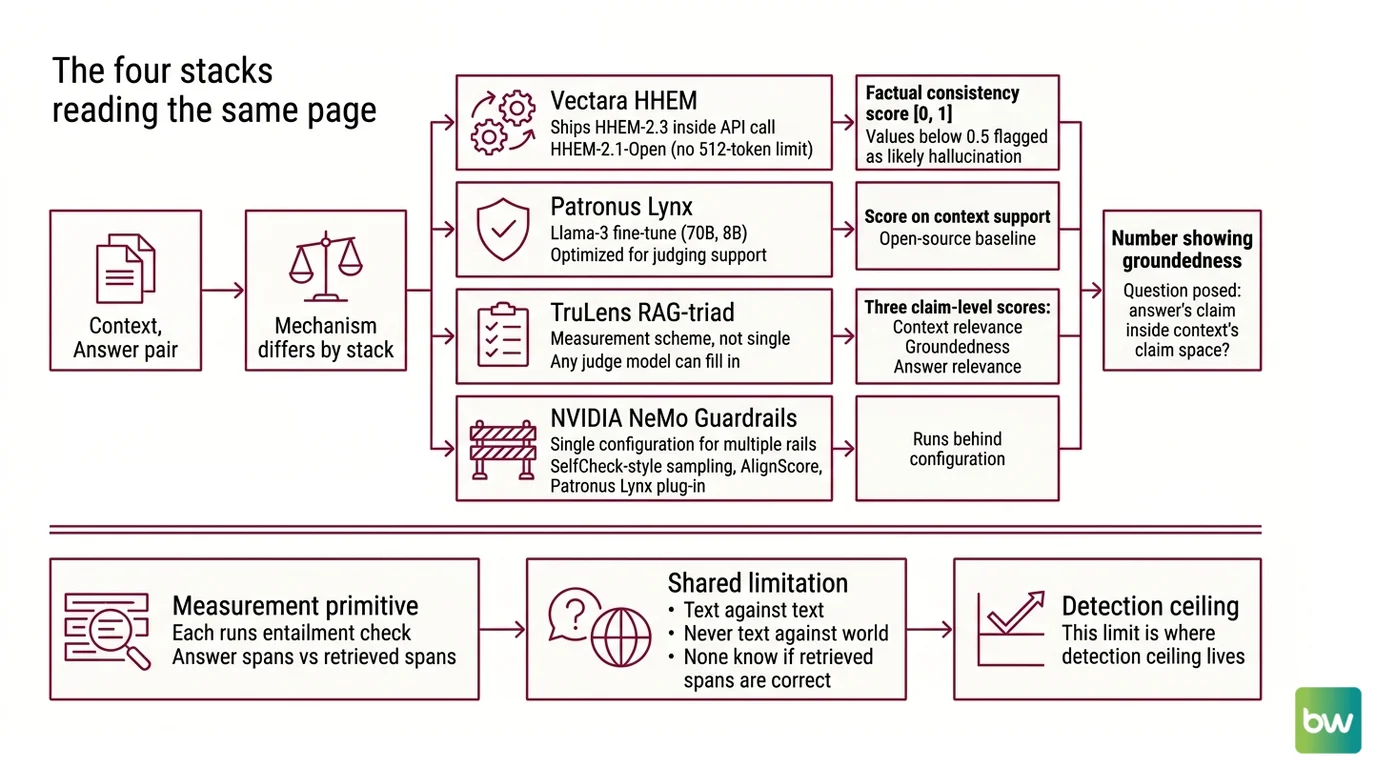
The Four Stacks Reading the Same Page
Four detector families dominate 2026 RAG Guardrails And Grounding production: Vectara’s HHEM, Patronus Lynx, TruLens RAG-triad, and NVIDIA NeMo Guardrails. Each one converts a (context, answer) pair into a number that says how grounded the answer is. The mechanism differs by stack, but the question they pose is the same: does the answer’s claim space stay inside the context’s claim space?
Vectara ships Vectara HHEM HHEM-2.3 inside every API call—each query returns a factual consistency score on the [0, 1] interval, with values below 0.5 flagged as likely hallucination (Vectara Docs). The open-source variant, HHEM-2.1-Open, removes the 512-token ceiling that plagued v1.0 and runs on commodity CPU.
Patronus Lynx Lynx is a Llama-3 fine-tune, released in 70B and 8B parameter versions, optimized for the narrower task of judging whether the answer is supported by the retrieved context. Lynx-70B beat GPT-4o by 8.3% on PubMedQA, and Lynx-8B beat GPT-3.5 by 24.5% on HaluBench (Patronus AI). As of mid-2026, Lynx remains the open-source baseline; no formal successor has been announced.
TruLens TruLens decomposes the problem into three claim-level scores—context relevance, groundedness, and answer relevance. The triad is not a single model; it is a measurement scheme that any judge model can fill in. Nemo Guardrails NeMo Guardrails wires several rails behind a single configuration: SelfCheck-style sampling, AlignScore (a RoBERTa NLI model), and Patronus Lynx as a plug-in.
What unites the four is a measurement primitive: each runs an entailment check between answer spans and retrieved spans. None of them know whether the retrieved spans are themselves correct. Grounding is text against text, never text against world.
And that limit is exactly where the detection ceiling lives.
The Geometry Where Detectors Saturate
The 2026 results from the Semantic Illusion paper changed how the field talks about detection. Researchers tested embedding- and NLI-based detectors on two regimes: synthetic hallucinations seeded into otherwise faithful text, and real hallucinations produced by RLHF-aligned reasoning models. The performance gap is not gradual.
What are the technical limitations of RAG hallucination detection in 2026?
Three constraints stack on top of each other.
The first is representational. Detectors compare embedded claims; if the fabricated claim shares the semantic geometry of supported claims, no embedding model separates them cleanly. On synthetic hallucinations, the best detectors reached 95% coverage at 0% false positive rate. On real RLHF-tuned outputs from frontier models, the same methods hit 100% false positive rate at the target coverage—a measured collapse, not noise (The Semantic Illusion). LLM-as-judge methods do better; GPT-4 as judge holds a 7% FPR (95% CI 3.4–13.7%) on the same hard set—best in class, still imperfect.
The second is benchmark validity. HaluEval, the field’s most-cited hallucination benchmark, can be solved at 93.3% accuracy by a single-feature heuristic—answer length over 27 characters (HalluLens). When a length rule beats most detectors on the standard test set, comparisons between detectors on HaluEval alone are mostly noise rather than signal.
The third is the alignment effect. Vectara’s late-2025 leaderboard refresh, run on a 7,700-article enterprise corpus, found every frontier reasoning model—GPT-5, Claude Sonnet 4.5, Grok-4, Gemini-3-Pro—above 10% hallucination, while Gemini-2.5-flash-lite leads at 3.3% (Vectara Blog). Reasoning post-training raises hallucination, not lowers it. The output sounds more confident; the consistency between answer and context degrades.
Why these three compose into a ceiling is mechanical. Embedding similarity is the substrate the detectors run on; high-confidence reasoning outputs sit very near supported text in that substrate; the test sets used to compare detectors do not stress this region. Stack the three failures and you get a measured plateau, not a tooling gap.
Why Citations Fabricate Inside the Window
Citation fabrication is the failure mode that resists every detector listed above, because the fabrication often passes the entailment check the detector runs.
Pre-RAG mental health work measured GPT-3.5 fabricating 55% of citations and GPT-4 fabricating 18%; even among the real ones, 24–43% contained substantive errors (PubMed Central). Retrieval was supposed to fix this. It did not, fully. Stanford’s audit of LexisNexis Lexis+ AI and Thomson Reuters Westlaw AI—both marketed as “hallucination-free”—found 17–33% of legal queries returned fabricated cases or misstated holdings (Stanford HAI). That figure is from May 2024 fieldwork; vendors may have improved, but no peer-reviewed re-test has appeared in the public literature since.
The mechanism is structural. The retriever pulls a passage that is topically near the question. The generator then composes an answer that quotes the passage truthfully and attributes a claim to it that the passage does not actually make. The cited text is real, the relationship is invented. Entailment scoring sees a quote inside the context, finds the quote supported, and reports high groundedness for the surrounding sentence by association.
FACTUM, posted January 2026, attacks this layer mechanistically. It reframes citation hallucination as an Attention/FFN coordination failure inside the model and produces four diagnostic scores—CAS, BAS, PFS, PAS—from internal activations rather than output text (FACTUM). The bet is that the model’s own attention patterns reveal when it stopped reading the citation and started extrapolating from it.
Whether mechanistic interpretability is the right layer to defend at is, as of mid-2026, an open question. The empirical signal is real. The deployment story is not yet written.
What This Predicts in Your Stack
The mechanism above predicts specific failures.
If your detector runs entailment over passages but you do not score retrieval quality independently, the detector will approve answers grounded in the wrong passage. If you depend on a single judge model—HHEM only, or Lynx only—your false-negative rate floors at whatever that judge cannot see. If your benchmark is HaluEval-only, the leaderboard you trust may be ranking detectors by answer length rather than faithfulness.
Layering helps. RAG Evaluation stacks that combine a retrieval-quality score (TruLens context relevance), a model-level groundedness score (Lynx or HHEM), and a citation-level check (FACTUM-style or claim decomposition) catch failure modes that any single layer misses. They do not eliminate the ceiling. They flatten the regions of input space where it bites hardest.
Hybrid retrieval matters too. Dense retrieval alone overweights semantic similarity over lexical fidelity, and citation fabrication thrives in that gap. Adding Sparse Retrieval restores some lexical anchoring—an attacker, or a confused model, has fewer ways to drift from the cited surface form.
Rule of thumb: Treat any single hallucination score as a smoke alarm, not a sprinkler system.
When it breaks: Detectors saturate fastest on long-form, high-confidence outputs from RLHF-tuned reasoning models—exactly the surface area you most want covered. The 2026 ceiling is not a benchmark artifact; it is a property of measuring text against text when the hallucination is itself well-formed.
The Data Says
Hallucination detection in 2026 is best treated as a measurement, not a fix. The four mainstream stacks catch the easy cases reliably and the hard cases sometimes—the certified ceiling on embedding and NLI methods, and the structural blind spot for citation fabrication, mean a single confident score is the wrong abstraction for production. Layered defenses and honest dashboards beat any one number.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors