Why Perfectly Clean Data Is Impossible: The Technical Limits of Data Curation at Scale
ELI5
Perfect data curation can’t scale because errors hide statistically, not visibly. Finding every bad label would cost more than training the model — and your best automated cleaner is wrong about half the time it raises a flag.
Here is an experiment that should not work the way it does. Take ImageNet, the benchmark that helped launch the deep learning era, and correct its mislabeled validation images. Re-rank the models. ResNet-18 — smaller, older, supposedly weaker — climbs above ResNet-50. The leaderboard you trusted was partly measuring which model best memorized the dataset’s mistakes. Correct the data, and the ranking inverts.
Most engineers treat data cleaning as a finite chore: a sprint, a labeling vendor, a dashboard that eventually turns green. The intuition is that clean data is an engineering problem you can finish. It isn’t. At scale, “clean” stops being a state you reach and becomes a rate you manage — and the math underneath explains why the finish line keeps moving.
The Error Floor Hiding in Every Dataset
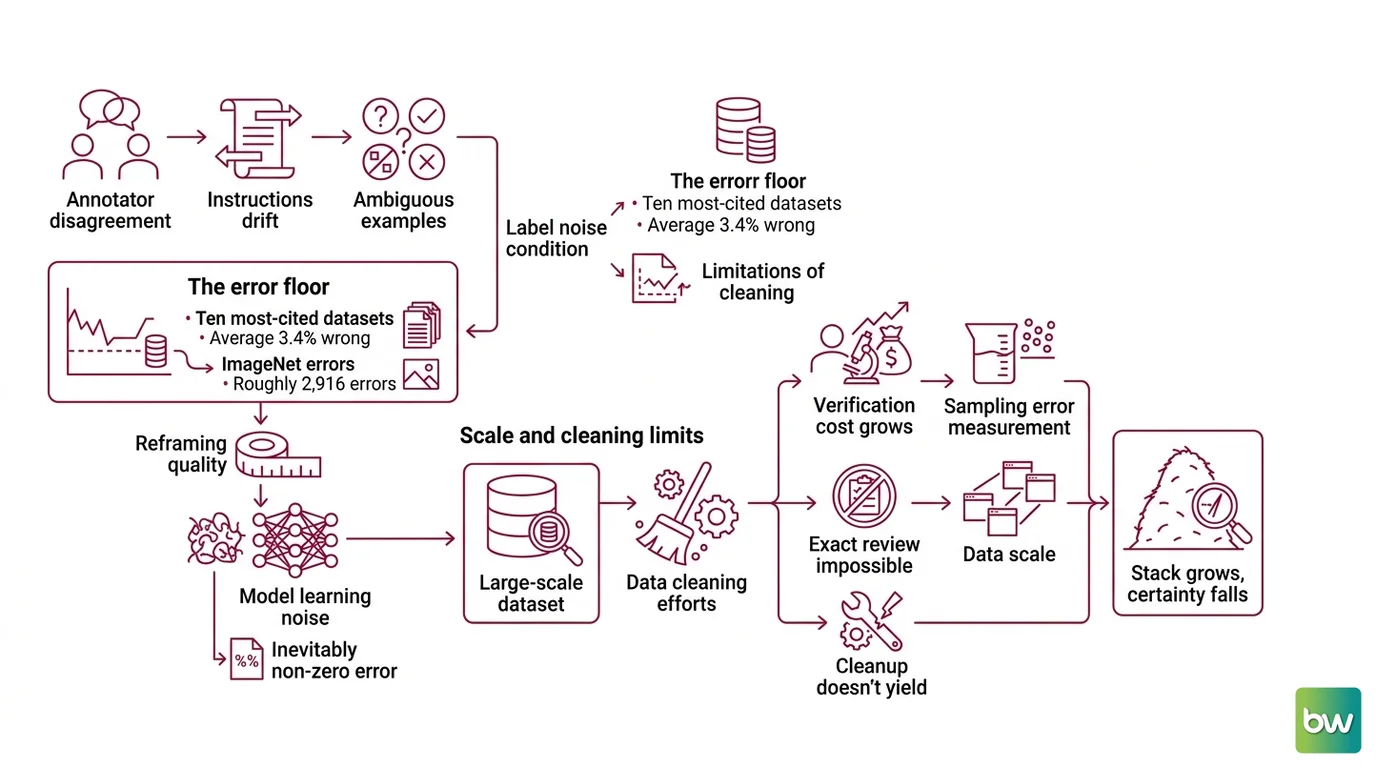
Start with the uncomfortable measurement. When researchers manually audited the ten most-cited computer-vision, NLP, and audio benchmarks, they found labels were wrong an average of 3.4% of the time, with ImageNet’s validation set alone holding roughly 2,916 errors — about 6% (Northcutt et al.). These are not obscure academic corpora. They are the reference datasets the field uses to declare progress.
The point is structural, not a story about sloppy annotators. Label Noise is the baseline condition of any dataset built by humans at volume. Annotators disagree on edge cases, instructions drift across shifts, and genuinely ambiguous examples get forced into clean categories that don’t fit them. The noise isn’t an accident layered on top of good data. It is a property of the labeling process itself.
This reframes what Training Data Quality even means. You are not removing contamination from an otherwise pure signal. You are estimating an error rate you can never drive to zero, because some fraction of your examples have no single correct answer to begin with — and a model trained on them will faithfully learn the noise along with the signal.
Why Scale Turns Cleaning Into a Moving Target
The error floor would be tolerable if cleaning were cheap and exact. It is neither, and both problems get worse as the dataset grows. This is where curation crosses from “tedious” to “technically impossible in the strong sense.”
What are the technical limitations of cleaning training data at scale?
Three limits compound, and none of them yield to more effort.
The first is the cost of certainty grows with the haystack. Verifying a label requires either a human or a trusted reference. For a million-example dataset, exhaustive human review costs more than training the model it would feed. So you sample, and sampling means you measure the error rate without ever locating most of the individual errors. Data-Centric AI reframed the discipline around improving data instead of architecture, but reframing the goal doesn’t repeal the economics of verification.
The second limit is that the best automated detectors are themselves probabilistic. Confident Learning — the method behind tools like Cleanlab — estimates the joint distribution between noisy labels and true labels, then flags examples whose given label looks statistically implausible. It works. It also misfires: when the algorithm’s top candidates were sent to crowdsourced reviewers, only 54% were confirmed as genuinely mislabeled (Northcutt et al.). Roughly half of what your state-of-the-art cleaner flags is a false alarm. You cannot delete on the strength of the flag alone; you still need a human in the loop, which drags you back into the first limit.
The third limit is duplication, which scale actively manufactures. Web-scraped corpora are riddled with near-copies. In Google’s C4 dataset, 1.68% of examples were near-duplicates, and one 61-word passage appeared more than 60,000 times (Lee et al., Google Research). Duplication isn’t cosmetic. Models trained on duplicated data memorize: more than 1% of unprompted language-model output was copied verbatim from training data, and train-test overlap contaminated over 4% of validation sets — meaning the model was quietly tested on examples it had already seen. Data Deduplication helps sharply; after dedup, models emitted memorized text roughly 10× less often. But deduplication at billion-document scale is its own approximate, fuzzy-matching problem — you are trading an exact impossibility for a probabilistic approximation.
Notice the shape of all three. Each one converts a problem you could solve perfectly on a thousand examples into one you can only estimate on a billion. The errors don’t get harder to fix. They get harder to find.
What Imperfect Data Predicts
Once you accept the error floor as a parameter rather than a bug, your engineering decisions change. The goal shifts from “eliminate noise” to “spend your verification budget where the noise hurts most.” A few predictions follow directly from the mechanism:
- If you correct labels in a saturated benchmark, expect model rankings to shift — sometimes inverting — because the leaderboard was partly scoring noise-fit. Treat any sub-point accuracy gap on a noisy benchmark as inside the margin of error.
- If you deduplicate aggressively, expect memorization and train-test leakage to drop faster than raw accuracy rises. Dedup’s biggest payoff is trustworthy evaluation, not a higher score.
- If you rely on an automated cleaner’s flags without review, expect to delete good data at roughly the rate you delete bad data. The false-alarm rate sets a hard ceiling on fully automated cleaning.
This is where Weak Supervision earns its place. Instead of hand-labeling, you write labeling functions — noisy, programmatic heuristics — and let a generative model reconcile their disagreements into probabilistic labels without ground truth. In the original Snorkel study, subject-matter experts built models about 2.8× faster with a 45.5% performance gain over hand-labeling (Snorkel); treat those as figures from one user study, not a universal guarantee. The deeper idea is the one that matters: you stop pretending you can produce clean labels and start modeling the noise explicitly. Active Learning applies the same budget logic to the human-review side, spending scarce expert attention on the examples where the model is most uncertain.
Rule of thumb: measure your error rate, model it, and route human effort to high-impact slices — don’t chase zero.
When it breaks: the whole approach fails silently when noise is systematic rather than random. Confident learning and dedup assume errors are scattered; if an entire annotation guideline was wrong, or one demographic slice was consistently mislabeled, the statistics treat the systematic error as signal and the model learns the bias faithfully. This is also why Data Provenance matters: without knowing where data came from and how it was labeled, you can’t distinguish random noise you can model from systematic noise you can’t.
The Tools Don’t Promise Clean — They Promise Measured
The honest tooling in this space has stopped selling perfection. Cleanlab ships as an open-source confident-learning library positioned as the standard data-centric package for noisy real-world labels, currently at version 2.9.0 (Cleanlab’s GitHub repository). Lightly offers an embedding-based curation approach for selecting the most informative examples rather than scrubbing every bad one, with its LightlyStudio platform released in March 2026 (Lightly). None of them claim to deliver a spotless dataset. They claim to make the error rate visible and direct your attention efficiently — which is the most an honest curation tool can promise.
Compatibility note:
- Cleanlab + TensorFlow/Keras: Recent Cleanlab releases removed the built-in
cleanlab.models.keraswrapper. If your stack is TF/Keras, migrate to PyTorch or a custom model wrapper (Cleanlab’s GitHub repository).- Snorkel — two distinct projects: The open-source
snorkellibrary (data programming, now effectively in maintenance) is not the same as the commercial Snorkel Flow platform. The weak-supervision concept is what transfers; verify which you’re adopting.
The Data Says
Perfect curation is not an engineering goal that’s merely hard — it’s one the statistics rule out. Major benchmarks carry single-digit-percent label errors, the best automated detectors are wrong about half the time they flag, and scale manufactures duplication faster than fuzzy matching can remove it. The mature move is to measure the error rate, model the noise, and spend verification where it changes outcomes — not to chase a zero that doesn’t exist.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors