Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Table of Contents
ELI5
Decoder-only models stripped half the original Transformer away — and that simplicity turned out to scale better with compute and data than the full encoder-decoder design ever could.
In 2017, Vaswani et al. published a Transformer Architecture with two symmetrical halves: an encoder that reads the entire input at once, a decoder that generates output token by token. By 2024, GPT-4o, Claude, Llama 3, and Gemini had all discarded the encoder entirely. The half that was responsible for understanding the input — the half designed to build rich, bidirectional representations — was the half the industry threw away.
That should feel like a mistake. And the fact that it doesn’t — that the research community accepted it with barely a shrug — is the anomaly worth examining.
Half a Transformer, All the Scale
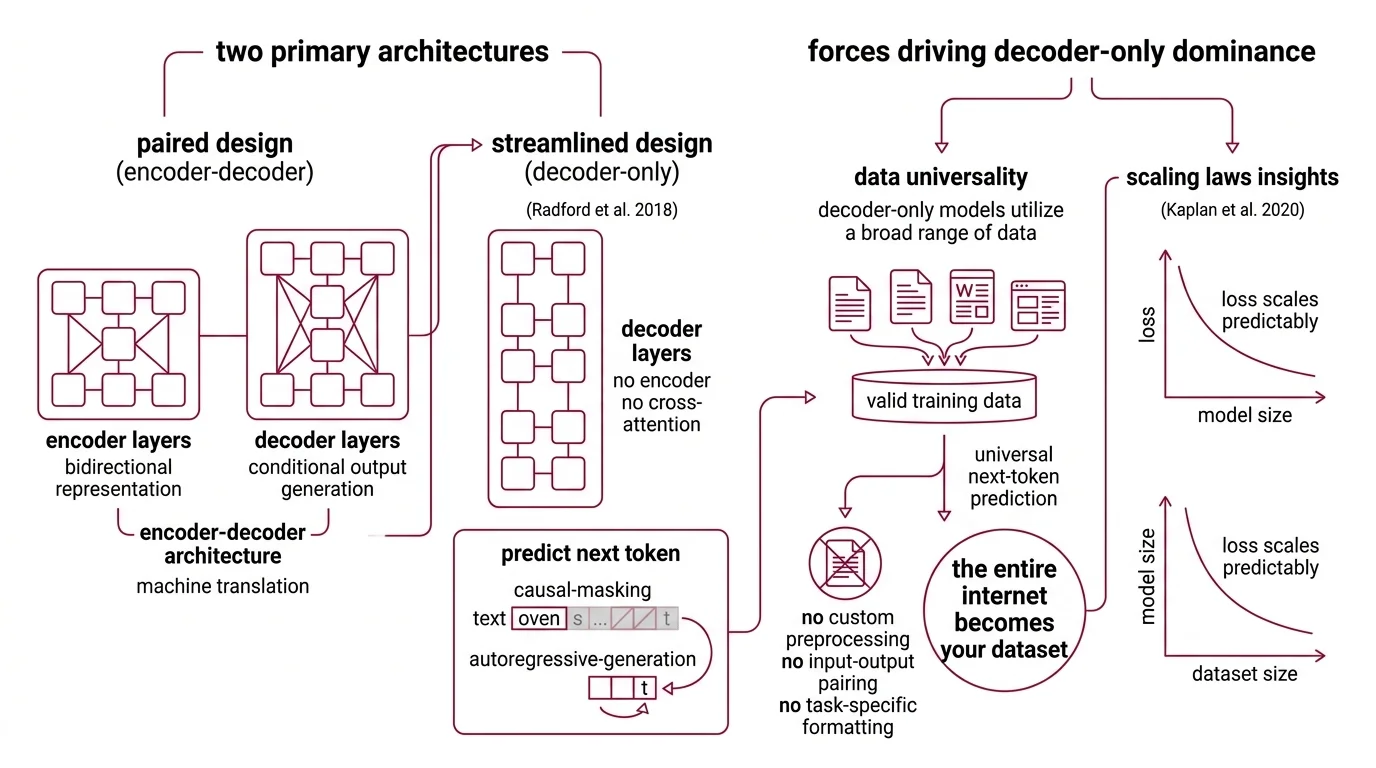
The original Transformer used a paired design: six encoder layers built a bidirectional representation of the input, six decoder layers generated the output conditioned on that representation. The Encoder Decoder Architecture made clean architectural sense for machine translation — one language in, another out. The encoder’s bidirectional Attention Mechanism could attend to every input token simultaneously. The decoder’s masked attention generated tokens strictly left to right, one at a time.
Then Radford et al. stripped the encoder out.
GPT-1, published in 2018, was a 12-layer Decoder Only Architecture with 117 million parameters, trained on a single objective: predict the next token. No encoder. No cross-attention between parameter spaces. Just Causal Masking and Autoregressive Generation — each token attending only to what came before it, each prediction feeding back as the input for the next.
It looked like a deliberate sacrifice of representational power.
It was an optimization that the next six years would vindicate.
Why did decoder-only architecture win over encoder-decoder for general-purpose LLMs?
Three forces converged to make the simpler architecture dominant.
The first is data universality. Encoder-decoder models expect paired inputs and outputs — a question and an answer, a source sentence and its translation. Decoder-only models treat any text as a sequence to continue. Every document, every transcript, every scraped web page becomes valid training data without custom preprocessing. When your training objective is next-token prediction, the entire internet becomes your dataset — no curation pipeline required, no input-output pairing logic, no task-specific formatting.
The second force is what Scaling Laws revealed. Kaplan et al. established in 2020 that loss scales as a power law with model size, dataset size, and compute — and that larger models are more sample-efficient, extracting more from fewer training examples. Hoffmann et al. sharpened this in 2022: a 70-billion-parameter model trained on 1.4 trillion tokens outperformed the 280-billion-parameter Gopher trained on fewer tokens (Hoffmann et al.). The lesson was not merely “bigger is better.” It was that model size and training data must scale in lockstep — and decoder-only architectures, with their simpler data pipeline and unified objective, could ingest more data at lower engineering cost than encoder-decoder alternatives.
The third force is architectural uniformity. An encoder-decoder model maintains two distinct parameter spaces connected by cross-attention layers. A decoder-only model has one repeating block type. Every engineering decision — parallelization strategy, memory optimization, gradient checkpointing — is simpler when you are stacking identical blocks rather than coordinating between two different kinds. At hundreds of billions of parameters, that simplification compounds into months of saved engineering time and more predictable training dynamics.
Not a theoretical preference. An engineering inevitability.
The question was whether that simplicity would survive the demands of scale — or fracture under them.
New Components, Same Skeleton
Simplicity won the scaling race. But simplicity at extreme scale creates its own pressure: attention computation grows quadratically with sequence length, key-value caches consume memory proportional to the number of attention heads, and routing all computation through every parameter becomes wasteful when different tokens need different kinds of expertise.
The response was not to abandon the skeleton. It was to extend it from within.
How do MoE layers, grouped-query attention, and multi-latent attention extend decoder-only design?
Mixture Of Experts layers replace the dense feed-forward network inside each transformer block with multiple parallel expert sub-networks and a learned routing function that directs each token to a subset of experts. Mixtral 8x7B uses 47 billion total parameters but activates only 13 billion per token through 8 experts with top-2 routing (Hugging Face Docs). Switch Transformers simplified this further to top-1 routing — a single expert per token — reducing inter-expert communication overhead while preserving quality.
The result: you scale the knowledge capacity of the model without proportionally scaling the compute each token requires.
Grouped-query attention addresses a different bottleneck. Standard multi-head attention stores separate key-value pairs for every head, and during long-context inference those KV caches dominate GPU memory. GQA introduces an intermediate design: query heads are organized into groups, each group sharing a single set of key-value heads — fewer KV heads than full multi-head attention, more than multi-query’s single shared set. Existing multi-head models can be uptrained to GQA using roughly 5% of the original pre-training compute (Ainslie et al.) — a fraction of the cost for a meaningful reduction in memory pressure.
Multi-latent attention, introduced in DeepSeek-V2, pushes compression further. Instead of storing full key-value states, MLA projects them into a low-dimensional latent space and reconstructs them at inference time. The numbers are stark: a 93.3% reduction in KV cache size and 5.76x throughput improvement, with 236 billion total parameters and 21 billion active per token (DeepSeek-V2 paper). DeepSeek-V3 extended this approach to 671 billion total parameters, combining MLA with MoE routing across 14.8 trillion training tokens (DeepSeek-V3 paper).
Every one of these innovations — MoE, GQA, MLA — preserves the decoder-only skeleton intact. The fundamental flow remains unchanged: tokens enter, causal masking enforces left-to-right attention, the next token is predicted. The modularity lives inside the blocks, not between them.
But what does that one-way gaze cost?
The Price of Looking Only Forward
Decoder-only dominance is so thorough that it is easy to forget the architecture carries a permanent structural constraint baked into every attention computation it performs.
What are the technical limitations of decoder-only models compared to encoder-decoder and encoder-only architectures?
Causal masking means every token attends only to tokens that precede it. The representation at position 50 contains zero information from position 51. For generation tasks — chatbots, code completion, open-ended writing — this is architecturally appropriate. The output flows forward, and left-to-right attention mirrors the production process.
But for tasks requiring full bidirectional understanding of a known input — classification, semantic similarity, structured extraction from existing documents — the one-way constraint is a genuine limitation. Encoder-only models like BERT, and the encoder half of encoder-decoder models like T5, process the entire input simultaneously. Every token’s representation is shaped by every other token. That bidirectional context is not a convenience; it is a mathematical property that changes the expressiveness of what the attention layers can encode.
There is a scale regime where this distinction matters acutely. A 2025 analysis by Zhang et al. found that while decoder-only models are more compute-optimal during pretraining, encoder-decoder architectures become competitive after fine-tuning and offer better inference efficiency for targeted tasks. Research on smaller models reinforces the pattern: for models under one billion parameters, an encoder-decoder split — two-thirds encoder, one-third decoder — can deliver up to 47% lower first-token latency and 3.9 to 4.7 times the throughput of decoder-only equivalents at the same parameter count.
The narrower and more structured the task, the less decoder-only generality helps — and the more you pay for the one-directional constraint.
When it breaks: decoder-only models waste compute on tasks where the full input is known before generation begins; every input token attends only left-to-right when bidirectional attention would extract richer representations from the same parameter budget.
The Data Says
The decoder-only architecture did not win on capability. It won on a training objective — predict the next token — that required no assumptions about task structure, no paired data, and no cross-attention routing between separate parameter spaces. Scaling laws rewarded that simplicity. Extensions like MoE, GQA, and MLA preserved the single-block skeleton while solving the bottlenecks that scale introduced. The half-Transformer won by doing less — then doing it at a scale the full architecture could not match.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors