Why Automated Red Teaming Misses What Humans Catch: Coverage Gaps and the Hard Limits of Adversarial Probing
Table of Contents
ELI5
Automated red teaming tests AI systems faster than humans, but it only searches where it already knows to look. The hardest-to-find failures live in spaces no one has mapped yet.
Here is a counterintuitive result: automated Red Teaming For AI outperforms human testing on raw success rate — 69.5% versus 47.6%, according to the Crucible Study. The tools find more bugs, faster, across a wider surface. And yet the failures that cause real damage — the ones that cascade through production systems and erode user trust — are disproportionately the kind automation never generates. The tools are exceptional at searching the territory. They are structurally blind to the territory that hasn’t been drawn.
The Geometry of a Search That Cannot Complete
Red teaming is often described as an adversarial exercise. That framing is accurate but incomplete. Beneath the adversarial language sits a search problem — and the constraint that defines Adversarial Attack testing is not difficulty but dimensionality.
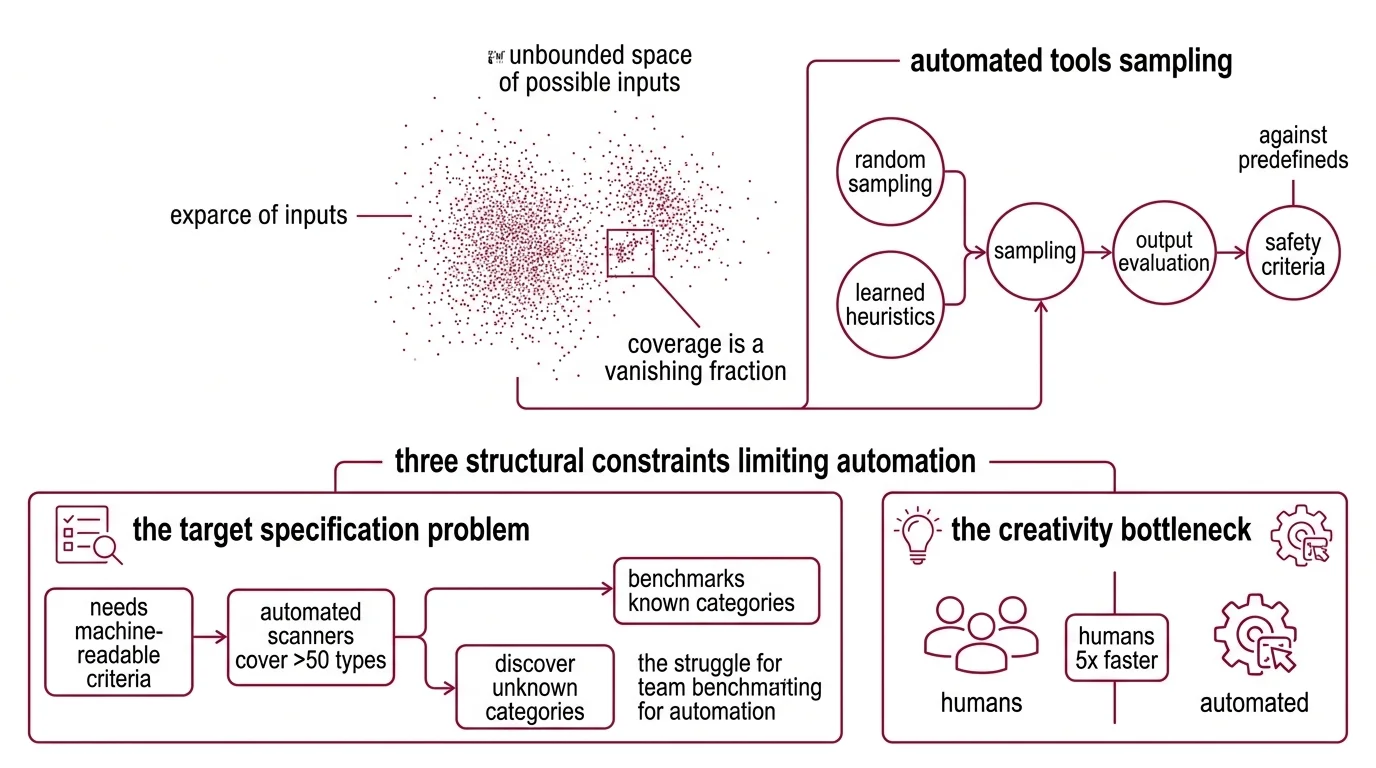
An LLM accepts arbitrary natural-language input. The space of possible inputs is not merely large; it is unbounded. Every combination of tokens, every multi-turn conversational trajectory, every encoding of context and persona and instruction represents a point in a space that no algorithm can fully enumerate. Automated tools work by sampling from this space — randomly or according to learned heuristics — and evaluating whether the outputs violate predefined safety criteria.
The sampling is fast. But the coverage is always a vanishing fraction of the whole.
What are the technical limitations of automated AI red teaming?
Three structural constraints limit what automation can find.
The target specification problem. Automated scanners need machine-readable criteria for what counts as a failure. Tools like Promptfoo cover over fifty vulnerability types — Prompt Injection, Jailbreak, PII leakage, Hallucination, authorization bypass — and they do it with real breadth. But the failure modes that matter most in practice often don’t fit predefined categories. Microsoft’s red team, after testing a hundred generative AI products, concluded that “AI red teaming is not safety benchmarking” — the two activities sound similar but measure fundamentally different things (Microsoft Research). A benchmark tests known categories. Red teaming is supposed to discover unknown ones.
Automation excels at the first. It struggles, structurally, with the second.
The creativity bottleneck. When humans succeed at creative attack scenarios, they do so roughly five times faster than automated approaches in comparable conditions (Crucible Study). That asymmetry is worth sitting with. The automated system runs more trials, generates broader coverage within the known attack surface, and wins on volume. But the human tester — the one who spends over a hundred hours interacting with the model in a specific domain (Anthropic Blog) — occasionally constructs an attack path that exists in no taxonomy and matches no existing template.
Role-play attacks succeed at a rate of 89.6% in adversarial evaluations under benchmark conditions (Mindgard). Multi-turn jailbreak sequences reach 97% average success within five conversational turns — though this figure reflects controlled benchmark conditions, not necessarily production-hardened systems with layered defenses (Mindgard). Notice the pattern: the high-success attacks are the ones that have already been characterized, measured, and taxonomized. The dangerous unknown is the attack path that doesn’t yet appear in any dataset.
The defense co-adaptation trap. Adaptive attacks specifically engineered to circumvent defenses bypass over 90% of published defense mechanisms — a result demonstrated against twelve separate published approaches under laboratory conditions where the attacker was optimized per defense (VentureBeat). This sounds like evidence that defenses don’t work. It is actually evidence of something subtler: the relationship between attack and defense is co-evolutionary. Each new defense creates the search gradient for the next attack. Automated tools accelerate this cycle, but they don’t escape it. They find what the current defense generation fails to block. They do not predict what the next generation of attacks will look like.
The Incompleteness Beneath the Coverage Report
If automation finds more vulnerabilities — 37% more unique findings than manual efforts alone, across aggregated benchmarks — why isn’t the answer simply to run more automated tests?
Because the gap is not quantitative. It is structural.
Why can’t red teaming guarantee that an AI model is safe?
The impossibility is not a matter of resources or time. It is a consequence of the search space geometry.
Consider the input space of a model that accepts arbitrary-length text. The number of possible inputs exceeds the number of atoms in the observable universe by a margin so large that the comparison itself becomes meaningless. No testing regime — automated or human — can sample more than a vanishing fraction of this space. Safety testing, therefore, is always a probabilistic statement: “we searched N points and found (or didn’t find) failures.” It is never: “we verified all points and none failed.”
Not a resource limitation. A mathematical ceiling.
The Anthropic team documented another dimension of incompleteness — a linguistic and cultural one. The majority of red teaming efforts are conducted in English, from a US-centric perspective (Anthropic Blog). Vulnerabilities that emerge in other languages, cultural contexts, or regional norms are systematically under-tested. An automated scanner generating adversarial prompts in English is not merely missing translations; it is missing entire categories of harm that are culturally constituted — harms that wouldn’t even register as failures under the default taxonomy.
The NIST AI Risk Management Framework and MITRE ATLAS — with its fifteen tactics and sixty-six techniques, expanded in January 2026 with five agentic AI attack patterns — provide structured taxonomies for known threats. OWASP’s Top 10 for LLM Applications (v2025) ranks prompt injection as the number-one risk and has added new entries for vector and embedding weaknesses. These frameworks are essential precisely because they codify what has already been discovered. But codified knowledge is the part of the problem that is no longer the hard part.
The hard part is what sits in the spaces between the taxonomies.
What the Coverage Asymmetry Predicts
If automated red teaming covers more known territory and humans discover more unknown territory, the practical implication is neither “automate everything” nor “hire more humans.” It is that the two methods have complementary blind spots that neither alone can fill.
Automated scanning — including tools like Promptfoo, which covers fifty-plus vulnerability types and remains open-source under MIT license following its acquisition by OpenAI in March 2026 — is well-suited for regression testing, known-category detection, and continuous integration of security checks. It belongs in every pipeline that touches an LLM.
Security & compatibility note:
- Promptfoo (OpenAI acquisition): Acquired March 16, 2026. Currently MIT-licensed and open source. Long-term licensing and feature direction under OpenAI ownership remain uncertain (AppSec Santa).
But if you rely only on automation, you will accumulate a growing inventory of “passed” vulnerability scans while the attack surface that matters — the part defined by human creativity, cultural context, and cross-domain reasoning — remains untested. Only about a quarter of organizations currently conduct proactive AI security testing of any kind (Mindgard). That number implies most systems in production have not been red teamed at all — not poorly, not insufficiently, but not at all.
The coverage gap starts before the first scanner runs.
If you increase automated test volume without expanding the diversity of human testers, expect diminishing returns on novel discovery. If you invest in human red teaming without structuring it around domain-specific threat models, expect inconsistency. And if you treat a clean scan as evidence of safety — rather than as evidence that known categories were checked — expect the kind of surprise that makes incident reports.
Rule of thumb: Automated scans tell you what you already knew to test for. Human red teaming tells you what you didn’t know to test for. Neither tells you what remains untested.
When it breaks: Red teaming — automated or human — fails silently when the threat model is incomplete. If the taxonomy used to define “failure” doesn’t include the actual failure mode, no amount of testing will find it. The most dangerous vulnerabilities are the ones that pass every check because no check was designed to look for them.
The Data Says
The data describes a coverage asymmetry, not a coverage hierarchy. Automated red teaming finds more of what it knows to look for — faster and at scale. Human red teaming finds what nobody knew to look for — but slowly, expensively, and with no guarantee of consistency. Neither method can certify safety because the input space is infinite and the failure taxonomy is always incomplete. The honest engineering position is not “test more” but “test differently — and never mistake a passed scan for proof.”
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors