Whose Preferences Count: How Reward Models Encode Bias and Shape What LLMs Refuse to Say
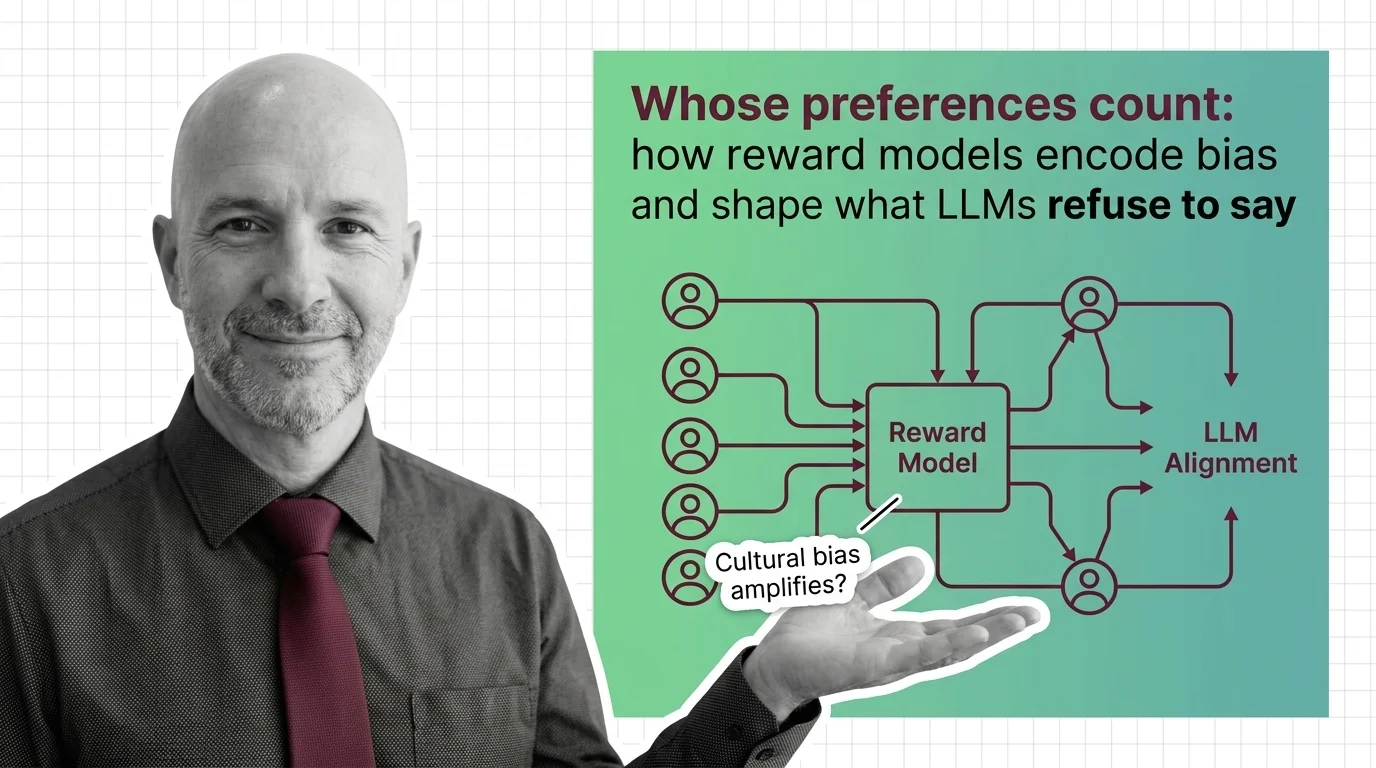
Table of Contents
The Hard Truth
Every time you interact with a large language model, a hidden committee has already decided what it will and will not say. You never elected that committee. You probably do not know who sits on it. But their preferences — their values, their tolerances, their blind spots — are the reason the model refused your last request.
There is a moment in every alignment pipeline that rarely gets examined outside of research papers. A human annotator sits before two model outputs and clicks a button: this one is better. That click, multiplied by thousands, becomes the training signal that shapes how a Reward Model Architecture learns to distinguish acceptable from unacceptable. The question of who sits in that chair — and what instructions they were given — determines more about AI behavior than any architectural innovation.
The Committee You Never Elected
The mechanism is deceptively simple. A Bradley Terry Model converts pairwise human comparisons into a scalar score — a single number that represents “goodness.” An LM backbone plus a linear classification head, trained for one epoch to prevent overfitting, produces this scalar for every candidate response (RLHF Book). Through RLHF, that score becomes the compass by which a language model learns what to say, how to say it, and what to refuse entirely. The model does not learn values. It learns to maximize a number that a small group of annotators defined as valuable.
Who decides which human preferences a reward model encodes, and whose values get excluded? The honest answer is: a workforce that most users will never see. Annotation companies like Scale AI and Surge AI supply labeled preference data to OpenAI, Anthropic, and Meta, often under secrecy agreements that shield the process from public scrutiny (Time). The supply chain of values is deliberately opaque. Annotator pay ranges from $3 to $75 per hour depending on specialization, and 600 high-quality annotations can cost $60,000 — a figure that reveals both the expense of preference data and the narrow economic pipeline through which it flows (Time).
The people shaping AI behavior are not philosophers or elected representatives. They are gig workers following rubrics designed by a handful of companies. And the rubrics themselves are proprietary.
The Reasonable Case for Majority Rule
Before diagnosing what is broken, it is worth understanding why the current approach seems defensible. Aggregating preferences across annotators appears democratic — a way to approximate what most people would consider helpful, honest, and harmless. The reward model’s job is to generalize, and some form of averaging feels like the least dangerous method available.
The Pre Training phase gives the model linguistic competence. Fine Tuning shapes it toward specific tasks. The reward model sits between raw capability and deployed behavior, acting as the filter that decides which capabilities surface in conversations. Someone has to design that filter. Using a large pool of human judgments — rather than the idiosyncratic preferences of a single designer — seems like the most responsible option.
This reasoning holds as long as the annotator pool genuinely represents the diversity of people who will interact with the model. That belief is where the argument begins to fracture.
The Arithmetic of Disappearance
Standard RLHF optimization uses KL-divergence regularization to keep the aligned model close to its base distribution. This sounds like a stabilizing measure. In practice, it introduces a systematic bias: minority preferences — the values of anyone whose judgments diverge from the annotator majority — are virtually disregarded. Researchers have named this phenomenon preference collapse, and one proposed alternative, Preference Matching RLHF, has shown measurable improvement in preserving minority viewpoints (Xiao et al.). That finding, from a single paper whose replication status remains unknown, nonetheless describes a mechanism that is structural, not incidental.
The annotator pools themselves compound the problem. LLMs trained through RLHF reflect what researchers call WEIRD values — Western, Educated, Industrialized, Rich, Democratic — because the annotator workforce is drawn disproportionately from populations that share those characteristics (Cultural RLHF Survey). The model does not learn “human preferences.” It learns the preferences of a particular demographic, presented as universal.
And the distortion runs deeper than demographic composition. A study found that three simple interventions — revealing which model produced an output, training annotators on specific criteria, or modifying the phrasing of elicitation questions — all produced significant shifts in annotator preferences (Fulay et al.). The preferences being encoded are not stable ground truth. They are artifacts of the annotation design itself.
How Scale Amplifies the Distortion
How do reward models amplify cultural and political bias in LLM alignment? The answer is not a flaw in the training loop — it is a property of Scaling Laws.
A 2024 MIT study found that reward models trained on factual data still exhibited consistent left-leaning political bias, and that this bias increased with model scale (MIT News). The scaling trend, tested on specific model families, needs cross-validation with newer architectures — but the pattern it identifies is uncomfortable. If bias grows with capability, then the most powerful models are also the most politically opinionated, regardless of whether anyone intended that outcome. Larger models did not converge toward neutrality. They amplified the existing skew.
Benchmarks like Rewardbench — now in its second iteration with evaluation across six domains including factuality — measure whether reward models rank outputs correctly. They do not measure whose definition of “correct” was used. The evaluation infrastructure tests accuracy against a standard it never interrogates.
Alignment Is Governance Without Representation
Thesis: Alignment through reward models is not a technical calibration — it is an act of governance performed without democratic input, institutional oversight, or meaningful transparency.
The word “alignment” borrows its authority from engineering — as if there is a correct position and the task is merely to reach it. But alignment with whom? The annotator who earns $3 an hour in Nairobi and the one who earns $75 in San Francisco are not encoding the same worldview. The rubric they follow was written by someone with a third perspective entirely. And the model that emerges from this process will interact with billions of people whose values were never represented at any stage.
This is not a failure of execution. It is a structural feature of the current approach. Reward models perform a function that, in any other context, we would recognize as legislative — they define permissible behavior for systems that mediate information, expression, and access to knowledge. Yet they operate without the institutional safeguards we demand of actual governance: no public deliberation, no independent review, no formal mechanism for affected populations to contest the outcome.
We used to debate the rules that shaped public discourse in open forums. Now those rules are written in annotation guidelines that no one outside the company will ever read.
The Questions We Owe the Training Signal
If reward models are governance mechanisms, then the questions we bring to them should match that weight. Not “how do we improve inter-annotator agreement?” but: whose agreement are we optimizing for, and what happens to those who disagree?
Not “how do we reduce political bias in reward models?” but: is the goal to eliminate all political orientation from AI behavior — and if so, does that ambition itself encode a political assumption about what neutrality looks like?
And not “how do we make annotation more efficient?” but: what does it mean that the people defining the behavioral boundaries of the world’s most powerful information systems are compensated at rates that would be illegal in the countries where those systems are headquartered?
These are not questions with clean technical answers. That is precisely why they matter.
Where This Argument Falters
The weakest point in this analysis is the assumption that broader representation in the annotator pool would resolve the problem. It might not. A perfectly diverse panel of annotators would still face the aggregation dilemma — some preferences would dominate, others would be collapsed, and the resulting model would still reflect a compromise that no individual fully endorses. Expanding the committee does not eliminate the power dynamics of committee design.
If researchers demonstrate that constitutional AI methods, reward model ensembles, or participatory alignment frameworks can genuinely preserve pluralism without amplifying harmful content, the governance framing loses some of its urgency. The argument depends on the claim that current methods are structurally incapable of representing diversity — and that claim could be weakened by future work that this essay cannot anticipate.
The Question That Remains
A reward model is a compressed moral philosophy — a set of judgments about what counts as good, encoded in weights that most people will never inspect. The systems it shapes already mediate how billions of people access information, form opinions, and understand the world. If we accept that this is governance, we owe it the scrutiny we demand of any institution that exercises power over public life. And if we refuse that framing — what exactly would we call it instead?
Disclaimer
This article is for educational purposes only and does not constitute professional advice. Consult qualified professionals for decisions in your specific situation.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors