Whose Knowledge Gets Retrieved: Bias and Accountability in RAG
The Hard Truth
What if every authoritative answer your RAG system produces is also an editorial decision — made by someone you cannot name, in a process you cannot audit, on behalf of voices it has chosen, in advance, to forget?
There is a comforting story we tell ourselves about retrieval-augmented generation: that grounding a model in retrieved documents makes it more honest, more accountable, more like a careful librarian than a confident oracle. The story is half-true. The other half — the half we rarely discuss — is that retrieval is also a curation act, and curation at scale is governance.
The Editor We Forgot to Hire
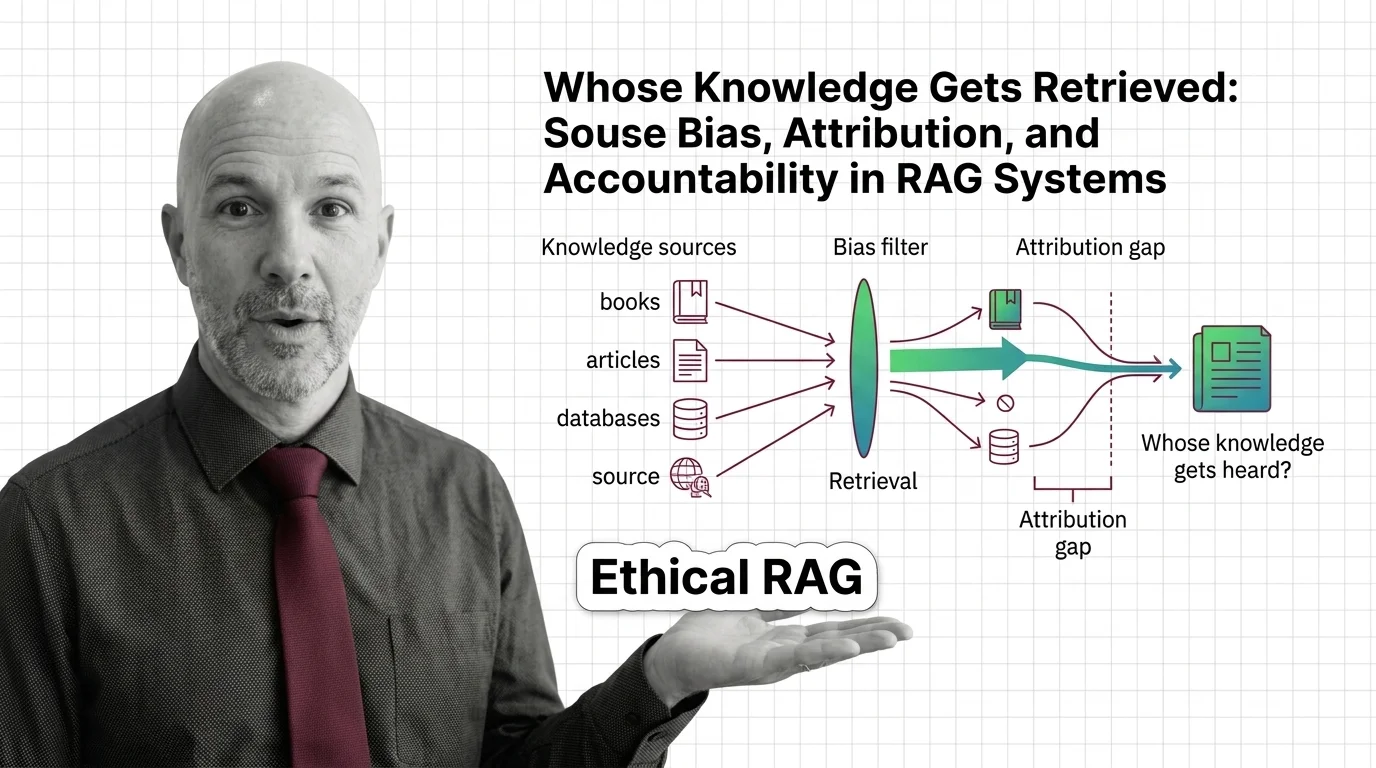
The ethical concerns with retrieval-augmented generation are usually framed as a technical accuracy problem. Did the model hallucinate? Did the citation point to a real document? Did the chunking lose context? These are real questions, and they matter. But they obscure a deeper one: who decided which documents belong in the corpus at all, and who decided how they would be ranked, weighted, retrieved, and surfaced as authoritative?
Every RAG system has an editor. Most have several. They sit inside the document selection policy, inside the chunking strategy, inside the embedding model’s training distribution, inside the reranker’s preferences. We just rarely call them editors, because acknowledging that role would make their decisions visible — and visibility implies accountability.
This isn’t paranoia. It is a description of how the technology actually works.
The Case for Retrieval as Honesty
Let me steelman the optimistic view, because it deserves a fair hearing. A Retrieval Augmented Generation pipeline, properly built, is a profound improvement over a sealed-up language model trained once and frozen forever. It can ground answers in a defined corpus, expose its sources, allow domain experts to update knowledge without retraining, and offer an audit trail that purely generative systems cannot.
Tools have started to make this concrete. LlamaIndex ships a citation engine that emits in-line references back to the retrieved nodes. LangChain provides similar primitives. Vector stores like Pinecone let teams version their corpus. Rerankers such as Cohere Rerank promise to push the most relevant material to the top. Hybrid Search combines lexical and semantic signals, and Agentic RAG lets the system decide for itself which sources to consult next. On paper, this looks like the most transparent moment in the history of consumer information retrieval.
That is the strongest version of the case. Now let me say what it leaves out.
The Hidden Assumption Inside Every Citation
The assumption underneath every citation is that the corpus is neutral — that if the documents are real and the retrieval is technically correct, the answer inherits the legitimacy of its sources. The corpus is never neutral. It is a series of decisions: about what to crawl, what to license, what to exclude, how to apply a Chunking Strategy, which embedder to fine-tune on which documents. Each of those decisions is a political act, even when nobody intends it as one.
The empirical evidence is sobering. Adding authorship metadata to source documents shifts attribution quality between 3% and 18% across three evaluated models, depending on the names involved (Abolghasemi et al., ACL 2025). A separate analysis of burn-management literature showed that RAG outputs systematically over-weight highly-cited studies and under-retrieve less-cited but valid sources (PMC 2025). The system isn’t just summarizing knowledge; it is reproducing — and amplifying — the existing hierarchy of who already gets cited.
Then there is the security layer, which has begun to dismantle whatever was left of the “corpus is safe by default” framing. Injecting only five malicious texts into a corpus of millions can drive an attack success rate around 90% on targeted questions (PoisonedRAG, USENIX Security 2025). A follow-up paper, CorruptRAG, reduces that requirement to a single poisoned document per target query. OWASP now classifies these problems as LLM08:2025 “Vector and Embedding Weaknesses,” covering data poisoning, embedding inversion, and cross-tenant leakage as a single category of risk.
If the corpus can be silently rewritten by anyone with upload access, what exactly does the citation guarantee?
What Library Science Knew Before We Forgot It
We are not the first generation to face these questions. Library science wrestled with them for over a century before software ate the catalog. Cataloguers debated whose names belonged on the spine, which subjects deserved their own headings, which works counted as “literature” and which got filed under “popular.” These were technical-looking decisions that turned out to be deeply political. The Dewey Decimal system, for most of its history, filed entire civilizations under categories chosen by one nineteenth-century American librarian’s worldview. Generations of scholars spent careers arguing over what those choices were doing to readers.
Retrieval engineers have inherited the same problem under a different name. The corpus is the catalog. The embedder is the indexer. The reranker is the librarian who decides which book ends up on the recommendations table at the front of the store. The difference is that nobody has yet built — or even seriously demanded — the institutional review process that library science eventually grew around its own decisions. We are running cataloguing operations at planetary scale, and we are doing it without librarians, without standards bodies, without ombudsmen, and largely without records of who decided what.
The Quiet Politics of the Index
A retrieval system is an editorial institution that has not yet admitted to being one — and the gap between what it does and what it acknowledges is where accountability disappears.
Source bias and attribution gaps shape who gets heard in RAG outputs because the system, by design, treats retrieval as a value-neutral lookup when it is actually a chain of value-laden choices. The embedder learned its similarity geometry from a particular distribution of text. The reranker was tuned against a particular notion of relevance. The corpus reflects whoever could afford to license, scrape, or own the underlying material. By the time the model writes its first sentence, three or four editorial decisions have already been made — and none of them appear in the citation footer.
The legal system has begun to notice. Advance Local Media v. Cohere, filed by fourteen publishers in February 2025, alleges unlicensed copying for training the Command model family. The more striking development is that NYT v. Perplexity (filed December 2025) and Britannica & Merriam-Webster v. OpenAI (filed March 2026) cite real-time RAG retrieval itself as the infringing mechanism, distinct from training-data claims (Copyright Alliance 2025 review). The Bartz v. Anthropic settlement, at $1.5 billion in 2025, suggests how seriously courts are starting to weigh adjacent questions. Whether or not those cases ultimately succeed in court — and the outcomes remain open — they mark a shift. The catalog has become contested ground.
What We Owe the People Whose Voices Pass Through the Pipeline
Regulators are not silent on this either. NIST’s Generative AI Profile, published July 26, 2024 and updated in March 2025, names data integrity and third-party model provenance as core risks — language that maps almost cleanly onto RAG corpus governance (NIST AI RMF). The EU AI Act’s Article 50 disclosure obligations become enforceable on August 2, 2026, and the first Draft Code of Practice on Transparency of AI-Generated Content was published December 17, 2025 (European Commission). These frameworks signal an emerging consensus that the people whose voices are pulled through retrieval pipelines have some claim — moral, if not yet legal — to know that this is happening.
The harder questions are not regulatory. They are editorial. Who curates the corpus? Who audits the embedder? Who has the authority to remove a poisoned document, or to add a marginalized voice that the citation graph never amplified? Research on bias-aware embedders has shown that controlled fine-tuning can mitigate overall RAG bias while preserving retrieval utility. The mechanism exists. The institution to wield it does not.
Where This Argument Is Weakest
I should be honest about where this position could be wrong. It is possible that retrieval-augmented systems, precisely because they make sources visible, will turn out to be more auditable than the closed-book models that came before them. It is possible that the same techniques used to demonstrate poisoning will be used to detect it at scale. It is possible that pluralistic corpora — assembled by communities rather than vendors — emerge as a counterweight, and that the tooling to assemble them becomes good enough to matter. If those things happen, retrieval becomes the most honest information layer we have ever built. I would be glad to be wrong in that direction.
What would change my mind: a verifiable, third-party audit regime for RAG corpora, comparable to financial auditing, with enforcement teeth. Until then, the editorial layer remains invisible. And invisible editors do not answer to anyone.
The Question That Remains
If retrieval is the new catalog, and the catalog is the new policy, then the most consequential editorial decisions of this decade are being made by teams that do not consider themselves editors — for readers who do not know the editors exist. Who, then, is accountable when the answer that sounds most authoritative is also the answer the system was quietly trained to prefer?
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors