Whose Data Gets Cleaned Away: Bias, Erasure, and Accountability in Preprocessing Decisions
The Hard Truth
Before a model learns anything, someone decides which records are worth keeping. A row gets dropped because a field is blank, a category gets merged because it was inconvenient, an outlier gets smoothed because it looked like noise. We call this cleaning. But what if the dirt we wipe away is a person?
Long before the first epoch of training, a quieter decision has already been made. Someone — or some default setting — has chosen whose data is complete enough to count and whose is too messy to bother with. We treat Data Preprocessing as plumbing, the unglamorous work that happens before the real intelligence begins. But plumbing decides where the water goes, and who never gets any.
The Janitor Nobody Watches
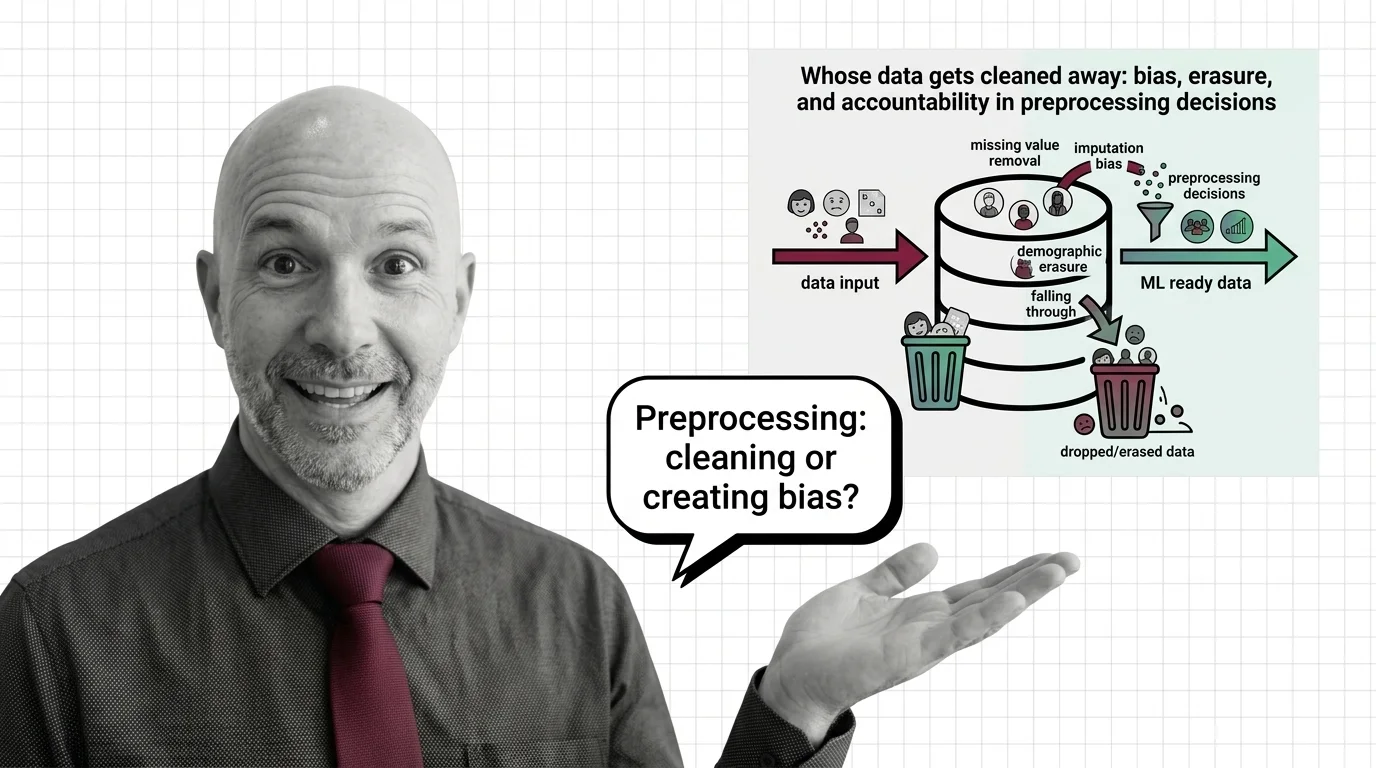
Every dataset arrives broken. Fields are empty, formats clash, the same city is spelled four different ways. Cleaning it is not optional — a model trained on chaos produces chaos. So we hand the work to a stage we barely name, a series of transformations that turn raw records into tidy matrices. And because the work looks janitorial, we assume it is neutral. Mops don’t have politics.
Yet the janitor decides what stays on the floor. When a practitioner drops every row with a missing value, applies Feature Scaling to compress the extremes, or collapses rare categories into an “other” bucket through Categorical Encoding, they are not just tidying. They are deciding which slices of human reality the model will ever be allowed to see. Who watches that decision? And who would even think to?
The Case for a Clean Dataset
Let me give the conventional view its strongest form, because it is not foolish. A model is only as trustworthy as the data beneath it, and incomplete records genuinely degrade performance. Missing Data Imputation can introduce its own artifacts; a guessed value pretending to be a measured one is a kind of lie. Faced with a column that is forty percent blank, dropping those rows is defensible, even responsible. It keeps the analysis honest about what was actually observed.
The same logic runs through the whole preprocessing pipeline. We apply Normalization and Standardization so that no single feature dominates by accident of its units. We use One Hot Encoding to make categories legible to math. We guard the Train Test Split against Data Leakage so our evaluation means something. Each step has a textbook justification, and a competent engineer can defend every one. The conventional wisdom is not careless. That is exactly what makes it dangerous.
What “Missing” Actually Means
Here is the assumption buried inside all of it: that a missing value is missing at random — a coin flip, a clerical accident, statistical noise with no pattern and no victim. Strip that assumption away and the floor tilts.
Missingness is rarely random. The propensity for a value to be absent is tied to who the person is, research on missing-data mechanisms suggests (arXiv 2503.07313). The people whose records are incomplete are disproportionately the people the system already understands least — those who moved often, worked informally, fell outside the categories the form anticipated. When you delete rows with missing values, you are not removing noise evenly across the population. You are removing the population that was hardest to record in the first place.
The fairness literature makes this concrete. Minority groups frequently carry more missing values, so listwise deletion shrinks their representation in the surviving data, work by Biswas and Rajan finds (arXiv, Biswas & Rajan). The model then learns a world in which those people are rarer than they are — or absent entirely. Dropping a row is not a statistical act; it is a demographic one. So the harder question — is discarding incomplete records an ethical choice or silent discrimination — answers itself uncomfortably. It is silent precisely because it leaves no trace in the metrics we usually check.
A Census, Not a Spreadsheet
We would understand this instantly if we stopped calling it data and called it what it is: a census. Every state that ever counted its people faced the same temptation — to omit the population that was difficult to reach, expensive to enumerate, inconvenient to classify. And every time a census undercounted the poor or the migrant or the marginal, the consequence was not a rounding error. It was a redistribution of attention, funding, and political weight away from people who were already short of all three.
A dataset is a census of whatever world it claims to describe. Feature Engineering is the act of deciding which human attributes become visible to the system and which dissolve into the background. When imputation strategies fill gaps using group averages, they can quietly flatten the very differences that mattered, aggravating inequities through group-specific missingness, research published in JAIR shows. The model does not see people. It sees the census we handed it — and it will govern accordingly, with all the authority of mathematics and none of the doubt.
The Erasure Is the Decision
Thesis: Preprocessing is not preparation for an ethical decision — it is the ethical decision, made before anyone is watching and recorded nowhere a reviewer would look.
We comfort ourselves with the idea that fairness gets handled later, in model selection, in fairness audits, in the careful tuning of thresholds. But by the time those tools run, the erased are already gone. You cannot audit for the absence of people your preprocessing pipeline removed three steps upstream. The bias did not enter the model through the algorithm; it entered through the broom. And because each cleaning step was individually reasonable, the accumulated harm has no author. The engineer followed best practice. The library used its default. The reviewer checked the accuracy. Everyone behaved responsibly, and someone still disappeared. When the harm has no author, who answers for it?
The Questions We Owe the Deleted
I won’t pretend there is a checklist that dissolves this. But there are questions worth sitting with before the next dataset is scrubbed. Who is in the rows we are about to drop, and does their missingness have a pattern? If we imputed instead of deleted, whose reality would we be guessing at, and is a careful guess more honest than a clean absence? When we collapse rare categories, are we simplifying the math or erasing the minority? And who, in the end, gets to see the record of what was removed — or is that record never written at all?
These are not engineering questions. They are questions about whose existence the system is obligated to acknowledge. The tools have improved — pandas reached its 3.0 line in early 2026, polars matured alongside it — and they make the cleaning faster and more reproducible than ever. But speed is not conscience. A pipeline that erases people more efficiently is still a pipeline that erases people.
Where This Argument Could Break
I should name where I might be wrong. If a column’s missingness were genuinely random — truly unrelated to who anyone is — then dropping those rows would harm no group in particular, and my alarm would be misplaced. And there are real cases where imputation does more damage than deletion, where a fabricated value misleads more than an honest gap. If practitioners began documenting missingness patterns and testing them against protected attributes as a matter of routine, the silent part of the discrimination would end, and much of my unease with it would too.
The Question That Remains
We have built an entire discipline around making data clean, and almost none around asking what cleanliness costs. The rows we delete don’t protest, don’t appear in the accuracy score, don’t haunt the dashboard. So here is what stays with me: if a person can be removed from the world a model learns, and no one is required to notice, were they ever really counted at all?
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors