Long-Context vs RAG vs Hybrid: A 2026 Decision Framework
Table of Contents
TL;DR
- Long-context wins when the answer needs the whole document and the workload is bursty or one-shot.
- RAG wins when the corpus is large, queries are frequent, and freshness or cost matter more than full-document reasoning.
- Hybrid is the production default — retrieve narrow, then hand a focused window to a 1M-token model with grounding checks.
A team I reviewed last week was paying about $1.60 per query to dump 800K tokens into Gemini 3.1 Pro for what turned out to be a single-paragraph lookup. P95 latency was 38 seconds. Recall was mediocre. Their vector index sat idle in the same VPC. They had picked the largest available context window because it felt simpler — no chunker, no retriever, no eval. It wasn’t simpler. It was just expensive in a different place.
This guide is the spec I gave them. It works for any team choosing between Long Context Vs RAG routes in 2026.
Before You Start
You’ll need:
- Access to a long-context model — Gemini 3.1 Pro Preview (1M tokens) or Claude Sonnet 4.6 / Opus 4.6 (1M tokens, GA since March 13, 2026, per Anthropic blog)
- A vector database — Pinecone Serverless is the assumed default in this guide
- A retrieval framework — LlamaIndex on the post-March 2026 Workflows API
- A clear picture of your corpus size, query rate, freshness requirements, and answer shape
This guide teaches you: how to decompose the long-context vs RAG question into four spec-able constraints — corpus, latency, cost, and grounding — and choose the right route before you write a line of pipeline code.
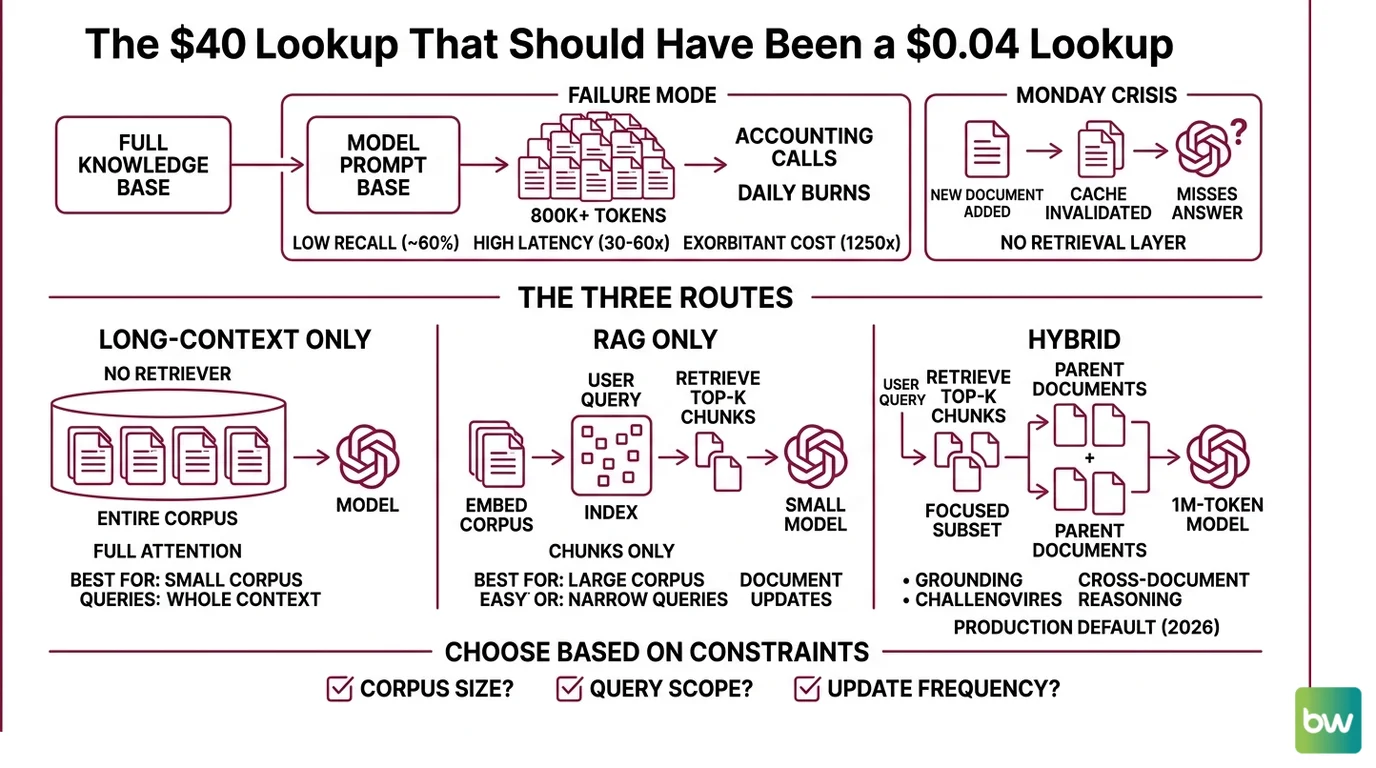
The $40 Lookup That Should Have Been a $0.04 Lookup
The failure mode is always the same. Someone reads about a 1M-token window, picks the model, and pipes the entire knowledge base into every prompt. Then accounting calls.
Gemini 3.1 Pro Preview costs $2.00 per million input tokens (Gemini API pricing page). Stuff 800K tokens in, run it 50 times a day, and you’ve burned $80 daily on context that the model is mostly ignoring. One 2026 production analysis measured average recall on multi-fact retrieval over million-token windows at roughly 60%, with latency 30–60× slower than RAG and per-query cost around 1,250× higher (TianPan.co decision framework). Those are illustrative ranges — but the direction is unambiguous.
Then Monday hits. Someone added a new document. The cache is gone. Your “stateless” prompt now misses the answer entirely because you never built a retrieval layer to keep up.
Step 1: Map the Three Routes
Before you pick a model, draw the routes on paper. There are three. Each has a different shape.
Your system has these parts:
- Long-context only — feed the model the entire document or corpus in the prompt. No retriever, no chunker. The model does its own attention. Best when the corpus is small enough to fit (under ~1M tokens) and every query genuinely needs the full context.
- RAG only — embed your corpus into a vector index, retrieve top-K chunks per query, send only those chunks to a small-context model. Best when the corpus is large, queries are narrow, and you need to swap or update documents without recomputing anything.
- Hybrid — retrieve a focused subset (top 20–50 chunks, ~50K tokens), then send that subset plus a few full parent documents to a 1M-token model. You still get grounding, but you also get cross-document reasoning. This is the production default in 2026.
The question isn’t “which is best?” It’s “which constraints does my workload actually have?” Answer that and the route picks itself.
The Architect’s Rule: If you can’t draw your data flow on a napkin in three boxes, the AI can’t build it either — and neither can the next engineer who inherits it.
Step 2: Lock Down the Constraints
Four constraints decide the route. Specify each one before you touch a config file. If you skip even one, the AI tool you ask to scaffold the pipeline will guess — and it will guess based on its training bias, not your workload.
Context spec checklist:
- Corpus size and shape — total tokens, number of documents, max document length, modalities (text, PDF, image, audio).
- Query rate — peak queries per second, daily total, burstiness pattern.
- Freshness window — how stale can answers be? Minutes? Hours? Days?
- Grounding requirement — does every claim need a citation back to a source span, or is “the model summarized your docs” good enough?
- Latency budget — P95 in seconds. A chatbot has a different budget than a nightly batch job.
- Cost ceiling — dollars per query, per day, or per user.
- Reasoning depth — does the answer need cross-document synthesis, or single-fact lookup?
The Spec Test: If your context doesn’t specify the freshness window, the AI will assume your corpus is static and skip the retriever entirely. Then your “RAG” pipeline turns into a long-context dump the second a doc updates.
A few practical heuristics for the constraints:
- Corpus under 500K tokens, queries rare, full-document reasoning required → long-context only. Pay the per-call cost. You don’t need infrastructure.
- Corpus over a few million tokens, queries frequent, narrow lookups → RAG only. The vector index is now your scaling layer.
- Anything in between, especially with mixed query types → hybrid. This is where most enterprise workloads land.
VentureBeat reported that enterprise intent to adopt hybrid retrieval rose from 10.3% to 33.3% in Q1 2026 — roughly tripling in a single quarter. Teams aren’t picking hybrid because it’s trendy. They’re picking it because pure long-context blew up their budgets and pure RAG hit recall ceilings on cross-document questions.
Step 3: Wire the Hybrid Pipeline
Pick the hybrid route — it’s the most general — and build the components in order. Each component must specify its inputs, outputs, and failure mode. If you skip the spec, the AI scaffolds something that runs but doesn’t behave.
Build order:
- Embedding + indexing layer first — because the retriever has nothing to retrieve until the index exists. Pick an embedding model, choose your chunk size (start at 512 tokens for general Q&A, larger for legal or long-form, smaller for FAQ-style content), and write the index to Pinecone Serverless. Specify the namespace strategy per tenant or per document type.
- Dense + sparse retrieval next — because reranking needs candidates. Run a dense vector query and a Sparse Retrieval BM25-style query in parallel, then fuse the results. Hybrid retrieval consistently beats either alone for keyword-heavy queries (product names, error codes, IDs).
- Reranker third — because top-K from retrieval is noisy. A cross-encoder reranker on the top 50 candidates returns the top 10–20 that actually deserve a slot in the prompt.
- Long-context generation last — because the model needs the focused context. Hand the reranked chunks plus 1–3 full parent documents to Claude Sonnet 4.6 or Gemini 3.1 Pro. Place the highest-relevance content at the start and the end of the prompt to counter middle-position degradation, a pattern documented by Maxim AI for “lost in the middle” mitigation.
For each component, your context must specify:
- What it receives (inputs and their schema)
- What it returns (outputs and their schema)
- What it must NOT do (no silent fallback to a different model, no swallowed errors)
- How it handles failure (retry policy, timeout, what to log)
A practical pattern from LlamaIndex: their official “Chunk + Document Hybrid Retrieval with Long-Context Embeddings” example indexes both whole-document and chunk embeddings, then reweights chunk similarity by parent-document similarity through an alpha parameter (LlamaIndex Docs). That’s the cleanest hybrid template I’ve seen — copy the structure, swap the embedding model and the index for your stack.
Security & compatibility notes:
- Gemini 2.5 Pro deprecation: Scheduled API deprecation June 17, 2026; Vertex AI retirement Oct 16, 2026. New code must target Gemini 3.1 Pro Preview or its successor (Google AI Developers Forum).
- Pinecone pod-based indexes: Legacy as of 2026. New indexes default to serverless. The console offers a free pod-to-serverless migration tool for indexes up to ~25M records and 20K namespaces (Pinecone Docs).
- LlamaIndex breaking changes (March 2026):
AgentRunner/AgentWorkerreplaced byAgentWorkflow;QueryPipelinereplaced by Workflows;LLMPredictordeprecated; Python 3.9 deprecated;llama-index-workflowsv2.0 is a breaking change. Pin versions and migrate before upgrading (LlamaIndex ChangeLog).
Step 4: Validate Recall and Cost
A pipeline that runs is not a pipeline that works. You validate two things separately: did the retriever surface the right chunks, and did the model use them correctly. RAG Evaluation treats these as distinct measurements — and you should too.
Validation checklist:
- Retrieval recall on a labeled set — failure looks like: the top-K never contains the gold chunk. Symptom: the model invents an answer or hedges.
- Faithfulness of the generated answer — failure looks like: the answer cites a chunk that doesn’t actually contain the claim. Symptom: hallucinations that look grounded.
- End-to-end answer correctness — failure looks like: retrieval recalled the right chunk, the model still answered wrong. Symptom: a reasoning gap, not a retrieval gap.
- Cost per query in production traffic, not staging — failure looks like: average tokens per call drifts up over time as your prompt template accretes context. Symptom: monthly bill outpaces query volume growth.
- P95 latency — failure looks like: cold-start spikes. Pinecone Serverless scales to zero, and third-party testing reports cold starts adding roughly 200 ms to 2 s on the first query after idle (Pecollective review). Warm a path before peak.
For grounding specifically, treat RAG Guardrails And Grounding as a hard contract: every generated claim must trace back to a retrieved span. If your evaluator can’t draw that line, the answer fails — even if a human would have accepted it.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| One-shot “use the 1M-token window for everything” | The model spends most of its attention on irrelevant context; cost and latency spike | Decompose by corpus size and query rate before picking a route |
| Skipped the freshness spec | Pipeline assumes static corpus; new documents never reach the model | State the freshness window in the context spec; choose RAG or hybrid if it’s under a day |
| Indexed without sparse retrieval | Keyword-exact queries (product names, error codes, IDs) miss | Add a sparse leg and fuse with dense scores |
| Pinned LlamaIndex without reading the changelog | Pipeline breaks on the next minor upgrade because AgentRunner is gone | Pin to a version, audit the March 2026 ChangeLog before bumping |
| Validated only end-to-end accuracy | Can’t tell if a wrong answer was a retrieval miss or a reasoning miss | Measure retrieval recall and answer faithfulness separately |
| Placed the most important chunk in the middle of the prompt | “Lost in the middle” degrades recall on long contexts | Put highest-relevance content at the start and end |
Pro Tip
Treat the long-context window as a generation surface, not a storage surface. Storage is what your vector index is for. The 1M-token window is where you assemble the focused, reranked, grounded context the model actually reasons over. The moment you start using the context window as cheap RAM, you’ve thrown away the architectural advantage of having a retriever in the first place.
Frequently Asked Questions
Q: When should you use long-context instead of RAG in 2026? A: Pick long-context only when the corpus genuinely fits (under ~1M tokens) and every query needs the full document — legal contracts, single-codebase reasoning, full-meeting transcripts. Watch out for bursty traffic: long-context cost scales linearly with calls, while a Pinecone Serverless index amortizes across queries once it’s warm.
Q: Which use cases favor RAG over million-token context windows? A: Customer-facing search, frequently-updated knowledge bases, and any workload where the corpus is larger than your context budget or needs sub-day freshness. Edge case: hybrid keyword + semantic queries (product SKUs, error codes) need a sparse leg in the retriever — pure dense embeddings will miss them at production scale.
Q: How to build a hybrid RAG plus long-context pipeline step by step in 2026? A: Index both chunks and parent documents, retrieve dense + sparse in parallel, rerank, then send the top 10–20 chunks plus 1–3 full parents to a 1M-token model. Watch out for prompt position: place highest-relevance content at the start and end, not the middle, to counter long-context attention drop-off.
Q: How to implement RAG-augmented long-context with LlamaIndex, Pinecone, and Claude 1M in 2026?
A: Use LlamaIndex’s chunk-plus-document hybrid retrieval template on the post-March 2026 Workflows API, store vectors in a Pinecone Serverless index, and route reranked context to Claude Sonnet 4.6 (1M GA, $3 in / $15 out per million tokens, flat across the full window per Anthropic blog). Avoid AgentRunner and QueryPipeline — both are gone.
Your Spec Artifact
By the end of this guide, you should have:
- A one-page route decision map showing which of the three routes (long-context, RAG, hybrid) your workload uses, with the deciding constraint named.
- A constraint contract listing your corpus size, query rate, freshness window, grounding requirement, latency budget, cost ceiling, and reasoning depth.
- A validation plan with separate gates for retrieval recall, answer faithfulness, end-to-end correctness, cost per query, and P95 latency.
Your Implementation Prompt
Drop this prompt into Claude Code, Cursor, or Codex when you’re ready to scaffold the pipeline. It encodes the four-step framework so the AI tool generates a spec-compliant skeleton instead of a generic RAG demo.
You are scaffolding a hybrid long-context + RAG pipeline. Follow this spec exactly.
ROUTE: hybrid (top-K retrieval + 1M-token generation)
CONSTRAINTS:
- Corpus size: [your total tokens]
- Query rate: [peak QPS, daily total]
- Freshness window: [minutes / hours / days]
- Grounding requirement: [every-claim-cited | summary-OK]
- Latency budget P95: [seconds]
- Cost ceiling per query: [dollars]
- Reasoning depth: [single-fact | cross-document]
COMPONENTS (build in this order):
1. Embedding + indexing layer
- Embedding model: [model name and dimensions]
- Chunk size: [tokens, default 512]
- Index: Pinecone Serverless, namespace strategy = [per-tenant | per-doctype]
2. Hybrid retrieval (dense + sparse)
- Dense: [embedding model] vector search
- Sparse: BM25 or equivalent
- Fusion: reciprocal rank fusion, top 50 candidates
3. Reranker
- Cross-encoder, top 10–20 output
4. Long-context generation
- Model: Claude Sonnet 4.6 (1M) or Gemini 3.1 Pro Preview
- Prompt layout: highest-relevance chunks at start AND end
- Include 1–3 full parent documents alongside chunks
VALIDATION GATES (each must pass):
- Retrieval recall on labeled set: [target %]
- Answer faithfulness on labeled set: [target %]
- End-to-end correctness: [target %]
- Cost per query in shadow traffic: under [dollars]
- P95 latency: under [seconds]
FAILURE BEHAVIOR: fail loud, log retrieval candidates and reranker scores, never fall back to a different model silently.
DEPRECATIONS TO AVOID: do not use Gemini 2.5 Pro (deprecating), Pinecone pod-based indexes (legacy), or LlamaIndex AgentRunner / QueryPipeline / LLMPredictor (removed March 2026).
Generate: project structure, component interfaces (typed), validation harness skeleton.
Do NOT generate: business logic, prompt templates beyond the layout rule, eval datasets.
Ship It
You now have a decision framework that turns “which model has the biggest context?” into “which constraints does my workload have?” Most production workloads are hybrid — accept that, build the retriever properly, treat the long-context window as a focused reasoning surface, and validate retrieval and reasoning as separate gates. The teams that win the cost war in 2026 aren’t the ones with the biggest prompts. They’re the ones with the tightest specs.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors