HyDE vs Multi-Query vs Step-Back: Choosing RAG Query Transforms
TL;DR
- The wrong query transformation costs you latency without buying recall — pick the one that matches your failure mode, not the trendy one.
- HyDE wants generic, exploratory queries. Multi-query wants ambiguity. Step-back wants over-specific facts. Decomposition wants compound questions. Routing wants multiple sources.
- In production, the choice should be made at runtime by an agent — not baked into the pipeline.
A team I worked with last quarter had stacked HyDE, multi-query rewriting, and a reranker on top of every retrieval call. Their p95 latency had tripled. Recall on the evaluation set had barely moved. They were paying for three transformations and getting the value of none.
The fix wasn’t a better library. It was a decision tree. Each transformation solves a specific class of query failure. Use the wrong one and you add overhead. Use the right one and the retriever stops missing.
Before You Start
You’ll need:
- A working Retrieval Augmented Generation pipeline you can swap retrievers in and out of (LlamaIndex or LangChain v1 are the easy paths).
- Understanding of Query Transformation as a category — and why dense retrieval misses on certain query shapes.
- A held-out evaluation set of real user queries with known relevant documents. Without one, you cannot tell which transformation is helping versus hurting.
This guide teaches you: how to map your retrieval failures to a specific query transformation rather than stacking everything and hoping recall climbs.
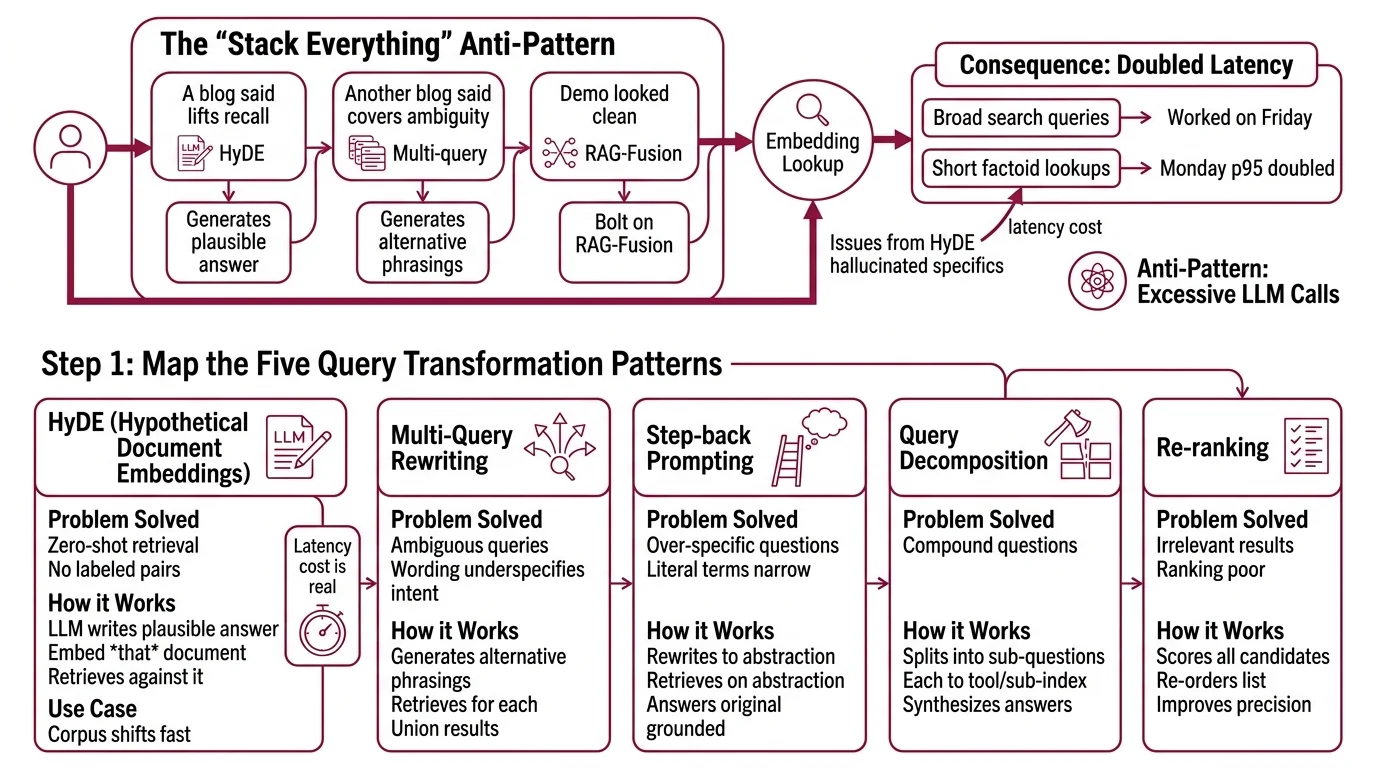
The “Stack Everything” Anti-Pattern
You wire HyDE in front of your retriever because a blog said it lifts recall. You add a multi-query rewriter because another blog said it covers ambiguity. You bolt on RAG-Fusion because the demo looked clean. Now every user query fires several LLM calls before a single embedding lookup.
It worked on Friday. On Monday, p95 latency doubled because traffic shifted from broad search queries to short factoid lookups — exactly the queries where HyDE generates hallucinated specifics that the encoder still has to filter out.
Step 1: Map the Five Query Transformation Patterns
Before you pick anything, name the five patterns and what each one solves. Mixing them up is the most common failure mode I see.
Your transformation toolbox has these parts:
- HyDE (Hypothetical Document Embeddings) — the LLM writes a plausible answer document, you embed that document, then retrieve against it. Best for zero-shot or low-supervision domains where you have no labeled query–document pairs and the corpus shifts faster than you can fine-tune. Per the HyDE paper, the encoder filters most hallucinated specifics, but the latency cost is real.
- Multi-query rewriting — the LLM generates several alternative phrasings of the user’s question, you retrieve for each, you union the results. LangChain’s
MultiQueryRetrieverdefaults to three rewrites (LangChain Reference). Best for ambiguous queries where the user’s wording underspecifies their intent. - Step-back prompting — the LLM rewrites an over-specific question into a higher-level abstraction, retrieves on the abstraction, then answers the original question grounded on those broader passages. Best when the literal query terms are too narrow for any single passage to match.
- Query decomposition — the LLM splits one compound question into sub-questions, each routed to a tool or sub-index, then synthesizes the answers. LlamaIndex’s
SubQuestionQueryEngineis the canonical implementation. Best for multi-hop questions that span sources. - Query routing — the LLM (or a small classifier) picks which index or tool to retrieve from before any embedding lookup happens. Selectors like
LLMSingleSelectorandLLMMultiSelectorin LlamaIndex give you explicit control. Best when you have multiple distinct knowledge sources.
The Architect’s Rule: if you can’t name the failure mode each transformation solves, you’ll stack all five and pay for none of them.
A sixth pattern — RAG-Fusion — is multi-query plus Reciprocal Rank Fusion (Raudaschl’s GitHub repository). Treat it as a flavor of multi-query, not a separate axis.
Step 2: Lock Down the Decision Inputs
The transformation is downstream of three things you should specify before touching code.
Decision input checklist:
- Query shape distribution — what fraction of real user queries are short factoids, what fraction are broad/exploratory, what fraction are compound? Sample your logged queries and tag them. This is the highest-signal input.
- Corpus characteristics — is the domain well-specified (legal, medical records, internal docs) or fast-evolving (news, research, product changelogs)? HyDE’s value is highest when no labeled relevance data exists.
- Latency budget — every transformation costs at least one extra LLM call. Multi-query and RAG-Fusion cost N retrievals. If your p95 budget is tight, HyDE on a small LLM alone can blow it.
- Number of distinct knowledge sources — one corpus or many? Routing only earns its place when you have two or more sources where the right index needs to be picked first.
- Confidence signal availability — can you compute a query–document confidence score (BM25 score, top-1 dense score, hybrid score from Hybrid Search)? Without one, the “fall back to plain RAG when confidence is high” pattern from HyDE research stays theoretical.
The Spec Test: if your transformation choice doesn’t change when you swap your query shape distribution or your latency budget, you haven’t actually made a decision — you’ve copied a default.
Step 3: Match the Transformation to the Failure Mode
Now wire each transformation to the specific failure it fixes. Build order matters because each later choice depends on inputs from the earlier ones.
Build order:
- Routing first — if you have multiple sources, route before transforming. A bad transformation on the wrong index wastes more than it saves. Routing is also the cheapest layer to debug: one LLM call, one selector decision, traceable.
- Decomposition second — if your query distribution shows compound questions (“compare X and Y”), add a
SubQuestionQueryEngine-style decomposer above your retrievers (LlamaIndex Docs). Each sub-question becomes a routable unit, which is why decomposition slots above routing in the decision graph. - Step-back or HyDE third — pick one, not both. Step-back when queries are too specific (precise dates, narrow facts, model numbers). HyDE when queries are too generic and you have no labeled pairs to tune on. The original Step-Back paper reports gains on PaLM-2L of +27% on TimeQA and +7% on MuSiQue — those numbers are dataset-specific, but the pattern (abstraction lifts narrow-fact recall) generalizes.
- Multi-query last — only add multi-query rewriting when your evaluation set shows ambiguity-driven misses after the previous layers are tuned. Otherwise you are paying N×retrieval cost for marginal recall lift.
For each transformation, your context must specify:
- What it receives (raw user query? routed sub-query? abstracted query?)
- What it returns (single transformed query? N queries? a fused ranked list?)
- What it must NOT do (HyDE: don’t run on fact-bound personal queries without a confidence gate; multi-query: don’t run on already-disambiguated routed queries)
- How to handle failure (LLM rewrite returns nonsense → fall back to original query and log the event)
Compatibility & caveats note:
- LangChain v1 migration:
MultiQueryRetrievermoved fromlangchain.retrieversinto thelangchain_classicpackage, and theparser_keyparameter was removed. Update import paths in any code generated from older tutorials (LangChain v1 migration guide).- LlamaIndex docs URL: canonical docs moved from
docs.llamaindex.aitodevelopers.llamaindex.ai(301 redirect). Use the new domain in citations and bookmarks.- HyDE in fact-bound domains: a 2025 study on small Gemma models documented 25–60% latency overhead and elevated hallucination rates (“Assessing RAG and HyDE on Gemma”). Treat HyDE as “do not use for personal or private fact retrieval without a confidence gate.”
Step 4: Validate the Choice With Real Queries
A transformation either lifts your evaluation metrics or it doesn’t. Decide before you ship, not after.
Validation checklist:
- Recall@k on held-out queries — run the same queries with and without the transformation. Failure looks like: recall@10 barely moves. That’s noise; rip the transformation out.
- Per-query-shape segmentation — break recall down by query type (factoid, exploratory, compound). Failure looks like: HyDE lifts exploratory recall but tanks factoid recall. Add a query classifier and gate HyDE behind it.
- Latency cost vs. recall delta — plot p95 latency on x, recall@10 on y, before vs. after. Failure looks like: latency up, recall flat or up by less than your SLA tolerance. Cut.
- Hallucination check on transformed queries — log the LLM-generated documents (HyDE) or rewrites (multi-query) for a random sample. Failure looks like: rewrites change the user’s intent. Tighten the rewrite prompt or drop the transformation for that query class.
- Self-consistency across reruns — run the same query several times. Failure looks like: top-3 documents differ across runs. Lower the temperature on the rewrite LLM or pin the seed.
Common Pitfalls
| What You Did | Why AI Failed | The Fix |
|---|---|---|
| Stacked HyDE + multi-query + reranker on every query | Three transformations on a query that needed zero — pure latency tax | Route first; pick at most one transformation per query class |
| Used HyDE on personal/private fact retrieval | LLM hallucinated specifics that didn’t filter out on a small encoder | Add a confidence gate — fall back to plain RAG when query–doc score is high |
| Used multi-query on already-precise queries | Three rewrites of “what is X version Y” all retrieved the same docs | Gate multi-query behind an ambiguity classifier |
| Added step-back without changing the answer-time prompt | Retrieved on the abstraction, but answered without grounding | Specify the two-stage contract: retrieve on abstraction, answer on original question with abstracted documents as context |
| Skipped routing because “the LLM can figure it out” | Wrong index queried, recall was a lottery | Add an explicit LLMSingleSelector — one cheap call, one auditable decision |
Pro Tip
The mature 2026 pattern isn’t picking one transformation. It’s wrapping the choice in an agent loop. Route the query, classify its shape, dispatch to the right transformation, retrieve, grade the retrieved set with a small judge model, and self-correct if the grade is below threshold. Per dmflow.chat’s RAG transformation guide, this is what production Agentic RAG systems are converging on. You design the decision graph; the agent walks it at runtime.
Frequently Asked Questions
Q: When should you use HyDE instead of multi-query retrieval? A: Use HyDE when the query is generic or exploratory and you have no labeled query–document pairs to tune on. Use multi-query when the query is ambiguous and could be phrased five different ways. The tell: if a colleague would ask “do you mean X or Y?” — that’s multi-query territory. If they’d say “I’m not sure what to ask, write me an example,” that’s HyDE.
Q: When does step-back prompting work better than query decomposition? A: Step-back wins on single questions that are too narrow — a precise date, a specific model number, a technical clause where literal terms don’t appear in any passage. Decomposition wins on compound questions that genuinely span topics or sources. The diagnostic: can the question be answered from one document? If yes, step-back. If no, decompose.
Q: How do you choose between query routing and RAG-Fusion for production RAG? A: They solve different problems. Routing picks which index to query when you have multiple sources — one cheap LLM call, one selector. RAG-Fusion picks which phrasing wins by running multiple retrievals against one index and merging via Reciprocal Rank Fusion. Use routing first if you have two or more sources. Reach for RAG-Fusion only inside a chosen index when ambiguity is the dominant failure mode and your latency budget can absorb N retrievals.
Your Spec Artifact
By the end of this guide, you should have:
- A query shape distribution — your logged queries tagged as factoid, exploratory, compound, or multi-source.
- A transformation decision tree — one branch per failure mode, with explicit constraints on which transformation runs and which is forbidden for that branch.
- A validation harness — held-out evaluation set, recall@k baseline, latency p95 baseline, and a per-query-shape breakdown.
Your Implementation Prompt
Drop the prompt below into Claude Code, Cursor, or Codex when you’re ready to wire the decision tree into your retrieval layer. Fill the bracketed placeholders with values from Step 2.
You are designing the query transformation layer for a RAG system. Build a
decision graph that selects exactly one transformation per query, based on
the inputs below.
# Decision inputs (from Step 2)
- Query shape distribution: [% factoid] / [% exploratory] / [% compound]
- Corpus characteristics: [domain stability — stable | fast-evolving]
- Latency budget (p95 end-to-end): [budget_ms] ms
- Number of distinct knowledge sources: [n_sources]
- Confidence signal: [hybrid_score | bm25_only | none]
# Required components (from Step 1)
1. Router (only if n_sources >= 2): use LlamaIndex LLMSingleSelector or
LLMMultiSelector.
2. Decomposer (only if % compound >= [threshold]): use SubQuestionQueryEngine.
3. One of {step-back, HyDE} — pick at most one:
- step-back if the dominant failure is over-specific queries
- HyDE if domain is fast-evolving AND no labeled pairs exist
- HyDE MUST be gated by a confidence threshold on [hybrid_score]; fall back
to plain RAG when score >= [confidence_threshold]
4. Multi-query rewriter: only as a last layer, gated by an ambiguity classifier.
# Build order (from Step 3)
Routing -> Decomposition -> (Step-back OR HyDE) -> Multi-query.
# Output contract for each transformation
- Receives: [raw_query | sub_query | abstracted_query]
- Returns: [single_query | n_queries | fused_ranked_list]
- On failure: fall back to the previous layer's output and log the event.
# Validation harness (from Step 4)
On a held-out set of [n_eval] queries, report:
- recall@10, segmented by query shape
- p95 latency delta vs. plain RAG
- hallucination rate on a sample of transformed queries
- self-consistency across N reruns
# Hard constraints
- LangChain v1: import MultiQueryRetriever from langchain_classic, NOT from
langchain.retrievers.
- LlamaIndex docs canonical host is developers.llamaindex.ai.
- Do NOT stack HyDE and multi-query on the same query class.
- Do NOT run HyDE on personal/private fact retrieval without a confidence gate.
Generate: (1) the decision graph as code, (2) the validation harness, (3) a
config file binding the bracketed values above to runtime parameters.
Ship It
You now have a decision graph instead of a transformation stack. The next time someone says “let’s add HyDE on top of multi-query,” you have a checklist that names the failure mode each one solves and an evaluation harness that decides whether either earns its place. The transformations stop being decoration and start being engineering choices.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors