When to Choose Encoder-Decoder Over Decoder-Only: T5, BART, and Whisper Use Cases in 2026
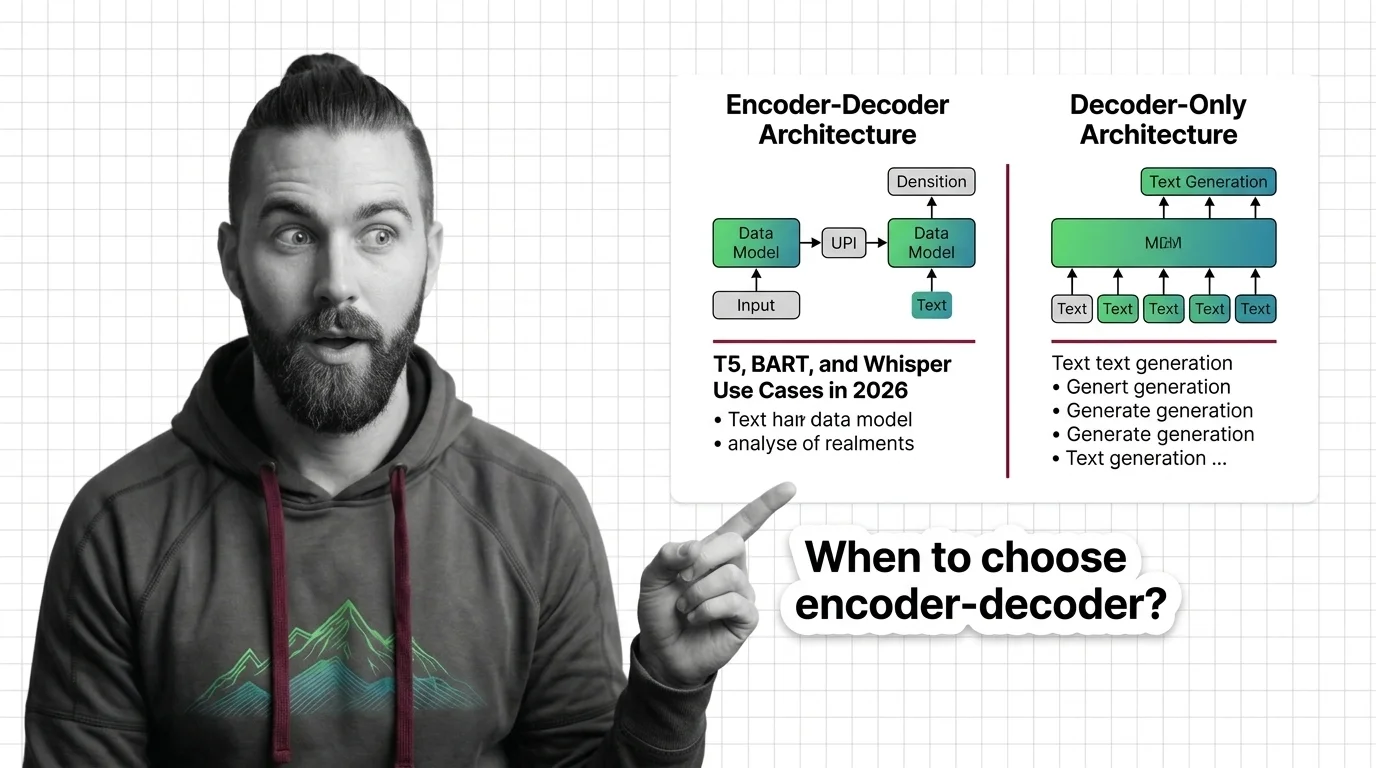
Table of Contents
TL;DR
- Encoder-decoder architectures outperform decoder-only at equal parameter counts for structured input-output tasks
- The architecture decision is a specification problem — match task shape to model shape before writing a single line of code
- T5, BART, and Whisper each own a specific task corridor where decoder-only models waste parameters
You threw a multi-billion-parameter decoder-only model at a summarization task. It works. Sort of. The summaries drift, the output length is unpredictable, and your latency budget is gone because the model is autoregressively grinding through tokens it didn’t need to generate. The Encoder Decoder Architecture sitting in the corner at a fraction of the parameters would have nailed it. Architecture fit is not a preference. It is a specification.
Before You Start
You’ll need:
- A Hugging Face account with model hub access
- Understanding of Transformer Architecture and Attention Mechanism fundamentals
- A clear picture of your input-output task shape
This guide teaches you: How to diagnose whether your task demands an encoder-decoder model — and how to specify the architecture contract before your AI tool picks the wrong one.
The Summarizer That Talked Too Much
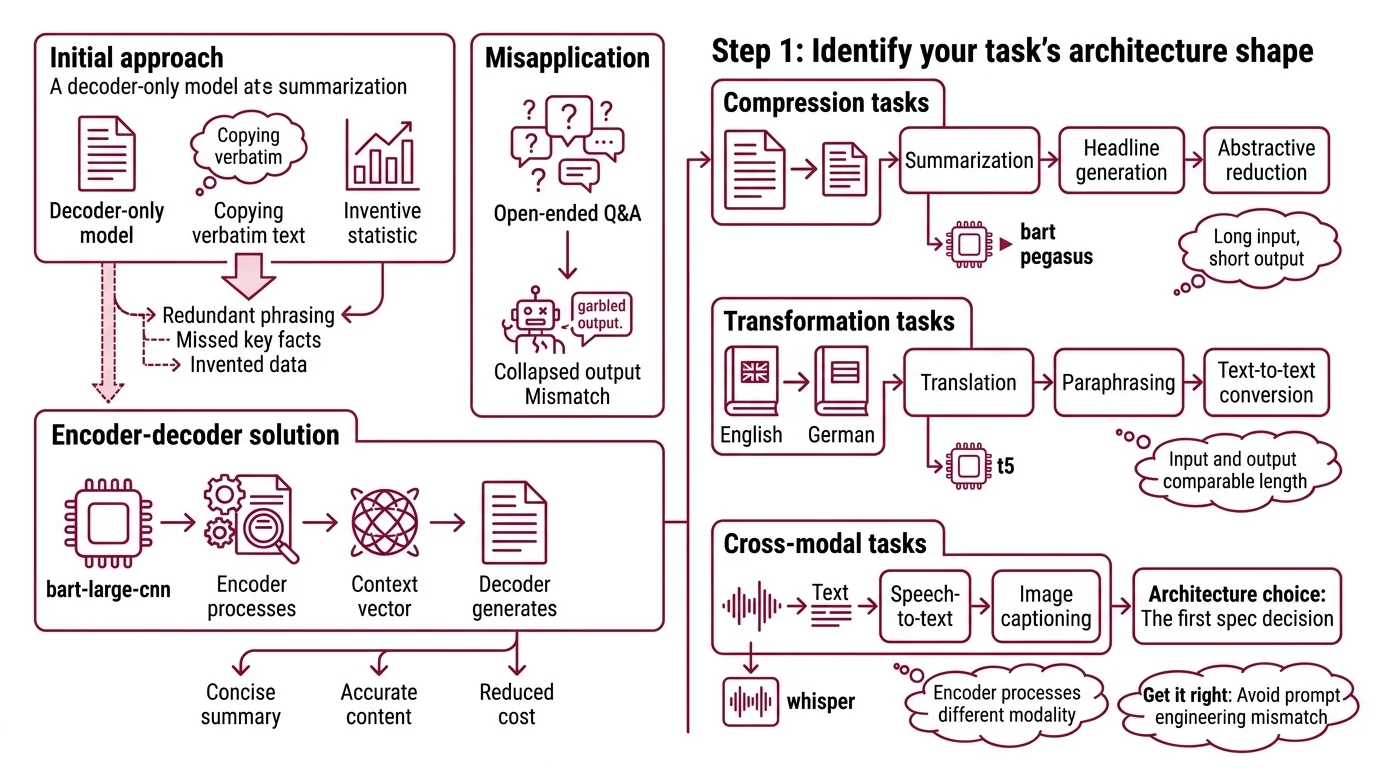
A team fine-tunes a decoder-only model for document summarization. The model sees the full document in its context window. Generates a summary. The summary is mostly right — except it copies entire phrases verbatim, misses the key finding buried in paragraph four, and occasionally invents a statistic.
They switch to Bart-large-cnn. A fraction of the parameters. The encoder reads the entire document, compresses it into a Context Vector, and the decoder generates only what needs generating. Summaries get tighter. Faithfulness goes up. Inference cost drops.
It worked on Tuesday. On Thursday, the team tries the same model for open-ended Q&A and the output collapses — because encoder-decoder models are not general-purpose chat engines.
The architecture choice is the first spec decision. Get it wrong, and no amount of prompt engineering fixes the mismatch.
Step 1: Identify Your Task’s Architecture Shape
Every NLP task has a shape. Input length, output length, and the relationship between them. Encoder-decoder models win when that relationship is asymmetric — long input, short structured output.
Three architecture corridors:
- Compression tasks — Summarization, headline generation, abstractive reduction. Input is long, output is short. The encoder reads everything; the decoder produces only the essentials. This is where BART and PEGASUS live.
- Transformation tasks — Translation, paraphrasing, text-to-text conversion. Input and output are comparable length, but the mapping is structured. T5 was built for this — every task gets a prefix like “summarize:” or “translate English to German:” (Raffel et al.).
- Cross-modal tasks — Speech-to-text, image captioning. The encoder processes a different modality entirely. Whisper’s encoder digests audio spectrograms while the decoder produces text tokens.
If your task doesn’t fit one of these corridors, a decoder-only model is probably the right call. Chat, open-ended generation, reasoning chains — those belong to autoregressive models that predict one token at a time.
The Architect’s Rule: If your output is a structured function of your input, encoder-decoder. If your output is a continuation of your input, decoder-only.
Step 2: Lock Down the Model-Task Contract
You’ve identified the corridor. Now specify the constraints before your AI tool starts downloading weights.
Context checklist:
- Task type and prefix format specified (T5 uses “summarize:”, “translate:”, etc.)
- Maximum input length defined (encoder has a fixed window)
- Maximum output length defined (decoder generation budget)
- Beam Search parameters specified (beam width, length penalty)
- Evaluation metric chosen (ROUGE for summarization, WER for ASR, BLEU for translation)
- Hardware constraints documented (GPU memory, latency budget, batch size)
Model selection matrix:
| Task | First Pick | Size Range | Why |
|---|---|---|---|
| Abstractive summarization | BART-large-cnn | 400M | Pre-trained on CNN/DailyMail, production-tested baseline (HF Model Hub) |
| Text-to-text (custom) | Flan-T5 | 80M-11B | Instruction-tuned on 1.8K tasks, five sizes from Small to XXL (HF Docs) |
| Speech-to-text | Whisper large-v3-turbo | 809M | 6x faster than large-v3, accuracy within 1-2% (OpenAI GitHub) |
| Multi-task fine-tune | Flan-T5 XL/XXL | 3B-11B | Text-to-text framework handles any task with prefix routing |
Note that both Flan-T5 and BART have not received major model updates since 2022 and 2020, respectively. They remain widely used and production-stable, but are not actively developed with new model versions.
The Spec Test: If your context doesn’t specify the task prefix format, the model will treat your input as raw text and hallucinate the task boundary. A summarization job becomes a continuation. A translation becomes a paraphrase.
Step 3: Wire the Inference Pipeline
Order matters. The encoder must finish before the decoder starts. This is not optional — it is the architecture.
Build order:
- Input preprocessing first — Tokenization, truncation to encoder max length, task prefix attachment. This is where most silent failures happen. A document longer than the encoder window gets silently truncated, and your summary misses everything after the cut.
- Encoder pass second — Full bidirectional attention over the input. The encoder sees everything simultaneously. This is the structural advantage over decoder-only — no causal mask, no information bottleneck at position zero.
- Decoder generation last — Autoregressive output with cross-attention to encoder states. Specify stopping criteria: max tokens, end-of-sequence token, length penalty for beam search.
For each component, your context must specify:
- What it receives (raw text, audio frames, tokenized IDs)
- What it returns (encoder hidden states, decoded token sequence, confidence scores)
- What it must NOT do (exceed memory budget, generate beyond max length)
- How to handle failure (input too long: truncate or chunk; confidence below threshold: flag for review)
Step 4: Validate Architecture Fit
You picked a model. You built the pipeline. Now prove the architecture decision was right — not just that the output “looks okay.”
Validation checklist:
- Output faithfulness — generated text contains only information present in the input. Failure looks like: invented statistics, attributed quotes that don’t exist in the source, entity confusion between similar names
- Compression ratio — output length is within your specified budget. Failure looks like: summaries that are longer than the original, or so short they drop critical information
- Latency budget — end-to-end inference fits your SLA. Failure looks like: encoder-decoder is slower than expected because your batch size exceeds GPU memory and spills to CPU
- Cost per inference — stays within your unit economics. For the Whisper API path: whisper-1 and gpt-4o-transcribe both run at $0.006/minute; gpt-4o-mini-transcribe halves that to $0.003/minute (OpenAI Pricing). OpenAI now recommends gpt-4o-mini-transcribe over whisper-1 for best accuracy, so evaluate both before locking in.
Common Pitfalls
| What You Did | Why It Failed | The Fix |
|---|---|---|
| Used decoder-only for summarization | Model treats summary as continuation, drifts from source | Switch to encoder-decoder — separate reading from writing |
| Skipped task prefix on T5 | Model doesn’t know what task to perform, outputs gibberish | Add explicit prefix: “summarize:”, “translate English to German:” |
| Ignored encoder max length | Input silently truncated, summary misses key content | Measure input lengths, implement chunking strategy |
| Picked Whisper API without checking newer options | OpenAI recommends gpt-4o-mini-transcribe over whisper-1 | Benchmark both on your audio domain before committing |
| Fine-tuned Flan-T5 XXL without trying Small first | Burned GPU hours before validating task fit | Start with the smallest viable size, scale only if metrics demand it |
Pro Tip
Architecture fit is your cheapest optimization. At smaller parameter counts, encoder-decoder models consistently beat decoder-only on complex structured tasks. At larger scales, recent research found encoder-decoder matches decoder-only scaling while delivering better inference efficiency — though these findings come from research-scale experiments up to roughly 8B parameters, not production deployments (Zhang et al.). Before you throw more parameters at a problem, check if you are using the wrong architecture shape entirely. The cheapest GPU hour is the one you never spend.
Frequently Asked Questions
Q: When should you use an encoder-decoder model instead of a decoder-only model? A: When your task has a clear input-output structure — summarization, translation, speech-to-text. Encoder-decoder separates comprehension from generation, reducing hallucination on structured tasks. If your output must stay faithful to a source document, start here.
Q: How to fine-tune Flan-T5 for a custom text-to-text task step by step? A: Define your task prefix first — every example needs a consistent prefix like “classify:” or “extract:”. Start with Flan-T5 Small to validate task fit before scaling up. Use the Hugging Face Seq2SeqTrainer and evaluate on held-out data every epoch. Smallest viable model first; scale only when metrics demand it.
Q: What are the best encoder-decoder models for text summarization in 2026? A: BART-large-cnn is the production baseline for news-domain summarization. For custom domains, fine-tune Flan-T5 at the size your GPU budget allows. PEGASUS competes on news but benchmarks vary by dataset. As of 2026, no single encoder-decoder dominates all summarization tasks.
Q: How to use BART for abstractive summarization in a production pipeline? A: Load facebook/bart-large-cnn and specify max_length, min_length, and beam count in your generation config. Wrap it behind an API with input validation — reject documents exceeding the encoder token limit or implement chunk-and-merge. Monitor ROUGE weekly; weights are frozen but data distribution is not.
Your Spec Artifact
By the end of this guide, you should have:
- Architecture decision map — a documented rationale for why encoder-decoder fits your task corridor (compression, transformation, or cross-modal)
- Model-task contract — task prefix, input/output length limits, beam search parameters, hardware constraints, and evaluation metric
- Validation criteria — faithfulness checks, compression ratio targets, latency SLA, and cost-per-inference budget
Your Implementation Prompt
Paste this into Claude Code, Cursor, or your AI coding tool. Fill in every bracket with your specific values from Steps 1-4.
Build an inference pipeline for an encoder-decoder model with these specifications:
ARCHITECTURE DECISION:
- Task type: [compression | transformation | cross-modal]
- Model: [bart-large-cnn | flan-t5-{size} | whisper-large-v3-turbo]
- Task prefix (T5 only): "[your prefix]:"
INPUT CONTRACT:
- Input format: [raw text | audio file path | tokenized IDs]
- Max input tokens: [encoder max length from model card]
- Overflow strategy: [truncate | chunk-and-merge]
OUTPUT CONTRACT:
- Max output tokens: [decoder generation budget]
- Beam width: [1-5]
- Length penalty: [0.6-2.0]
- Stop condition: [EOS token | max length | both]
VALIDATION:
- Primary metric: [ROUGE-L | WER | BLEU]
- Faithfulness check: [flag outputs containing information not in input]
- Latency budget: [max ms per inference]
- Cost ceiling: [max $ per 1000 inferences]
Build preprocessing, encoder pass, decoder generation, and validation as separate functions.
Each function accepts typed inputs and returns typed outputs.
Include error handling for inputs exceeding the encoder window.
Ship It
You now have a decision framework that separates architecture choice from model choice from hyperparameter choice. Three layers. Three contracts. The next time someone says “just use GPT for everything,” you can point to the spec that says otherwise — and the validation results that prove it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors