When the Bot Approves Your PR: Accountability, Deskilling, and the Hidden Costs of AI Code Review
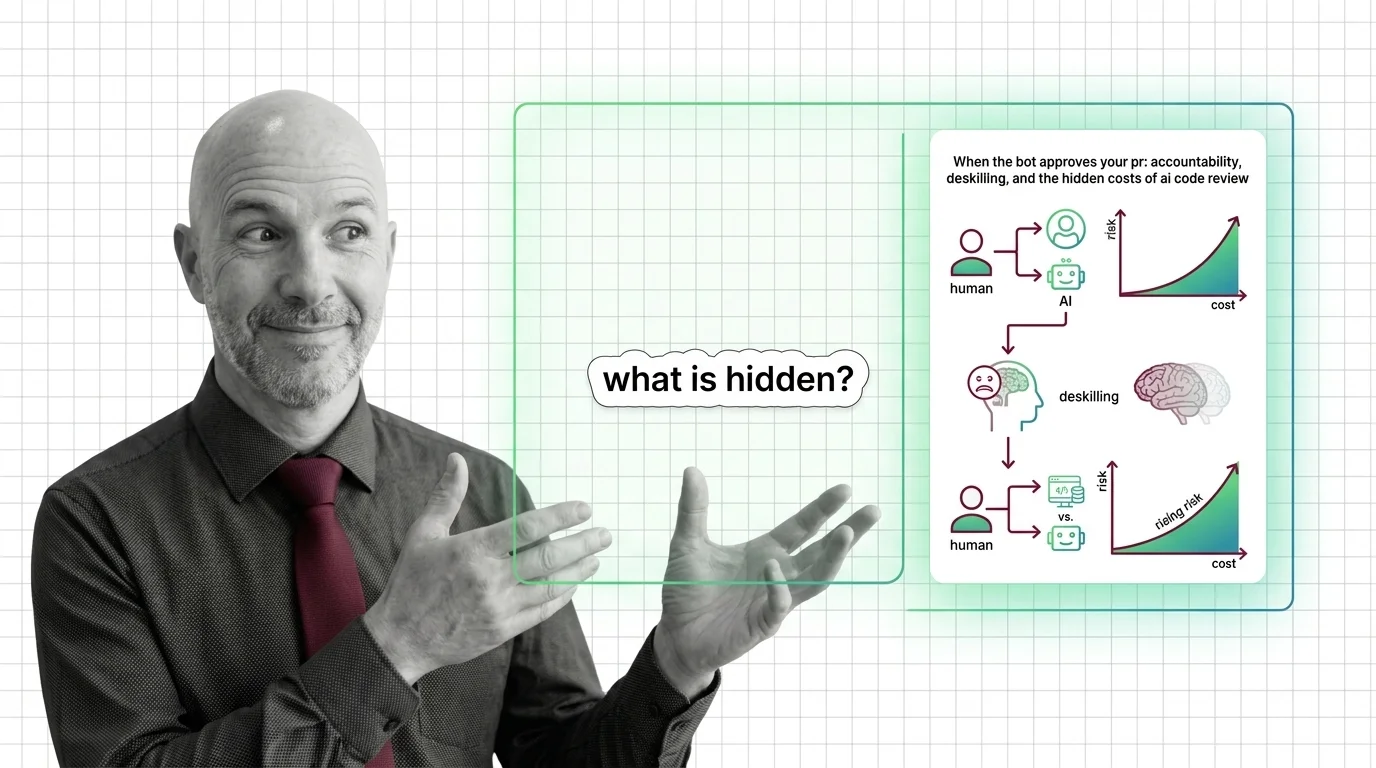
Table of Contents
The Hard Truth
A bot just approved your pull request. The change merges, the build goes green, the feature ships. Three months later, a regulator asks who reviewed the line that leaked customer credentials. What will you say — that the model looked competent that morning?
There is a quiet thing happening inside engineering organizations. The small ritual of AI Code Review — one human reading another’s work, asking questions, and taking on a sliver of responsibility for what enters the main branch — is being handed to systems that cannot, by any meaningful standard, take responsibility for anything. We notice the productivity gains. We rarely notice what has been moved out of the human loop, or who, exactly, is now standing where the reviewer used to stand.
When the Bot Approves Your PR
The numbers tell a story we have not finished interpreting. 84% of developers now use or plan to use AI tools in their workflow, up from 76% a year earlier (Stack Overflow 2025 Survey). And yet only 3.1% say they “highly trust” the accuracy of what those tools produce. 66% report that the most common frustration is output that is “almost right, but not quite” — the most dangerous failure mode a reviewer can encounter, because it passes the eye but fails the system.
What does it mean to ship code that 59% of developers admit they do not fully understand (Clutch survey)? Not poorly understand. Not understand at the surface but not in depth. Do not fully understand. The act of review presupposes a reviewer. When the reviewer is also the author, and the author is also a model, and the human in the chain is approving suggestions they cannot fully reconstruct — what is happening is not review. It is rubber-stamping with a more sophisticated rubber stamp.
The Reasonable Case for Letting Machines Read the Code
The case for AI code review is not foolish. It is, in many ways, the case for any tool that scales human attention. A senior engineer’s eye is the scarcest resource in any engineering organization, and most pull requests do not need that scarcity spent on them. A typo, a missing null check, a forgotten import — these can be caught by something less expensive than a person.
Tools like GitHub Copilot Code Review and CodeRabbit have made review faster in a real, measurable way. They flag patterns. They suggest naming improvements. They catch the boring 30% of issues that wear human reviewers down before they reach the issues that actually require judgment. The dream is not unreasonable: the bot handles the trivial, the human handles the consequential, and the team ships better software with less burnout.
It is a dream worth taking seriously. The question is whether the dream describes what is actually happening, or what we wish were happening.
Where the Reviewer’s Eye Used to Live
Here is the assumption hiding inside the dream: that AI reviewers and human reviewers are looking at the same things, just at different speeds. A recent academic study of Copilot Code Review found something less convenient. The tool consistently flags style issues and small bugs, but misses entire classes of security vulnerabilities — SQL injection, cross-site scripting, insecure deserialization (Amro & Alalfi 2025 arXiv). The bot is not a faster reviewer. It is a different reviewer, with a different field of vision.
The empirical picture beneath this is uncomfortable. An ACM TOSEM 2025 empirical study of Copilot, CodeWhisperer, and Codeium snippets found security weaknesses in 29.5% of Python samples and 24.2% of JavaScript samples. AI-assisted commits expose credentials in 3.2% of cases, compared with 1.5% for human-only commits (CSA Research Note 2025). A CodeRabbit-funded analysis — which deserves to be cited with that caveat, since the company sells AI code review — reports that AI-authored pull requests carry 1.7× more issues overall and 2.74× more security issues than human-authored ones (Atomic Robot synthesis).
These are not equivalent reviewers operating at different speeds. They are different reviewers with overlapping but non-identical blind spots. And when both reviewer and author are the same system, the blind spot is no longer caught on the other side of the desk.
Code Review Was Never Just About Code
It helps to remember what code review actually was, historically. It was never only about catching bugs. It was a transmission mechanism — a way that senior engineers passed judgment, style, and institutional memory to junior ones. It was a moment of collective ownership, where the second pair of eyes signed off and, in doing so, accepted a portion of the consequences. It was an apprenticeship dressed as a process.
Bureaucracies have always faced this temptation: to take a human practice that produced both an outcome and a relationship, and to automate the outcome while letting the relationship quietly dissolve. The customs of medieval guilds, the ritual of the second-opinion physician, the editorial back-and-forth in a newsroom — these were not just quality checks. They were how knowledge moved between generations of practitioners. A systematic literature review covering 89 studies has begun to document what happens when that transmission stops: reduced problem formulation, weaker mental models, reasoning that gets quietly outsourced (DevOps.com synthesis 2025).
The question is not whether AI review catches bugs. The question is what kind of engineering culture we are building when the most pedagogical moment in a junior engineer’s week is replaced by a model that produces correct-looking suggestions and asks nothing in return.
What We’re Actually Outsourcing
Thesis: When we route code review through AI tools without rebuilding the accountability and learning structures that human review used to carry, we are not automating a task — we are dissolving a profession’s quiet apprenticeship and leaving a liability vacuum no model can fill.
The accountability piece is the part that hardens, legally, very soon. The EU AI Act’s prohibited-practices provisions came into force on February 2, 2025; general-purpose AI obligations on August 2, 2025; and the high-risk system obligations under Annex III become enforceable on August 2, 2026 (EU Commission). That last date is now less than three months away. The Act does not, by itself, classify GitHub Copilot or similar coding assistants as high-risk. But the so-called compliance trinity — the AI Act paired with the Cyber Resilience Act and the Product Liability Directive — places the responsibility for shipped software firmly on the manufacturer, regardless of who or what wrote the code (EU Commission liability rules). The bot will not be subpoenaed. You will.
NIST’s March 2025 AI Risk Management Framework update emphasizes model provenance, audit trails, and human-in-the-loop oversight for high-impact systems (NIST AI RMF). The direction of travel is clear in both Brussels and Washington: the human-in-the-loop is no longer an optional design pattern. It is becoming an evidentiary requirement. And evidence requires a human who actually looked, actually understood, and is actually willing to sign their name.
The Conversations We Need Before August
None of this means abandoning AI code review. It means using it like a tool rather than a substitute. A few questions are worth sitting with, inside your team, before the high-risk provisions take effect.
Which classes of defect is your AI reviewer documented to miss, and have you adjusted human review accordingly — or are you assuming coverage you do not have? When a junior engineer accepts a Copilot suggestion they cannot reconstruct, what is the team’s policy? Is there one? When the post-incident review asks who approved the merge, will the answer be a name, or a tool version? Vigilance decrement is well-documented: human attention on review tasks drops sharply after the first thirty minutes, and experienced developers appear to over-trust AI suggestions once early ones look correct (Springer AI & Society 2025). Have you designed your process around that fact, or against it?
These are not technical questions. They are governance questions, and they are being answered, by default, every time a team adopts a new AI Code Completion workflow without examining what it displaces.
Where This Argument Could Be Wrong
The honest part. If the next generation of AI reviewers closes the security-class blind spot — if Copilot’s successors catch SQL injection and insecure deserialization as reliably as a competent human — the diagnostic half of this essay weakens. And if engineering organizations rebuild the apprenticeship layer in some new form, perhaps through structured pairing sessions where the human reviews the AI’s reasoning rather than the code itself, the deskilling concern becomes a transition problem rather than a permanent loss. The argument here is about what is happening now, not what must always happen. It is also a perspective, not a legal analysis.
The Question That Remains
A pull request is, in the end, a small act of trust between people who share consequences. We are replacing the trust with a tool, but we have not yet replaced the consequences. When the defect ships and the regulator calls, whose name will be on the signature line — and will they know what they signed?
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors