When Data Augmentation Helps and When It Hurts: Distribution Shift and Label Corruption

ELI5
Data augmentation creates synthetic training examples by transforming real ones — rotating images, paraphrasing text. It usually helps. But when those transforms drift from real-world data or break the label, they teach the model the wrong thing.
A team adds rotations, flips, and color jitter to their image pipeline. The training curve looks better than ever — loss drops, validation accuracy climbs. Then the model meets real users and performs quietly worse than the version trained on the smaller, untouched dataset. Nothing crashed. No error fired. The augmentation did exactly what it was told, and that was the problem.
The intuition behind Data Augmentation is clean: more variety during training produces a model that generalizes better. Most of the time, that holds. But the intuition hides an assumption — that every synthetic example you generate still belongs to the world the model will actually meet at inference time. Break that assumption, and augmentation stops being free data. It becomes a slow leak, and it leaks in a direction you chose.
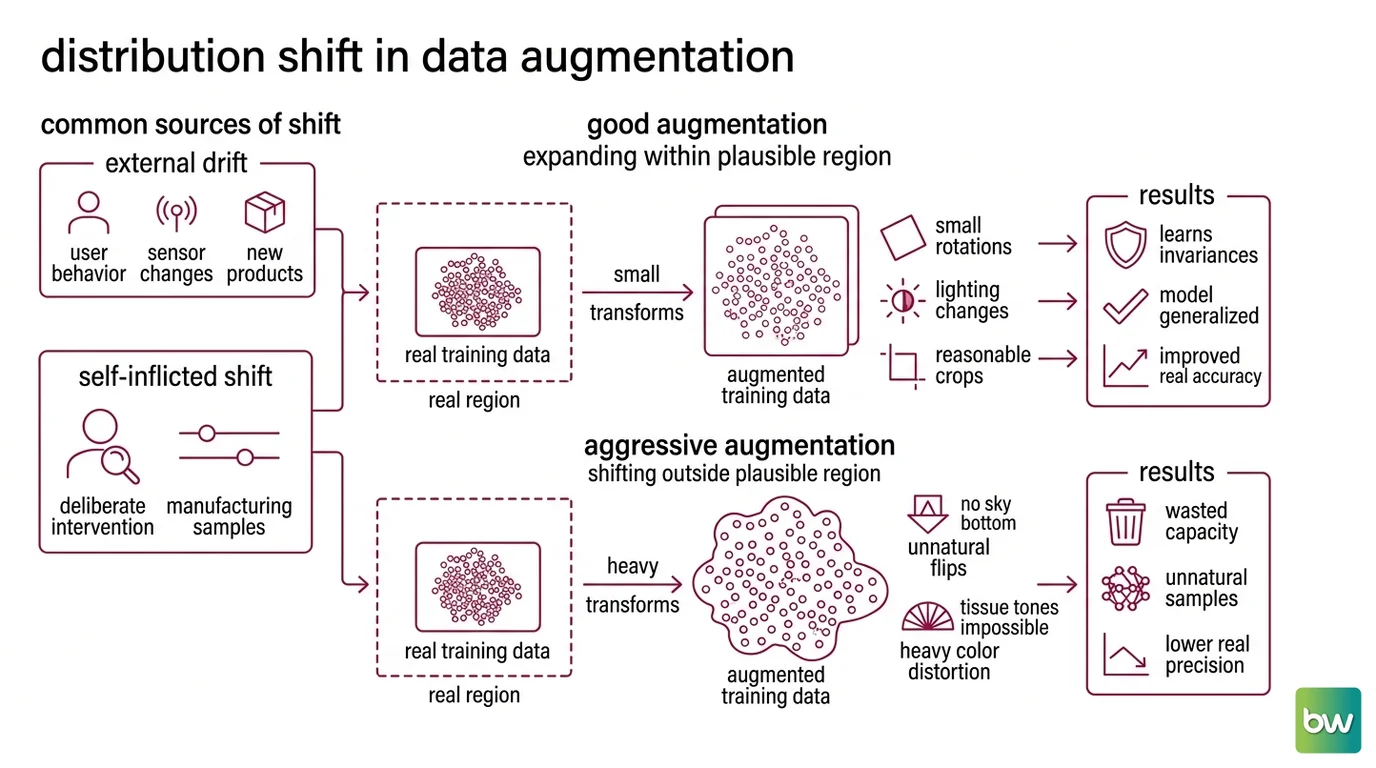
The Distribution You Train On Is Not the One You Think
Every supervised model learns a mapping from a distribution of inputs to a distribution of labels. Augmentation does not add observations from the real world — it manufactures new ones by applying transforms to the data you already have. That is a deliberate intervention on the training distribution. The question that decides whether it helps or hurts is whether the manufactured samples still look like things the model will encounter once it is running.
What is distribution shift and why does it matter for data augmentation?
Distribution shift is the gap between the data a model trained on and the data it sees in practice. Normally we treat it as something that happens to us — user behavior drifts, a sensor gets replaced, a new product category appears. Augmentation introduces a second, self-inflicted source of the same problem: you can shift the training distribution away from reality on purpose, without noticing.
Picture the set of all images your model could plausibly see at inference as a region in a high-dimensional space. The real training set is a cloud of points inside that region. Good augmentation expands the cloud to fill more of the same region — small rotations, lighting changes, and crops that produce images a camera could actually capture. The model learns invariances that match the world.
Aggressive augmentation does something different. A vertical flip applied to street scenes teaches the model that the sky can appear at the bottom of the frame — an image no real camera produces. Heavy color distortion on medical scans invents tissue tones that no scanner outputs. The cloud of training points now bulges outside the region of plausible inputs. The model spends capacity learning to classify samples it will never meet, and pays for it by fitting the real region less precisely.
This is the mechanism behind the opening anomaly. The training and validation curves improve because validation data is usually augmented the same way — so it lives in the same distorted region. The metric you trust is measuring performance on the world you invented, not the one your users live in. Your validation set inherited the same shift. The collapse only shows up in the wild, where the distortions you trained against simply do not occur.
Not more data. Different data.
The same logic applies far beyond vision. Back Translation, introduced by Sennrich and colleagues in 2016 (Sennrich et al.), paraphrases text by translating it to another language and back. Done lightly, it produces natural rewordings. Pushed hard, it generates stilted phrasings, register shifts, and occasional semantic drift — sentences from a dialect of the language nobody actually writes. SpecAugment, proposed by Park and colleagues in 2019 (SpecAugment paper), masks bands of time and frequency in audio spectrograms; mask too much and you train a speech model on signals no microphone records. Libraries that bundle these transforms across modalities — AugLy packages image, audio, text, and video augmentations in one place — make it trivial to turn the strength up, which is exactly where the danger lives.
When the Label Stops Describing the Input
Distribution shift moves the inputs. The second failure mode is quieter and more corrosive: the transform changes the input so much that the original label no longer describes it. The supervised contract is that y is the correct answer for x. Augmentation that preserves x’s identity keeps the contract. Augmentation that alters identity while keeping the old label hands the model a lie and asks it to memorize it.
When does data augmentation hurt model accuracy?
It hurts in two distinct regimes, and separating them matters because the fixes differ.
The first regime is the distribution shift above: the label is still technically correct, but the input has wandered out of the real region. The second is label corruption — the input has changed category while the label stayed frozen. The textbook case is a digit classifier: rotate a handwritten 6 by 180 degrees and it becomes a 9, but the augmentation pipeline still attaches the label 6. You have manufactured a labeled contradiction. Multiply it across a training set and the model is forced to reconcile examples that disagree, which it can only do by becoming less confident and less accurate everywhere.
Label-mixing methods make this trade-off explicit rather than accidental, which is what makes them instructive. Mixup, introduced by Zhang and colleagues in 2017 (mixup paper), takes two images and their labels and blends both with the same interpolation weight — a 70/30 pixel blend carries a 70/30 label. CutMix, from Yun and colleagues in 2019 (CutMix paper), cuts a patch from one image into another and mixes the labels in proportion to the pixel area each occupies. These work because the soft label honestly reflects the synthetic input — the contract is renegotiated, not broken. They start to hurt when the mixing assumption fails: if the cut patch lands on the only region that identified the object, the area-weighted label overstates how much of that class is actually visible. The math is sound; the semantics quietly are not.
The corrosive version is when corruption is invisible. A flip that turns a left-turn arrow into a right-turn arrow. A back-translation that flips the sentiment of a review. A crop that removes the tumor from a scan still labeled “positive.” These do not announce themselves in the loss curve — they look like ordinary hard examples. They behave exactly like Label Noise: a small fraction degrades performance gradually, a large fraction can collapse it. The difference is that ordinary label noise comes from human annotators, while this kind you generated yourself and signed off on.
What This Predicts About Your Next Run
Once you see augmentation as an intervention on the training distribution rather than as free data, its behavior becomes predictable. The mechanism tells you where to look before the metrics do.
- If your training and validation accuracy both improve but real-world performance drops, suspect distribution shift — your validation set is probably augmented into the same distorted region as training.
- If accuracy degrades smoothly as you raise augmentation strength, suspect label corruption accumulating like injected noise; the transform is altering identity past the point the label survives.
- If a single transform causes a sharp drop while others are harmless, suspect a symmetry the task does not have — a vertical flip on text, a horizontal flip on directional signs, a rotation on digits.
- If augmentation helps a small dataset but hurts a large one, you are past the point of diminishing returns: the model already had enough real signal, and the synthetic samples now mostly add shift.
A useful diagnostic is to apply each augmentation only to inputs and then ask whether a human expert would still assign the original label. If they hesitate, the model will too — except the model cannot tell you it is confused. Tools like Active Learning can then help you spend annotation budget on the genuinely ambiguous real cases instead of on synthetic ones you fabricated.
Rule of thumb: an augmentation is safe only if it produces inputs the model could plausibly meet at inference and preserves the property the label describes. Fail either test and you are injecting shift or noise.
When it breaks: the most common failure is choosing augmentation strength by watching validation accuracy alone. Because validation data is typically augmented the same way as training, that metric rewards exactly the distortions that hurt real-world performance — so the pipeline optimizes itself into a distribution that never appears at inference time.
This is also why augmentation is not a substitute for Training Data Quality. It amplifies the signal already in your data, including its biases and its mislabeled examples; running Data Deduplication and cleaning labels first determines what augmentation will multiply. Careful Data Labeling And Annotation upstream beats aggressive transforms downstream, because you cannot transform your way out of a label that was wrong to begin with.
Tooling & maintenance notes:
- Albumentations → AlbumentationsX: Active development has moved to AlbumentationsX (v2.3.1, May 2026), now dual-licensed under AGPL-3.0 plus a commercial option (AlbumentationsX GitHub). The copyleft terms differ from the old MIT-licensed
albumentationspackage — review the license before bundling it into closed-source projects.- nlpaug: Frozen at v1.1.11 since July 2022 (nlpaug GitHub). Still a useful reference for text augmentation, but treat it as effectively unmaintained.
- AugLy (Meta): Frozen at v1.0.0 since March 2022 and covering four modalities (AugLy on PyPI). Good for robustness-style social-media transforms; not an actively developed project.
The Data Says
Augmentation is a controlled intervention on your training distribution, not a free supply of data. It helps when synthetic samples stay inside the region of plausible inputs and preserve the label’s meaning; it hurts when they drift outside that region (distribution shift) or sever the input-label contract (label corruption). The decisive habit is to judge each transform by whether a human expert would still assign the original label — not by a validation score that was distorted the same way training was.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors