What Is Transformer Architecture and How Self-Attention Replaced Recurrence

Table of Contents
ELI5
A transformer is a neural network that reads all words simultaneously instead of one-by-one, using self-attention to calculate how much each word should influence every other word in a sequence.
For decades, recurrent neural networks processed language the way a telegraph operator reads Morse code – one signal at a time, dragging a fading memory of everything that came before. By the fiftieth word in a sentence, the first word was a ghost. Then in June 2017, eight researchers at Google published a paper titled “Attention Is All You Need” and discarded recurrence entirely. Not refined it. Discarded it. Within two years, every state-of-the-art language model had followed.
The Architecture That Killed Sequential Processing
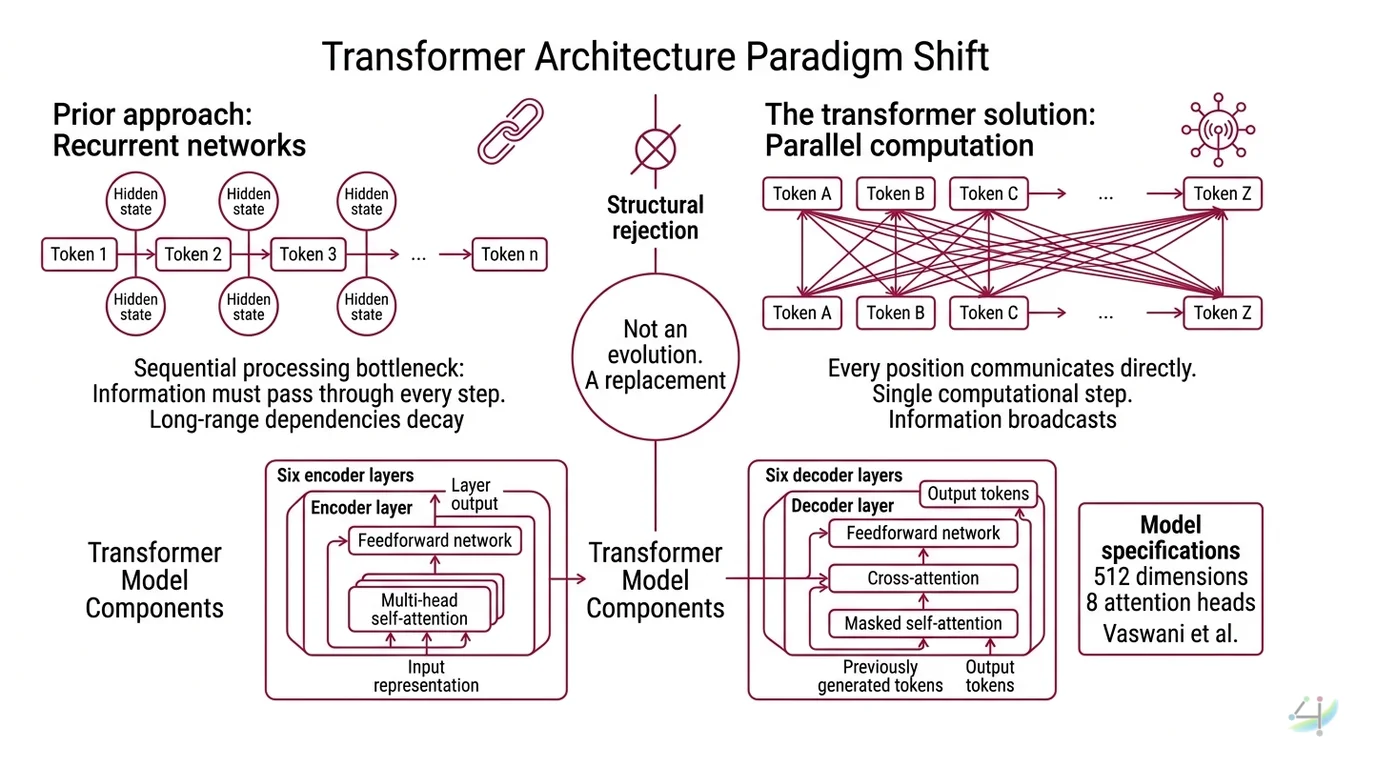
The transformer is not a better recurrent network. It is a structural rejection of the premise that language must be processed in order. Researchers had tried bolting attention mechanisms onto recurrent architectures – helping models “look back” at important positions. It helped, but it was a patch on a fundamentally sequential system. The transformer did not patch. It replaced.
What is transformer architecture in AI?
A transformer is a neural network architecture built on a single organizing principle: every element in a sequence can attend to every other element, simultaneously. No hidden state carried forward token by token. No sequential dependency. Just raw, parallel computation across an entire input.
The original model described by Vaswani et al. used an Encoder Decoder structure – six encoder layers that read the input sequence into a continuous representation, and six decoder layers that generate the output sequence one token at a time, attending both to the encoder’s output and to its own previously generated tokens. Each layer contains two core operations: multi-head self-attention and a position-wise Feedforward Network. The base model used 512 dimensions and 8 attention heads (Vaswani et al.).
This reads like a specification. The conceptual revolution is subtler.
Recurrent networks had a structural bottleneck: information had to pass through every intermediate step to travel from one end of a sequence to the other. A dependency between word one and word fifty required forty-nine sequential hops. Long-range dependencies decayed. Context evaporated. The transformer abolished that bottleneck by letting every position communicate directly with every other position – in a single computational step.
The information no longer travels through a chain. It broadcasts.
Not an evolution of recurrence. A replacement.
What are the main components of a transformer neural network?
Three components define the architecture, and each solves a specific problem that recurrence used to handle:
Self-attention – the mechanism that computes relationships between all positions simultaneously. Each position generates three vectors: a Query, a Key, and a Value. The dot product between Queries and Keys determines how much each position attends to every other. The result is a weighted combination of Values. This single operation replaces the recurrent hidden state that carried context forward step by step.
Positional encoding – transformers have no inherent sense of word order. Unlike recurrent networks, which encode sequence by processing tokens one after another, a transformer sees all positions at once – and cannot distinguish first from last without help. The original paper added sinusoidal position Embedding vectors to the input. Modern architectures have moved to Rotary Position Embedding – RoPE – which encodes relative position directly into the attention computation (HF Blog). The shift matters: absolute position encodings struggle with sequences longer than those seen during training; relative encodings degrade more gracefully.
Residual connections and layer normalization – each sub-layer (attention, feedforward) is wrapped in a residual connection and followed by normalization. This is not cosmetic engineering. Without residual connections, gradients vanish in deep networks, and the model stops learning after a few layers. The transformer’s depth – the ability to stack identical layers into towers of dozens or hundreds – depends entirely on these connections remaining trainable.
What you will not find anywhere in the computation graph: recurrence. The word “recurrent” does not appear in the transformer’s forward pass.
The Geometry of Paying Attention
Self-attention is the engine of the transformer. But the name misleads – it sounds like introspection. It is closer to a parallel search operation, executed in continuous vector space. Here is the mechanism that makes the entire architecture work.
How does self-attention work in transformer models?
Every input token passes through Tokenization and is then projected into three vectors: Query (Q), Key (K), and Value (V). The Attention Mechanism computes a single equation:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) * V
The scaling factor – dividing by the square root of the key dimension – prevents dot products from growing large enough to saturate softmax. Without this scaling, gradients collapse and the model stops learning. A small mathematical detail with catastrophic consequences if omitted.
The output of this equation is an attention matrix: a grid where each cell encodes how much one token attends to another. For a sequence of 100 tokens, you get a 100-by-100 matrix – every token scored against every other token, in parallel.
Think of it as a conference room. Each person (token) holds a question (Query) and a name tag (Key). When person A’s question is highly relevant to person B’s name tag, A pays more attention to B’s contribution (Value). Every person asks every other person simultaneously. No queue. No turn-taking. No sequential dependency.
Multi-head attention runs this computation in parallel across multiple subspaces. The original transformer used 8 heads; each head learns a different type of relationship. Research on attention head behavior suggests that individual heads specialize – one might track syntactic dependencies (subject-verb agreement across clauses), another semantic similarity, a third positional proximity. The 8 outputs are concatenated and projected back to the model dimension.
Eight simultaneous interpretations of the same input, fused into a single representation.
This is why transformers handle long-range dependencies that destroyed recurrent networks. The distance between two tokens is irrelevant; attention connects them directly, regardless of how many tokens separate them in the sequence.
But that directness carries a cost that only appears when you scale – and it becomes the architecture’s defining constraint.
From Translation Benchmark to Universal Machine
The transformer was designed for machine translation, and it dominated immediately. The base model achieved 28.4 BLEU on WMT 2014 English-to-German and 41.8 BLEU on English-to-French – trained in 3.5 days on 8 GPUs (Vaswani et al.). But the benchmark scores are not the story. What happened next is.
BERT took the encoder stack, masked random tokens during training, and learned bidirectional representations. GPT took the decoder stack, trained left-to-right on raw text, and learned to generate. Both discarded half the original architecture and scaled the remaining half to billions of parameters. The encoder half became the foundation for understanding tasks – classification, search, similarity. The decoder half became the foundation for generation – text, code, dialogue.
Then the architecture escaped language entirely. Vision Transformers applied the same self-attention to image patches. Whisper applied it to audio spectrograms. Protein structure prediction applied it to amino acid sequences. The architecture designed for translating sentences turned out to be a general-purpose differentiable computation framework for any data expressible as a sequence of tokens.
As of March 2026, the Hugging Face Transformers library hosts over one million model checkpoints, supporting PyTorch 2.4+ and Python 3.10+ (HF Docs). The library moved to v5 with a weekly release cadence, and the transition introduced breaking changes – removed long-due deprecations and simplified APIs (HF Blog). If you are upgrading from v4, expect refactoring.
Every major model in production today – GPT-5.4, Claude 4.5 Sonnet, Gemini 3.1, Llama 4 – runs on transformer architecture. The open question is not whether transformers work. It is whether their computational cost will force a successor.
What Quadratic Scaling Costs You
Self-attention computes a score for every pair of tokens. For a sequence of length n, that is n-squared operations per layer. Double the context length, quadruple the compute. The same mechanism that makes transformers powerful makes them expensive at scale.
If your input is short – a few hundred tokens – the quadratic cost is negligible. If your input is a full codebase, a legal corpus, or a multi-document research synthesis, that scaling becomes the engineering constraint that defines your architecture choices.
Techniques like FlashAttention, sparse attention, and sliding window attention reduce the constant factor or approximate the full computation. They do not change the underlying scaling law.
State Space Model architectures like Mamba offer linear complexity as an alternative. As of early 2026, hybrid approaches are an active research area – architectures that use self-attention in select layers and SSM-style linear computation elsewhere (Mamba-360 Survey). The hybrid strategy treats attention as expensive-but-precise and SSMs as cheap-but-approximate, mixing them where each excels.
If the task demands precise retrieval across the entire context – legal search, multi-document question answering – full self-attention still outperforms approximations. If the task is streaming generation or ultra-long-context processing, SSM hybrids are increasingly competitive. If you double your context window and your latency quadruples, the architecture is telling you something about the nature of your problem.
Rule of thumb: Full self-attention is worth the cost when every token might be relevant to every other token. When context is local or sequential, cheaper alternatives exist.
When it breaks: Self-attention degrades when context windows exceed the model’s training distribution. A model trained on shorter contexts and extended via positional interpolation will attend to distant tokens – but the quality of that attention drops. Positional encoding distortion, not the attention mechanism itself, is usually the failure mode. Fine Tuning on longer contexts helps but does not eliminate the distribution shift entirely.
The Data Says
The transformer replaced recurrence with parallelism and sequential hidden states with direct pairwise computation between every token in a sequence. That single structural choice – abolishing sequential dependency – enabled the scaling that drives every major language model in production today. The architecture’s limitation is its own strength turned against it: quadratic attention cost grows with context length, and no approximation has fully eliminated that trade-off.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors