What Is Training Data Quality and How It Determines Model Performance

ELI5
Training data quality is how correct, clean, and relevant your examples are before a model ever sees them. A model can only learn the patterns its data contains — clean data raises the ceiling, noisy data caps it.
Two teams train the same architecture on the same task. Same optimizer, same learning rate, same parameter count. One model lands at production accuracy. The other plateaus ten points lower and refuses to budge no matter how long it trains. The architectures are identical. The gap lives entirely in the data each model was fed — and most of it traces to errors nobody ever looked for.
The instinct, when a model underperforms, is to reach for the model. Add layers. Tune the learning rate. Swap the optimizer. That instinct is usually wrong. The most common reason a model fails to learn a pattern is that the pattern was never cleanly present in the data to begin with — or was actively contradicted by mislabeled examples teaching the opposite lesson.
The Ceiling You Can’t Train Past
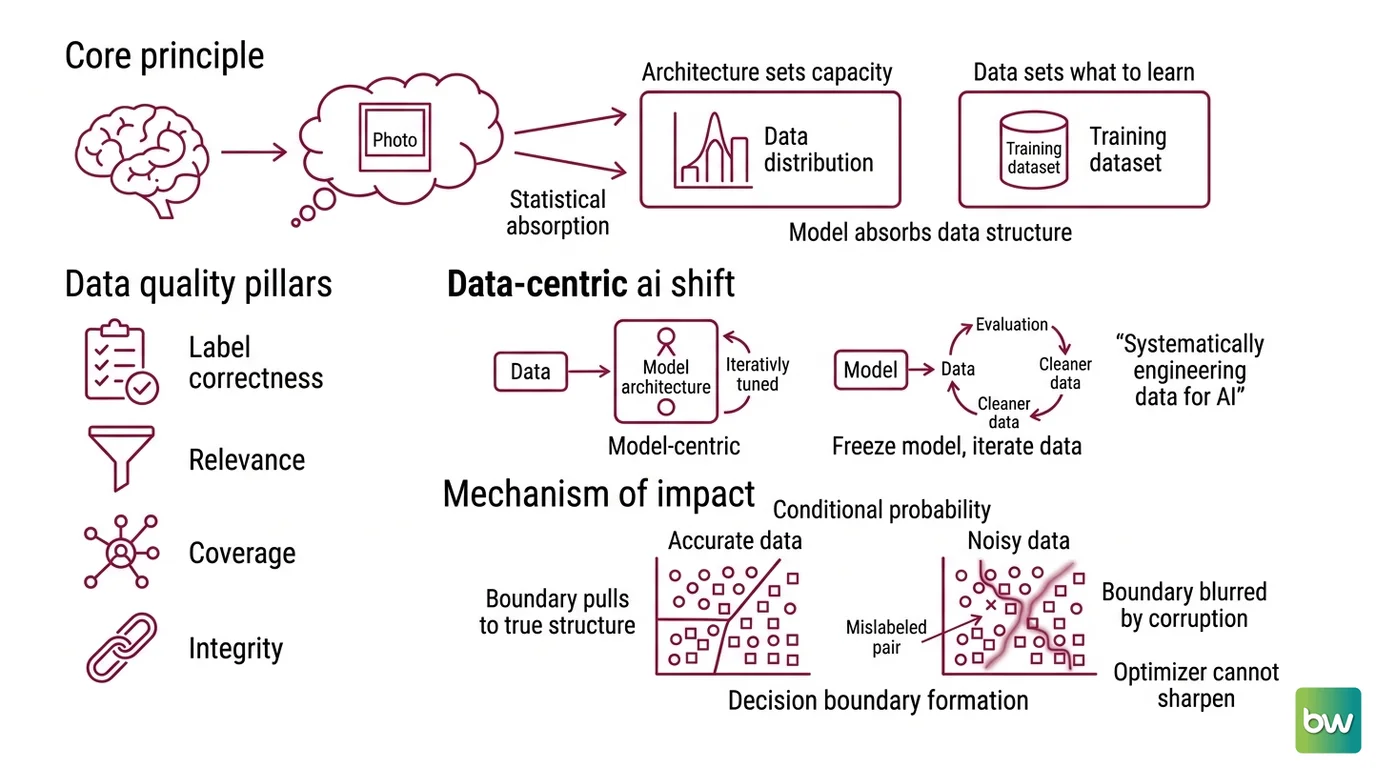
A model is a function that absorbs the statistical structure of its training set. It has no channel to truth outside that set. If the data says a photo of a husky is labeled “wolf” four hundred times, the model learns that association faithfully, because faithful absorption is the only thing gradient descent knows how to do. The architecture sets the model’s capacity to learn. The data sets what there is to learn.
What is training data quality in machine learning?
Training data quality is the degree to which a dataset is correct, relevant, representative, and clean enough for a model to extract the intended pattern. It is not one property but several measurable ones: label correctness (do the annotations match reality?), relevance (do the examples match the deployment distribution?), coverage (are the edge cases present?), and integrity (are there duplicates, leaks, or unknown sources corrupting the signal?).
Andrew Ng named the discipline that takes this seriously: Data-Centric AI, which he defines as “the discipline of systematically engineering the data needed to build a successful AI system” (IEEE Spectrum). The framing inverts a decade of habit. Instead of freezing the data and iterating on the model, you freeze a reasonable model and iterate on the data. For most production systems, the second loop moves the accuracy needle further.
Not a tuning problem. A data problem.
How does training data quality determine model performance?
The mechanism is conditional probability. A supervised model estimates P(label | input) from the joint distribution of its examples. Every training pair shifts that estimate. A correct pair pulls the decision boundary toward the true structure; a mislabeled pair pulls it away. With enough noise, the boundary the model converges to is a blurred average of the real signal and the corrupted signal — and no amount of additional training sharpens it, because the optimizer is minimizing loss against the labels it was given, not against reality.
This produces the most counterintuitive consequence in the field: adding more data can lower performance if that data carries label noise. Volume amplifies whatever signal is present. When the signal is clean, scale helps. When the signal is contaminated, scale entrenches the contamination. The relationship between data quantity and model quality is not monotonic — it is gated by data quality, and the gate is easy to miss because the loss curve still looks like it is converging. It is converging. Just toward the wrong target.
There is a second, subtler channel: label noise corrupts your evaluation as well as your training. If the test set contains mislabeled examples, a model that correctly classifies them gets penalized for being right. You can be debugging a model that is already outperforming your own ground truth — and you would never know, because the metric is lying in proportion to the noise.
Four Failure Modes Hiding in Your Dataset
Data quality is not a single dial. It decomposes into distinct failure modes, each with its own detection method and its own effect on the learned function. Understanding them separately is what turns “the data is bad” into something you can actually fix.
What are the key dimensions of data quality for ML training?
The dimensions that matter most in practice fall into four groups.
| Dimension | Failure mode | Effect on the model |
|---|---|---|
| Label correctness | Label Noise — annotations that disagree with reality | Decision boundary pulled toward wrong target; evaluation metrics corrupted |
| Relevance & coverage | Distribution mismatch; missing edge cases | Strong on average, brittle on the cases that matter at deployment |
| Integrity | Duplicates and train/test leakage | Inflated benchmark scores that collapse in production |
| Traceability | Unknown source, license, or collection method | Hidden bias and compliance risk you cannot audit after the fact |
The first dimension, label correctness, is where the largest gains usually hide, because label errors are invisible to the loss function — the model treats every label as ground truth by construction. Confident Learning is the framework that made these errors findable. Introduced by Northcutt, Jiang, and Chuang (arXiv) and published in the Journal of AI Research in 2021 (JAIR), it estimates the joint distribution between the labels you have and the labels you should have, using the model’s own predicted probabilities to flag examples whose given label is statistically improbable. Crucially, it makes no assumption that errors are random — it models which classes get confused for which, the way “fox” and “wolf” trip up an annotator more than “fox” and “airplane.”
The integrity dimension is where benchmark scores quietly inflate. Data Deduplication removes near-identical examples that would otherwise leak between your training and test splits — and when they leak, the model gets graded on data it effectively memorized, producing a benchmark number that evaporates the moment it sees genuinely new input. The traceability dimension — Data Provenance — is the record of where each example came from, how it was collected, and under what license. Without it, you cannot answer the question that decides whether a model is trustworthy: what is actually in here?
How to Find the Errors You Can’t See
Knowing the failure modes is half the work. The other half is tooling that surfaces problems at the scale of millions of examples, where manual review is hopeless. Three approaches anchor the practice, and they attack different parts of the problem.
For label errors, Cleanlab packages confident learning into something you point at an existing model. It works with any classifier that outputs class probabilities — PyTorch, scikit-learn, XGBoost — and returns a ranked list of examples most likely to be mislabeled (Cleanlab’s GitHub repository). The workflow is the inversion Ng described: train a quick baseline, let the tool rank suspect labels, fix the worst offenders, retrain. The model becomes a microscope for inspecting its own training set.
When labels do not yet exist at scale, Weak Supervision offers a different path. Rather than hand-labeling, you write labeling functions — noisy, heuristic rules — and let a model reconcile their disagreements into probabilistic labels. Snorkel pioneered this approach in “Snorkel: Rapid Training Data Creation with Weak Supervision” (VLDB), demonstrating that dozens of imperfect rules, combined statistically, can approximate hand-labeling at a fraction of the cost. As of 2026, the open-source library is largely in maintenance mode while active development has moved to the company’s commercial platform — but the programmatic-labeling idea it introduced is now standard practice.
The third lever is choosing which data to label at all. Active Learning prioritizes the examples a model is most uncertain about, on the logic that an example near the decision boundary teaches more than the thousandth confident example of the same class. Lightly (version 1.5.23, per Lightly Docs) applies this to images and video, combining self-supervised representations with curation to surface the most informative subset of a large unlabeled pool. The shift is from labeling everything to labeling what matters.
What Clean Data Predicts
Once you see data quality as the function that sets the learnable ceiling, several behaviors become predictable rather than mysterious:
- If your model plateaus well below the architecture’s known capacity, suspect label noise before you suspect the architecture.
- If your benchmark score is excellent but production accuracy is poor, suspect train/test leakage from duplicates before you suspect distribution drift.
- If your model is strong on average but fails a specific subgroup, suspect coverage gaps in the data for that subgroup, not a flaw in the loss function.
- If two models with identical configs diverge in accuracy, the difference is almost always in the data, and it is measurable.
Rule of thumb: before you change the model, audit the labels — a few hours of confident-learning review often beats a week of hyperparameter search.
When it breaks: data-centric methods assume your detection signal is more reliable than your noise. When label errors are systematic rather than random — every annotator shares the same misconception, so the “correct” majority is itself wrong — the model’s predicted probabilities reinforce the error instead of exposing it, and automated cleaning can entrench the very mistake you were hunting.
The Data Says
A model is a faithful student of whatever it is shown; it cannot learn a pattern its data does not contain, and it cannot unlearn a contradiction its labels insist on. Training data quality is the ceiling on performance, not a preprocessing footnote — which is why systematic data engineering frequently outperforms another round of model tuning. Fix the data, and the same architecture quietly clears the bar it had been stuck under.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors