What Is Toxicity and Safety Evaluation and How Guard Models Score Harmful AI Outputs
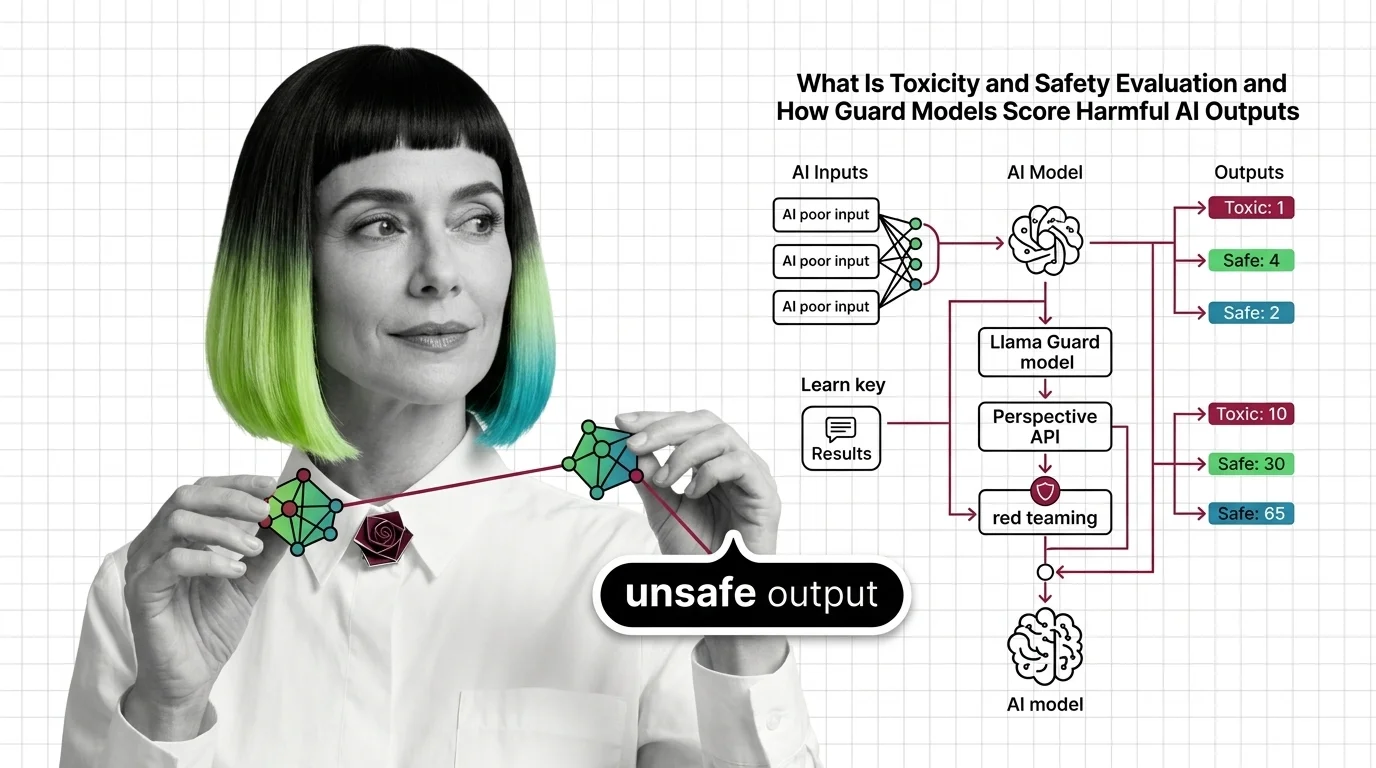
Table of Contents
ELI5
Toxicity and safety evaluation is a set of methods — classifiers, benchmarks, and adversarial tests — that score AI outputs for harmful content before they reach users.
The model passed every safety benchmark. Then a user switched to Haitian Creole, and the guardrails dissolved — the classifier returned clean scores on text that any bilingual speaker would have flagged immediately. That failure tells you more about how toxicity evaluation actually works than the passing scores ever did. The classifiers are not measuring meaning. They are measuring statistical proximity to patterns they were trained to recognize, and where those patterns thin out, the safety boundary vanishes.
What Blocklists Cannot See
Most people carry a simple mental model of toxicity detection: a blocklist of slurs and explicit threats, pattern-matched against output text. That model survived longer than it should have, partly because early content filters actually worked this way.
The problem is that explicit toxicity — the kind a blocklist catches — accounts for a shrinking fraction of real-world harm. The Toxigen dataset, containing 274K machine-generated statements across 13 minority groups, found that 98.2% of its toxic examples were implicit (Microsoft Research). No slurs. No direct threats. Just statements carrying harm through framing, implication, and selective emphasis.
A keyword filter sees nothing wrong. A Safety Classifier trained on distributional patterns sees everything it was taught to see — and nothing beyond that training distribution. The gap between those two capabilities is where most harm hides.
The Decision Space of Harm
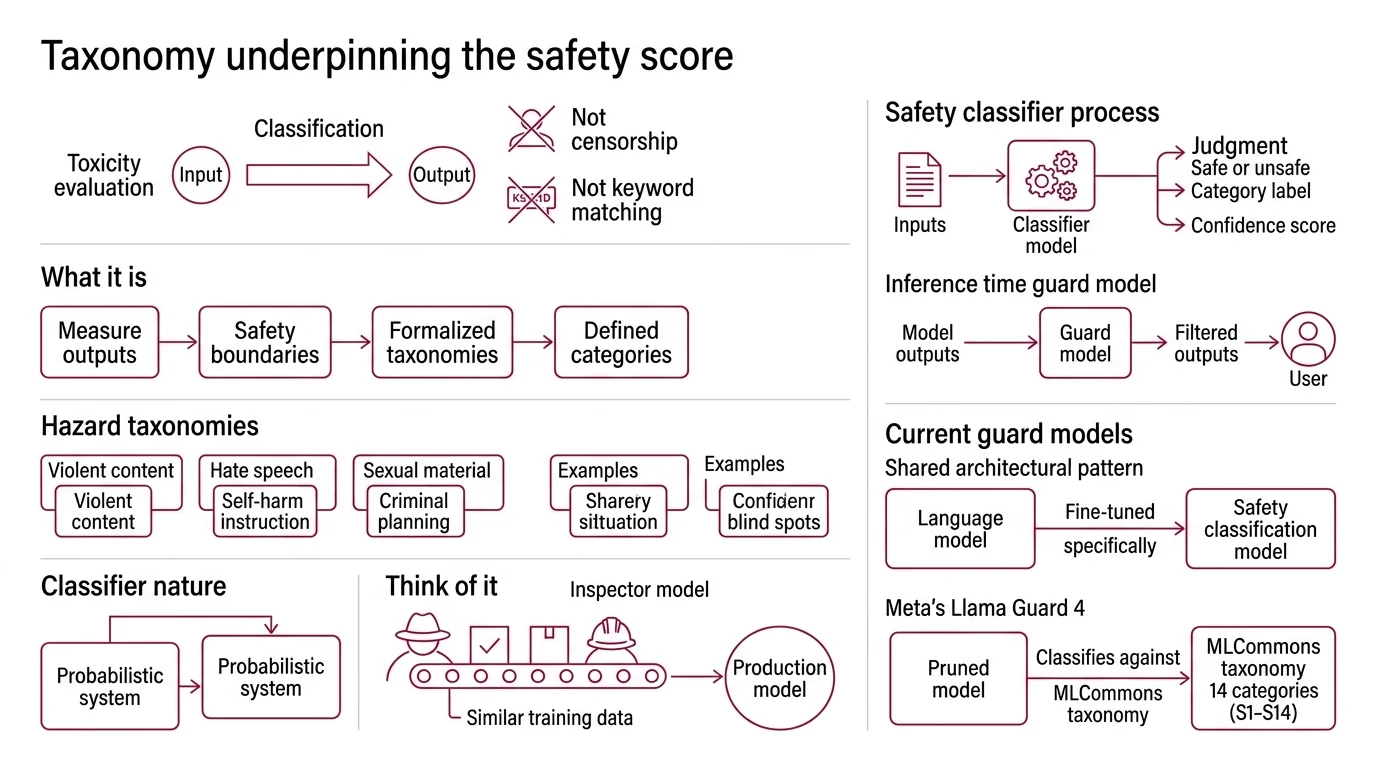
A safety classifier does not decide whether text is “toxic” the way a human reads for tone. It projects text into a learned vector space and measures distance from decision boundaries shaped by labeled examples. Those boundaries are organized by a harm taxonomy — and the taxonomy’s design determines what the classifier can even perceive.
What is toxicity and safety evaluation in generative AI
Toxicity and safety evaluation is the discipline of scoring generative AI outputs — and inputs — against structured harm taxonomies. The scoring happens across three distinct layers: pre-deployment benchmarking against known attack datasets, runtime classification of live traffic, and adversarial stress testing that probes for failure modes nobody anticipated.
The taxonomy drives everything downstream. Llama Guard 4 uses the MLCommons hazard taxonomy with 14 categories (S1–S14), spanning violent crimes, child safety, elections, and defamation (Meta on Hugging Face). Each category defines a region in the classifier’s decision space, and operators set per-category thresholds based on their risk tolerance — a children’s platform and a journalism tool will draw very different lines through the same geometry.
The classifier does not understand harm. It measures distance from labeled examples of harm. When those examples are well-distributed and the taxonomy is well-designed, the system approximates human judgment with useful precision. When the examples are sparse — implicit harm, culturally specific context, underrepresented languages — the geometry breaks down. The boundaries stop tracking actual risk, and the scores become a measure of the classifier’s ignorance rather than the text’s safety.
Two Architectures, One Equation
The field splits along an architectural boundary that determines what a classifier can see and what it costs to run. The trade-off between these two designs shapes every deployment decision in Content Moderation.
How do AI safety classifiers like Llama Guard and Perspective API detect toxic content
Token-level probability models and LLM-based guard models represent two fundamentally different bets on the same problem.
Perspective API scores text by predicting the probability that a human annotator would label it toxic. It outputs a value between 0 and 1 across attributes including TOXICITY, SEVERE_TOXICITY, IDENTITY_ATTACK, INSULT, PROFANITY, and THREAT, supporting over 18 languages (Perspective API). At its peak, the API handled hundreds of millions of requests daily across platforms including the New York Times, Reddit, and Wikipedia. But Perspective API is a legacy service — it sunsets on December 31, 2026, with no migration path from Google.
LLM-based guard models work differently. Instead of scoring isolated text spans, they process the full conversational context — the user prompt and the model response together — and classify the exchange against a structured taxonomy. Llama Guard 4, a 12B-parameter dense model pruned from Llama 4 Scout, evaluates both text and images natively, covers seven non-English languages, and achieves 61% English F1 — an 8-point improvement over Llama Guard 3 (Meta on Hugging Face).
The architectural difference is not academic. Token-level models are fast but context-blind; they score “kill the process” identically whether it appears in a terminal command or a death threat. LLM-based classifiers read the full exchange and can distinguish intent — but they pay for that awareness in latency and compute.
Anthropic’s Constitutional Classifiers pushed this trade-off to its logical conclusion: jailbreak success rates dropped from 86% to 4.4%, with only a 0.38% increase in false refusals — at 23.7% compute overhead (Anthropic Research). Compute for safety is the central economic question of the field right now.
OpenAI’s gpt-oss-safeguard, released October 2025, brought open-weight reasoning safety models at 120B and 20B parameters under Apache 2.0 (Help Net Security). Independent benchmarks remain limited as of early 2026, but the direction is unmistakable: safety classifiers are becoming shared infrastructure rather than proprietary differentiators.
The Adversary’s Advantage
Runtime classifiers defend against known patterns. Red Teaming For AI exists because the dangerous failures are the unknown ones — inputs that exploit gaps between what the classifier learned and what the harm taxonomy intended to cover.
How does automated red teaming test LLM safety before deployment
Manual red teaming does not scale. A human tester generates dozens of attack vectors per day; automated systems generate thousands, probing the model’s refusal boundaries from angles a human tester might never consider.
Harmbench standardized this process. Its evaluation, published in early 2024, benchmarked 18 distinct red teaming methods against 33 LLMs and their defenses (arXiv, Mazeika et al.). The framework’s most important finding is not which attacks succeed on which models — it is that attack vectors transfer between models because they share training distributions and architectural patterns. An adversarial prompt crafted against one model frequently breaks another.
The tooling ecosystem reflects this transferability problem. PyRIT (Microsoft), Garak (NVIDIA), Promptfoo, and DeepTeam all automate adversarial probing with different strategies: gradient-based token optimization, semantic paraphrasing, multilingual prompt injection. The OWASP Top 10 for LLM Applications 2025 codifies the risk categories these tools target — prompt injection, data poisoning, excessive agency, and system prompt leakage among the most critical threats.
Automated red teaming does not eliminate these risks. It maps them — producing a topography of the model’s vulnerability surface before users discover it in production. The map is always incomplete, but an incomplete map is better than walking blind.
What the Scores Actually Predict
The if/then logic of safety evaluation seems straightforward until you test it against real failure modes.
If your classifier was trained on explicit toxicity and the attack uses implicit framing, the score reads clean. The system sees nothing to flag because the harm lives in implication, not vocabulary.
If your guard model evaluates text only and harmful content arrives as an image with embedded text, the model is blind to it — unless it supports multimodal input. Llama Guard 4 addresses this gap with native image processing, but most open-weight classifiers remain text-only.
If your red teaming covers English attack vectors but the model serves multilingual users, the vulnerability surface you mapped is a fraction of the actual surface. The geometry you tested is not the geometry your users inhabit.
Safety evaluation is sometimes conflated with Hallucination detection, but the failure modes are distinct: a hallucinating model generates confident fabrications about facts; a model that fails safety evaluation generates content harmful to people. The overlap exists but is narrower than intuition suggests, and conflating the two leads to classifiers optimized for the wrong objective.
Rule of thumb: A safety score is only as good as the taxonomy it was trained on and the distribution it was tested against. If either is narrow, the score is a floor, not a ceiling.
When it breaks: Safety evaluation fails most predictably at the intersection of implicit harm and low-resource languages — where labeled training data is sparse, annotator agreement is low, and the taxonomy was designed by people who do not speak the language. The classifier returns low toxicity scores not because the text is safe, but because it lacks the geometry to represent the harm.
Security & compatibility notes:
- Perspective API (BREAKING): Service ends December 31, 2026. No migration tools provided by Google. Teams dependent on it must transition to alternative classifiers before that date.
- Llama Guard 4-12B (WARNING): Deprecated on Groq as of February 2026 in favor of gpt-oss-safeguard-20b. Meta continues to maintain the model directly. Llama Guard 3-8B was deprecated May 2025 in favor of Llama Guard 4.
The Data Says
The classifiers are improving — multimodal, multilingual, architecturally aware of conversational context. But the adversarial surface grows faster than the defenses can map it. That asymmetry defines the field: safety evaluation is not a problem that gets solved once. It is a boundary that gets mapped with increasing precision, always knowing the territory on the other side keeps shifting.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors