What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Table of Contents
ELI5
Tokenizer architecture is the system that chops raw text into smaller pieces called tokens before a language model processes them. Different algorithms — BPE, WordPiece, Unigram — decide where to cut.
Type the word “unhappiness” into GPT-4o and it costs you one token. Type the same word into BERT and it fractures into three fragments: un, ##happi, ##ness. Same English word, same meaning — but two completely different mathematical objects arrive at the neural network’s front door. The model never sees the word you typed. It sees whatever the tokenizer decided to hand it.
That decision — where to split, how many pieces, which alphabet of fragments to draw from — is not preprocessing trivia. It is the first architectural choice that shapes everything downstream.
The Gate That Fires Before the Neural Network
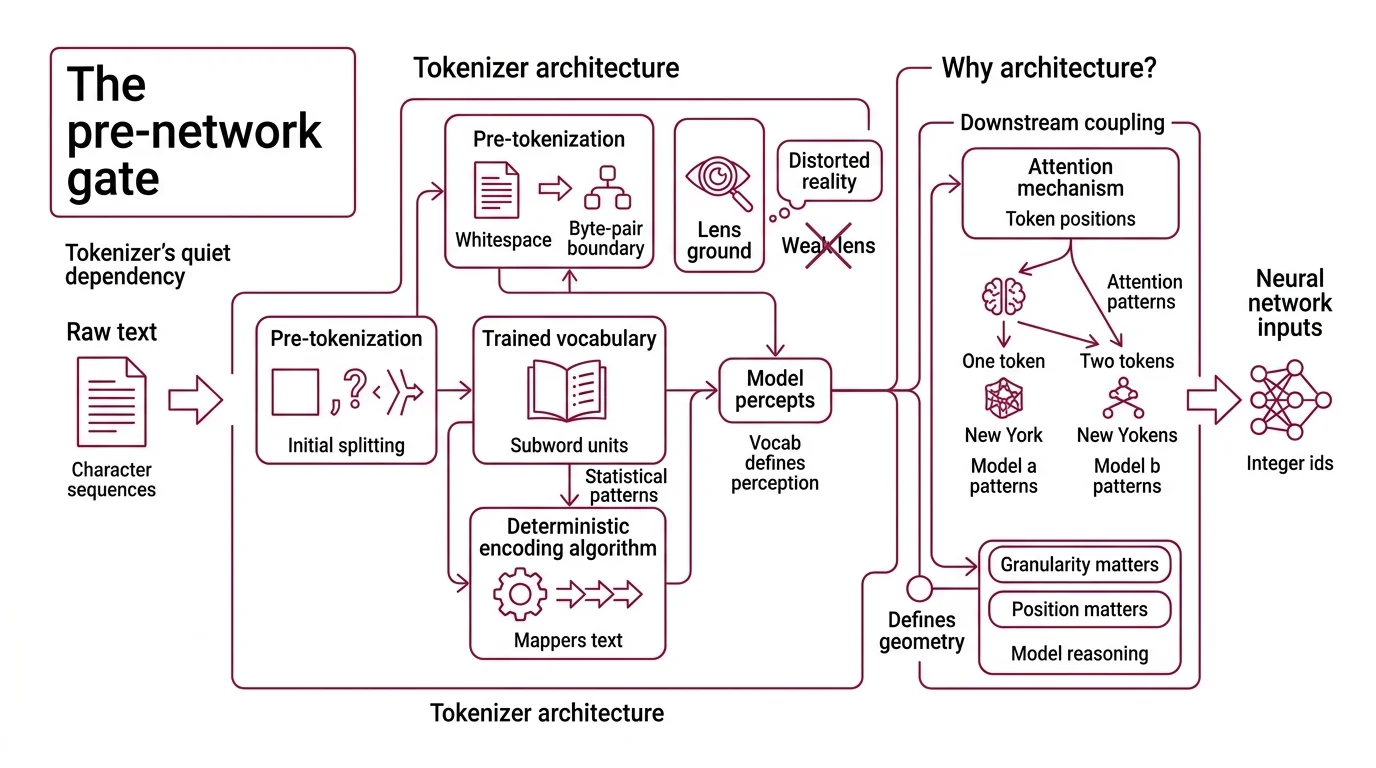
Every Transformer Architecture begins with the same quiet dependency: a tokenizer that converts raw character sequences into integer IDs. Not words. Not characters. Subword units — fragments determined by statistical patterns in a training corpus. The architecture of that tokenizer defines the model’s perceptual vocabulary, and no amount of scale in the layers above can compensate for a vocabulary that splits the wrong things.
What is tokenizer architecture in large language models?
Tokenizer architecture is the full system — algorithm, vocabulary table, and preprocessing rules — that maps raw text into sequences of discrete token IDs. Those IDs are the only input the model ever sees.
Think of it as a lens prescription. The neural network is the eye; the tokenizer is the lens ground in front of it. A poorly ground lens doesn’t make the eye weaker. It makes the eye see a distorted version of reality, and the eye has no way to know.
In modern Subword Tokenization systems, the architecture has three interlocking components: a pre-tokenization step that applies initial splitting rules (whitespace, punctuation, byte-pair boundaries), a trained vocabulary of subword units, and a deterministic encoding algorithm that maps any input string to a token sequence using that vocabulary. The algorithm family — BPE, WordPiece, or Unigram — determines how the vocabulary was built and how encoding proceeds at inference time.
What makes this architectural rather than cosmetic is the downstream coupling. The Attention Mechanism operates on token positions. If “New York” is one token in model A and two tokens in model B, the models construct fundamentally different attention patterns for the same phrase. Position matters. Granularity matters. The tokenizer defines the geometry the model reasons over.
What should you understand before learning tokenizer architecture?
Tokenizer architecture sits at the intersection of several foundational concepts. You need a working model of Tokenization itself — the general idea that text must be discretized before a neural network can process it. Beyond that, the algorithms make more sense when you understand why Decoder Only Architecture models (GPT, Llama) and Encoder Decoder Architecture models (T5, BART) inherited different tokenizer traditions, and why those traditions are now converging.
The practical side helps too. Tiktoken, OpenAI’s fast BPE tokenizer, is the tool most developers encounter first — it makes the abstract concrete. And Glitch Tokens, those strange vocabulary entries that cause models to behave erratically, are the most visceral proof that tokenizer architecture has consequences the model cannot fix on its own.
Three Algorithms for Cutting Language Into Computable Pieces
The three dominant subword algorithms — BPE, WordPiece, and Unigram — share a goal but disagree on method. Each constructs a vocabulary of subword units. Each balances vocabulary size against coverage. But they build that vocabulary through opposing strategies, and those strategies produce measurably different token distributions.
How do BPE, WordPiece, and Unigram tokenizers convert raw text into subword tokens?
Byte Pair Encoding starts from the bottom. The initial vocabulary is individual characters — or, in byte-level BPE, the 256 possible byte values, which eliminates the unknown-token problem entirely (HuggingFace Docs). The algorithm scans the training corpus, finds the most frequently co-occurring adjacent pair of tokens, merges them into a single new token, and repeats. After 50,000 merges, GPT-2’s vocabulary contained 50,257 tokens: 256 byte tokens, 50,000 learned merges, and one end-of-text token (HuggingFace Docs). The process is greedy — frequency alone drives each merge.
The elegance is also the limitation. BPE’s frequency criterion is surface-level; it captures what appears often but not what separates meaning. The word “lower” might merge into a single token simply because it appears frequently, even though the morphemes “low” and “-er” carry compositional semantics that a more linguistically aware split would preserve.
Not coincidence. A design trade-off.
WordPiece makes the merge decision differently. Instead of raw frequency, it scores each candidate merge by how much the merge would increase the training data’s log-likelihood: score(ab) = freq(ab) / (freq(a) * freq(b)) (HuggingFace Docs). This means WordPiece prefers merges where the combined unit is surprisingly frequent relative to its parts — essentially a mutual-information criterion. BERT, DistilBERT, and Electra use this approach. One complication worth noting: Google never open-sourced the WordPiece training algorithm; published descriptions are reconstructions from the literature, and the internal implementation may differ.
WordPiece encodes unknown words by splitting left-to-right, finding the longest prefix in the vocabulary, and marking continuation fragments with ##. The string “tokenization” might become token, ##ization — if those subwords exist in the vocabulary.
Unigram inverts the entire philosophy. Where BPE builds up from characters and WordPiece builds up from statistically justified merges, Unigram starts with an oversized vocabulary — often hundreds of thousands of candidate subwords — and prunes downward. At each step, it removes the tokens whose loss would increase the corpus likelihood the least (Kudo 2018). The result is a vocabulary where each surviving token earned its place by being irreplaceable.
Unigram also introduces something neither BPE nor WordPiece offers: probabilistic segmentation. A single input string can have multiple valid tokenizations, each with a computed probability. During training, this subword regularization acts as a form of data augmentation — the model sees different segmentations of the same word across epochs. T5, BigBird, and Pegasus use Unigram via SentencePiece (HuggingFace Docs).
| Algorithm | Direction | Merge Criterion | Segmentation | Used By |
|---|---|---|---|---|
| BPE | Bottom-up | Highest frequency pair | Deterministic | GPT-2/3/4, GPT-4o, Llama 3, Mistral |
| WordPiece | Bottom-up | Max log-likelihood gain | Deterministic (left-to-right) | BERT, DistilBERT, Electra |
| Unigram | Top-down (prune) | Min likelihood loss on removal | Probabilistic | T5, BigBird, Pegasus |
Inside the Pipeline That Runs Before Attention Ever Fires
An algorithm alone is not a tokenizer. The full pipeline has stages that run in sequence, and understanding each stage explains behaviors that otherwise look like bugs.
What are the main components of a tokenizer pipeline: pre-tokenization, vocabulary, merge rules, and byte fallback?
Pre-tokenization applies rule-based splitting before the subword algorithm touches the input. GPT-2’s pre-tokenizer, for instance, uses a regex pattern that splits on whitespace boundaries, punctuation, and digit transitions. This determines the atoms the subword algorithm can merge — it will never create a token that spans a pre-tokenization boundary. Different regex patterns produce different atoms; different atoms produce different vocabularies; different vocabularies produce different model behavior. It’s turtles all the way down, except the turtles are regular expressions.
The vocabulary table maps every known subword string to an integer ID. This table is static after training. It defines the model’s perception of language in the same way a retinal cell array defines the eye’s perception of color — what isn’t in the table is invisible. Byte-level BPE addresses this by starting from 256 byte values instead of Unicode characters, which guarantees that any byte sequence can be encoded (HuggingFace Docs).
Merge rules (in BPE and WordPiece) are an ordered list that tells the encoder which subword pairs to combine, and in what priority. At encoding time, the algorithm iteratively applies the highest-priority applicable merge until no more merges are possible. The order matters: changing merge priority changes the resulting tokenization even with an identical vocabulary. In Unigram, there are no merge rules — instead, a Viterbi search finds the most probable segmentation under the trained unigram language model.
Byte fallback is the safety net. When a character isn’t in the vocabulary and the tokenizer isn’t byte-level, it must handle the unknown. Some tokenizers emit an [UNK] token and destroy information. SentencePiece offers an alternative: it falls back to UTF-8 byte representations, encoding any character as a sequence of byte tokens. This is how SentencePiece achieves language-agnostic coverage — it treats whitespace as an explicit ▁ character and handles any script without language-specific preprocessing (Google’s GitHub).
What Your Vocabulary Table Predicts About Model Failures
The implications run in one direction: from tokenizer to model, never the reverse.
If you switch from a character-level vocabulary to a BPE vocabulary with tens of thousands of merges, expect the same text to compress into fewer tokens — meaning more text fits in the context window, but each token carries more ambiguity. If you expand the vocabulary further (as with GPT-4o’s o200k_base encoding), you gain even more compression but increase the embedding matrix size proportionally. Every vocabulary expansion is a bet that the compression benefit outweighs the parameter cost.
If a language is underrepresented in the training corpus, expect its words to fragment into many small tokens. A five-character Hindi word might consume several tokens while a five-character English word consumes one. The model doesn’t “know” Hindi less — it sees Hindi through a lower-resolution lens. The quality ceiling is set before the first attention layer fires.
If you encounter a model producing bizarre outputs for specific inputs — nonsense completions, refusal to engage, repetitive loops — check the tokenizer first. Glitch tokens are vocabulary entries that appeared in training data with pathological frequency patterns, creating attractors in embedding space that distort nearby representations. The model isn’t broken. The vocabulary table contains a trap.
Rule of thumb: When debugging unexpected model behavior, inspect the tokenization before inspecting the model. Run the text through tiktoken (v0.12.0, OpenAI’s GitHub) or HuggingFace’s tokenizers library (v0.22.2, PyPI) and count the tokens. If the count surprises you, the model was surprised first.
When it breaks: Tokenizers fail at distribution boundaries — languages, scripts, or domains absent from the training corpus produce fragmented, high-token-count encodings that degrade model performance proportionally. No amount of fine-tuning fixes a vocabulary that doesn’t contain the right subwords.
The Data Says
Tokenizer architecture is not a preprocessing detail. It is the first model of language that the neural network inherits — a fixed lens that determines resolution, coverage, and failure modes before any parameter learning begins. BPE, WordPiece, and Unigram each embody a different philosophy of compression, and that philosophy propagates through every attention layer above.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors