What Is the Transformer Architecture and How Self-Attention Really Works
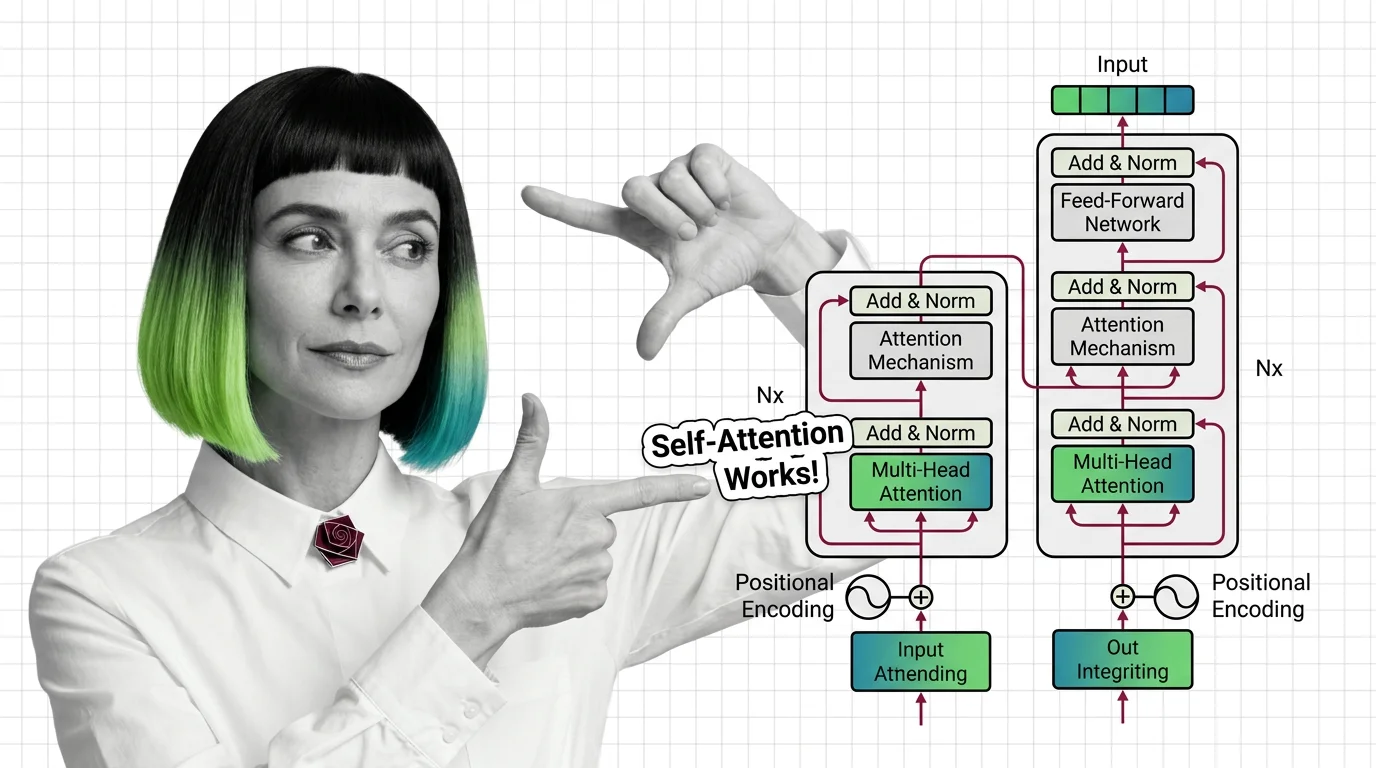
Table of Contents
ELI5
A transformer lets every word in a sentence look at every other word simultaneously, deciding which relationships matter most — through math, not memorization.
The Misconception
Myth: Transformers “understand” language the way humans do — they read sequentially and build meaning word by word.
Reality: Transformers process all tokens in parallel. There is no sequential reading. Each token attends to every other token in a single computational pass, computing relevance scores through linear algebra.
Symptom in the wild: Engineers assume that placing important context “earlier” in the prompt guarantees the model will prioritize it. It won’t — attention weights are position-aware but not position-loyal.
How It Actually Works
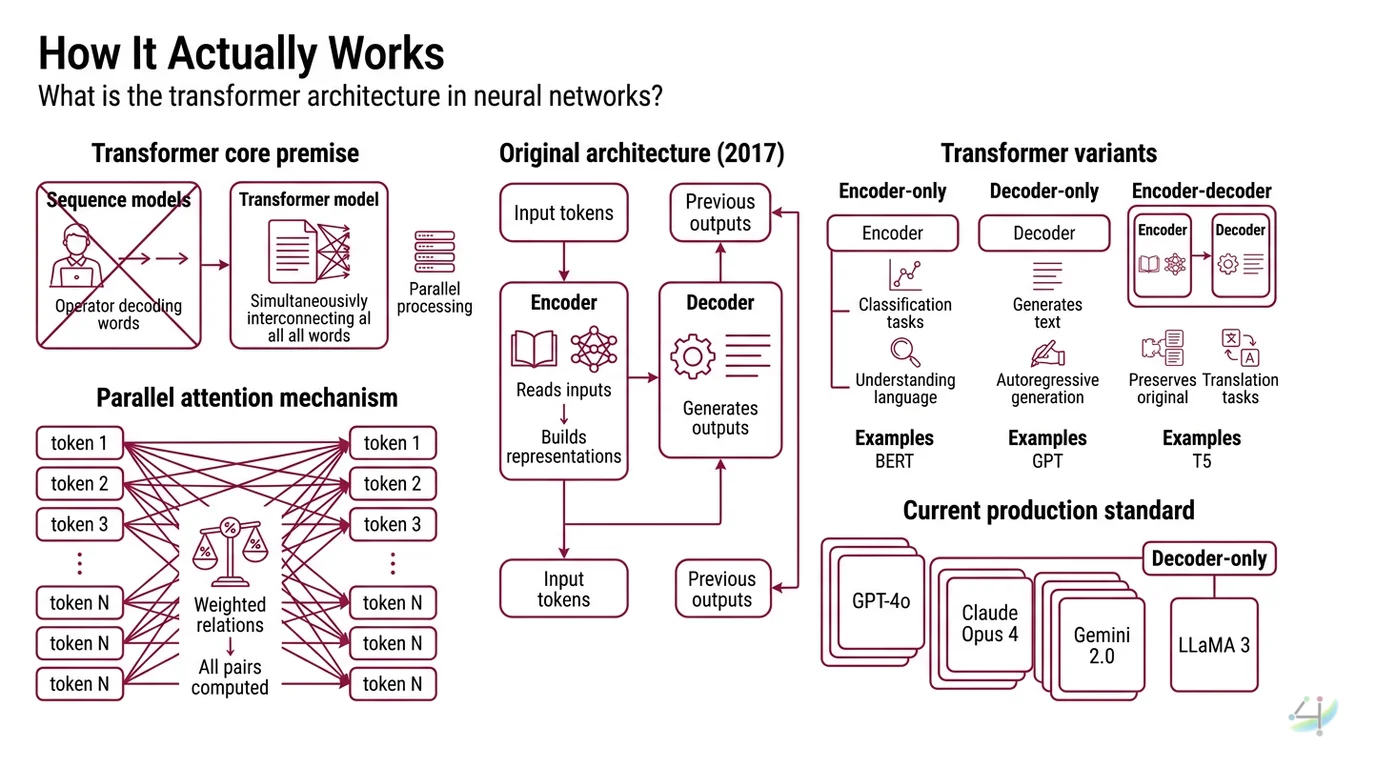
The transformer is a specific neural network architecture built on one radical premise: you can replace recurrence entirely with attention. Before 2017, sequence models processed tokens one after another — each step waiting on the previous one, like a telegraph operator decoding words in strict order. The transformer discards that queue. It processes the entire sequence at once, computing relationships between all token pairs in parallel, as if every word in a paragraph could simultaneously ask every other word: “How much should I care about you?”
That question — weighted, scaled, and answered through matrix multiplication — is the mechanism that changed everything.
What is the transformer architecture in neural networks?
The transformer is an Encoder Decoder architecture introduced by Vaswani et al. in June 2017 in “Attention Is All You Need,” presented at NeurIPS 2017 (Vaswani et al.). The paper was a machine translation paper. Not a language model paper. Not an AGI manifesto. A translation paper that happened to describe the most consequential architectural pattern in modern AI.
The original design has two halves: an encoder that reads input tokens and builds contextual representations, and a decoder that generates output tokens one at a time, attending both to its own previous outputs and the encoder’s representations.
But here is where the architecture’s own evolution becomes revealing.
Three variants emerged from that original blueprint. Encoder-only models like BERT strip away the decoder; they excel at classification and understanding tasks. Decoder-only models like GPT strip away the encoder; they generate text autoregressively. Encoder-decoder models like T5 preserve the original structure (Hugging Face Docs). Every frontier model in production as of early 2026 — GPT-4o, Claude Opus 4, Gemini 2.0, LLaMA 3 — uses the decoder-only variant.
Not the full architecture. Half of it.
The encoder was the first casualty of scale.
How does self-attention work in transformers?
Self-attention is the core operation. Every other component in the transformer exists to support, regulate, or refine what self-attention computes.
The mechanism works through three learned projections. For each token in the sequence, the model computes three vectors: a Query (Q), a Key (K), and a Value (V). Think of it as a library retrieval system — the Query is the question a token asks, the Key is the label each other token advertises, and the Value is the actual information that gets returned when a match is found.
The attention score between any two tokens is the dot product of their Query and Key vectors, scaled by the square root of the key dimension: softmax(QK^T / sqrt(d_k))V (Dive into Deep Learning). That scaling factor — sqrt(d_k) — prevents dot products from growing so large that the softmax collapses into a near-one-hot distribution, which would effectively make the model attend to only one token while ignoring the rest.
The softmax converts raw scores into a probability distribution. The output for each token is a weighted sum of all Value vectors, where the weights are those attention probabilities.
This is not metaphor. This is geometry. Each token’s representation becomes a point in a high-dimensional space, and self-attention recalculates that point’s position based on its relationship to every other point in the sequence.
Every inference pass. Every layer. Every token — repositioned by context.
What are the key components of a transformer model?
Self-attention alone would collapse into a single-perspective bottleneck. Multi-head attention solves this. Instead of computing one set of Q, K, V projections, the model runs h parallel attention heads, each with independent learned weight matrices W_q, W_k, W_v. The outputs are concatenated and projected through a final matrix W_o (Dive into Deep Learning).
Each head learns to attend to different relationship types. One head might track syntactic dependency; another might track coreference; a third might capture semantic similarity. The model does not decide in advance what each head should learn — the training process discovers useful attention patterns through gradient descent.
Beyond attention, transformers rely on several structural components:
Feed-forward layers sit after each attention block — two linear transformations with a nonlinear activation between them. These are where the model stores factual knowledge, performing the pattern-matching that attention alone cannot do.
Layer normalization stabilizes training by normalizing activations within each layer, preventing the signal from degrading as it passes through dozens or hundreds of stacked blocks.
Positional encoding injects sequence-order information that attention itself cannot capture — since the mechanism is permutation-invariant without it. The original sinusoidal encoding from the 2017 paper has been largely superseded; production models now predominantly use RoPE (Rotary Position Embedding), adopted by LLaMA 3, Mistral, and Gemma, while ALiBi (Attention with Linear Biases) offers superior extrapolation to unseen sequence lengths (ICLR 2025 Blog).
Residual connections add the input of each sublayer to its output, creating gradient highways that allow information to flow across deep stacks without vanishing.
The Tokenization step — converting raw text into integer sequences before any of this happens — determines the vocabulary the model can reason over. The Context Window defines the maximum sequence length self-attention can operate on.
What This Mechanism Predicts
- If you increase the number of attention heads without increasing model dimension proportionally, each head’s subspace shrinks — and you may observe attention patterns becoming redundant rather than diverse.
- If your input sequence exceeds the trained context window, the positional encoding extrapolates poorly with older sinusoidal schemes. RoPE and ALiBi mitigate this, but degradation at extreme lengths persists.
- If you apply Fine Tuning to a pretrained transformer, you are adjusting weights that self-attention uses — changing what the model attends to, not the mechanism of attention itself.
What the Math Tells Us
Self-attention’s computational cost scales quadratically with sequence length — O(n^2) for n tokens. This is the fundamental engineering constraint. Double the context window and you quadruple the attention computation. This is why State Space Models like Mamba have gained traction: they achieve linear-time inference and roughly five times the throughput of transformers on long sequences (Mamba-360 Survey). The hybrid approach — Jamba by AI21, combining transformer layers with Mamba blocks in a Mixture Of Experts architecture — suggests the field is moving toward architectures that use attention selectively rather than universally.
The Hugging Face Transformers library hosts over one million model checkpoints across all three architectural variants (Hugging Face Docs), which tells you something about adoption velocity — and about how deeply this architecture has embedded itself into the infrastructure of modern AI.
Rule of thumb: If your task requires understanding relationships between distant tokens — long documents, multi-turn dialogue, code with distant dependencies — transformer attention is the mechanism you need. If your sequences are extremely long and the task is more sequential than relational, linear-time alternatives deserve evaluation.
When it breaks: Quadratic attention cost makes pure transformers impractical beyond certain sequence lengths; models begin dropping information or requiring approximation methods (sparse attention, sliding window) that sacrifice the global context that made attention powerful in the first place.
One More Thing
The original 2017 paper reported BLEU scores of 28.4 on English-to-German and 41.8 on English-to-French translation benchmarks (Vaswani et al.). Those numbers represented state-of-the-art at the time, for a machine translation task. The authors did not predict — could not have predicted — that their architecture would become the substrate for conversational AI, code generation, protein folding, image synthesis, and music composition.
The transformer was not designed to be general-purpose.
It became general-purpose because self-attention turned out to be a universal relationship-computing primitive — applicable to any domain where elements in a sequence influence each other.
That is the difference between an invention and a discovery.
The Data Says
The transformer architecture replaces sequential processing with parallel self-attention — every token computing its relevance to every other token through scaled dot-product geometry. This mechanism is powerful, elegant, and quadratically expensive. The field is not abandoning it; it is learning where attention is essential and where linear alternatives can carry the load. Understanding self-attention is not optional if you work with LLMs — it is the mechanical explanation for why your prompts work, why context windows matter, and why some tasks remain stubbornly difficult.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors