What Is the MMLU Benchmark and How 57 Academic Subjects Test LLM Knowledge
Table of Contents
ELI5
MMLU is a multiple-choice exam spanning 57 academic subjects — from abstract algebra to virology — designed to measure how much factual and reasoning knowledge a large language model absorbed during training.
A model scores 90% on MMLU. Another scores 91%. A third lands at 89%. The press releases write themselves, each claiming a new milestone in machine intelligence. But here is the detail nobody puts in the headline: roughly one in fifteen questions on this benchmark contains an error, and the test was designed for a world where 25% accuracy counted as impressive.
The distance between what MMLU measures and what we assume it measures — that gap is where the interesting science lives.
Fifty-Seven Subjects and One Uncomfortable Assumption
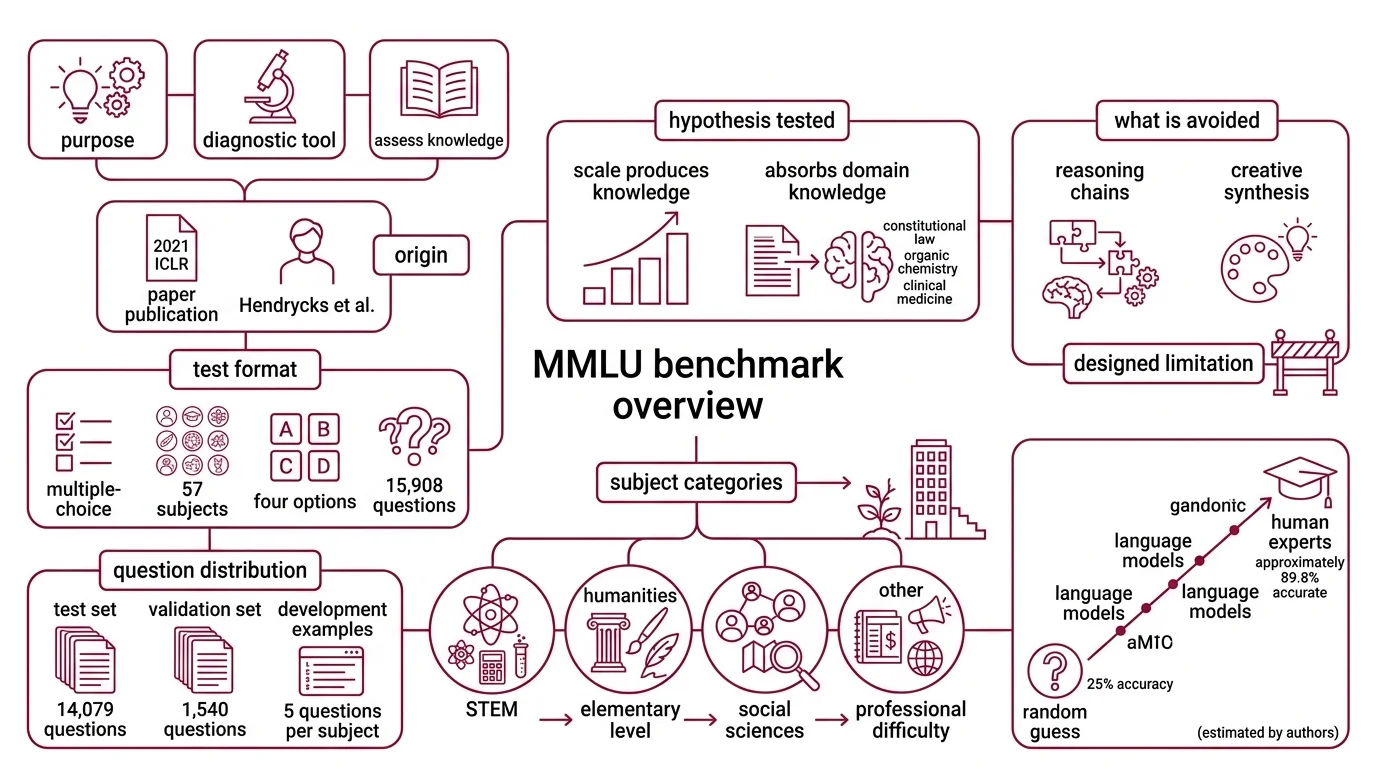
MMLU was not built as a leaderboard. It was built as a diagnostic — a way to answer a question that language model researchers had been sidestepping: does scale alone produce knowledge?
What is the MMLU benchmark for large language models
Massive Multitask Language Understanding — MMLU — is a benchmark introduced by Dan Hendrycks and colleagues in a 2021 ICLR paper (Hendrycks et al.). It presents a model with 15,908 multiple-choice questions across 57 subjects, each offering four answer options: A, B, C, or D. The test set alone contains 14,079 questions, with 1,540 reserved for validation and 5 per subject set aside as development examples (Klu).
The benchmark exists to test a specific hypothesis: that a model trained on sufficient text will absorb not just syntax and style, but actual domain knowledge — from constitutional law to organic chemistry to clinical medicine.
A random guess yields 25% accuracy. Human experts, according to the benchmark creators, average approximately 89.8% — though this figure is an estimate by the authors, not a controlled psychometric study (Wikipedia). The space between those two numbers is where every language model’s performance gets plotted, and where most of the arguments happen.
The design choice that matters most is what MMLU deliberately avoids. It does not test reasoning chains. It does not test creative synthesis. It tests whether a model can select the correct answer from four options across the breadth of human academic knowledge. That constraint is both its power and its ceiling.
What subjects and difficulty levels are included in the MMLU benchmark
The 57 subjects sort into four broad categories: STEM, Humanities, Social Sciences, and Other (Hugging Face). “Other” includes professional accounting, marketing, and global facts — topics that resist tidy disciplinary boundaries.
The difficulty gradient spans elementary through professional: some questions test facts a high schooler would know; others require the specialized knowledge of a licensed practitioner. Abstract algebra sits next to high school geography. Jurisprudence neighbors college biology.
This range is deliberate. A model that excels at college mathematics but fails professional medicine reveals something about the distribution of its training data — specifically, where knowledge was deep and where thin. MMLU’s breadth makes selective memorization visible, and that visibility is the point.
The subjects were not chosen to represent human knowledge proportionally. They were chosen to span enough ground that no single fine-tuning trick could game the entire test. A model scoring 90% across all 57 subjects has absorbed something broader than pattern matching within a single domain — or at the very least, its training corpus covered those domains with unusual thoroughness.
The Mechanics Behind a 15,908-Question Exam
The evaluation protocol is simpler than the scores suggest. That simplicity is part of why it worked — and part of why it eventually stopped working.
How does MMLU evaluate LLM knowledge using multiple-choice questions across 57 subjects
Standard MMLU evaluation uses a 5-shot format: five example question-answer pairs are prepended to each test question, drawn from the development set for that subject (DeepEval Docs). The model sees those five demonstrations, encounters the target question, and must produce one of four letters.
What the model actually does with those five examples is less straightforward than it sounds. In a Model Evaluation context, 5-shot prompting is meant to activate the model’s in-context learning — pushing its output distribution toward the format and domain of the test. The demonstrations are not training data. They are conditional context. The model’s parameters do not change; only its sampling distribution shifts.
This is where the measurement becomes fragile. The same model, asked the same question with a different prompt template, can produce accuracy swings of 4–5 percentage points (MMLU-Pro paper). That variance is not noise in the model — it is a feature of how autoregressive generation interacts with prompt structure. The test measures the prompt-model system, not the model.
Accuracy is reported per subject and aggregated as a macro-average: each of the 57 subjects contributes equally regardless of question count. A subject with 100 questions carries the same weight as one with 1,000 — a design choice that amplifies performance differences in smaller, more specialized domains.
The output is a single number. But like any Confusion Matrix, the aggregate hides the distribution. A model at 87% overall might score 95% on high school history and 60% on abstract algebra. The aggregate is useful for headlines. The per-subject breakdown is useful for engineering decisions.
When the Measuring Stick Stops Measuring
The uncomfortable fact about MMLU is that it succeeded too well.
As of early 2026, frontier models cluster within a narrow band: GPT-5.3 Codex reaches approximately 93% on MMLU, while Gemini 3 Pro and Claude Opus 4.5 both score around 90%. These figures carry temporal uncertainty — exact scores vary by 2–4 percentage points depending on the evaluation harness and prompt format used. But the pattern is unambiguous: the best models have passed the estimated human expert baseline, and the remaining headroom is smaller than the benchmark’s own error rate.
That error rate — 6.49% of questions containing mistakes, with Virology as the worst offender at 57% error (Wikipedia) — means the theoretical ceiling is not 100%. A perfect model would get some questions “wrong” because the keyed answer is incorrect. This creates a quiet paradox in Benchmark Contamination analysis: a model that memorized the answer key would score lower on corrupted subjects than one that genuinely understood the material.
Not a flaw. A diagnostic signal the creators never intended.
MMLU-Pro, presented as a NeurIPS 2024 Spotlight paper, attempts to extend the runway (MMLU-Pro paper). It expands answer choices from 4 to 10, reducing the advantage of elimination strategies. Its 12,000+ questions target graduate-level reasoning across 14 subjects. Models that score well on standard MMLU drop 16–33% on MMLU-Pro — a gap that suggests much of what the original benchmark measured was recognition, not reasoning.
Prompt sensitivity drops too: from 4–5% variance on MMLU to roughly 2% on MMLU-Pro. More answer options mean fewer lucky guesses, and fewer lucky guesses mean the scores reflect something closer to actual capability. Whether that capability constitutes “knowledge” or a more sophisticated form of pattern retrieval — that question stays open.
Rule of thumb: If two models differ by less than 3 points on MMLU, the difference is likely within measurement noise. Use per-subject breakdowns and harder benchmarks like MMLU-Pro for meaningful comparison.
When it breaks: MMLU fails to differentiate models that have saturated above 88%. It also breaks silently when training data includes MMLU questions — a Precision, Recall, and F1 Score analysis on contaminated versus clean subsets would expose the gap, but few published evaluations include that analysis. If you are comparing models for domain-specific work, MMLU’s aggregate tells you almost nothing; the per-subject score on the relevant domain is the minimum useful signal.
The Data Says
MMLU gave the field something it badly needed in 2021: a single number that correlated with breadth of knowledge. That number now reveals more about the benchmark’s limits than about the models it measures. The question worth asking was never “which model scores highest” — it was what the score distribution across 57 subjects exposes about how knowledge gets encoded in weights. That question still has no clean answer, and the successor benchmarks are only beginning to sharpen it.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors