Long-Context vs RAG: How Each Handles Knowledge in 2026
Table of Contents
ELI5
Long-context stuffs all your documents into the model’s working memory in one shot. RAG keeps the documents outside, fetches the relevant pieces, and hands only those to the model. Same goal — different physics.
A 1M-token context window sounds like the end of every retrieval pipeline. Why bother with chunking, embeddings, and rerankers when you can just paste the whole knowledge base into the prompt and let the model sort it out? The answer is not what most teams expect — and the reason hides inside the attention mechanism itself, where tokens compete for influence and the middle of a long context is the worst place to put anything important.
The Two Roads to Knowledge
Both architectures answer the same question: how does an LLM see information that was never in its training data? The difference is whether that information lives inside the prompt or outside the model entirely. That distinction sounds cosmetic. It is not — it determines cost curves, failure modes, and what kind of mistake your system makes when it fails.
What is the difference between long-context and RAG?
Long-context relies on the model’s native attention window. You concatenate documents, prepend a question, and submit one large request. The model treats every token as equally available — at least in theory — and computes attention across the full span.
Retrieval-Augmented Generation, the architecture introduced in Lewis et al. (2020), splits the system in two. A retriever (typically a query encoder paired with a dense document index) selects a small set of passages from an external store. A generator — the LLM itself — receives only those passages and produces an answer. Knowledge sits outside the model; relevance scoring sits in front of the model.
The contrast is structural, not stylistic.
| Dimension | Long-Context | RAG |
|---|---|---|
| Where knowledge lives | Inside the prompt | External index ( Sparse Retrieval or dense) |
| Per-query cost | Scales with input size | Scales with retrieved chunks |
| Update model | Re-paste everything | Re-index affected documents |
| Failure mode | Attention dilution | Missed retrieval, distractor poisoning |
| Best ground for RAG Evaluation | Whole-doc reasoning | Targeted question answering |
What does long-context vs RAG mean for LLM applications in 2026?
The market has settled on a hybrid stance, not a winner. As of May 2026, frontier models from Google, Anthropic, and OpenAI all advertise context windows in the 1M-token range — Anthropic’s surcharge for long-context requests was eliminated on 2026-03-13 (Anthropic pricing analysis), making large-window calls dramatically more competitive on cost. That pricing shift is what made the trade-off interesting again.
But “interesting” does not mean “settled.” The 2025 evaluation by Li et al. found that long context generally outperforms RAG on Wikipedia-style QA when the model is large enough — yet the same year’s LaRA benchmark concluded that the optimal choice depends on model size, long-text capability, context length, task type, and the characteristics of the retrieved chunks. Their summary, in three words: no silver bullet (LaRA, Wang et al.).
The decision is no longer “which architecture wins” — it is “which architecture matches the geometry of the question you are asking.”
The Mechanics of Memory and Retrieval
The two architectures look similar from the outside. Both end with an LLM producing tokens conditioned on a prompt. The divergence is everything that happens before the first token is generated — and the shape of the probability landscape the model is sampling from.
How do long-context windows and RAG pipelines retrieve and use information?
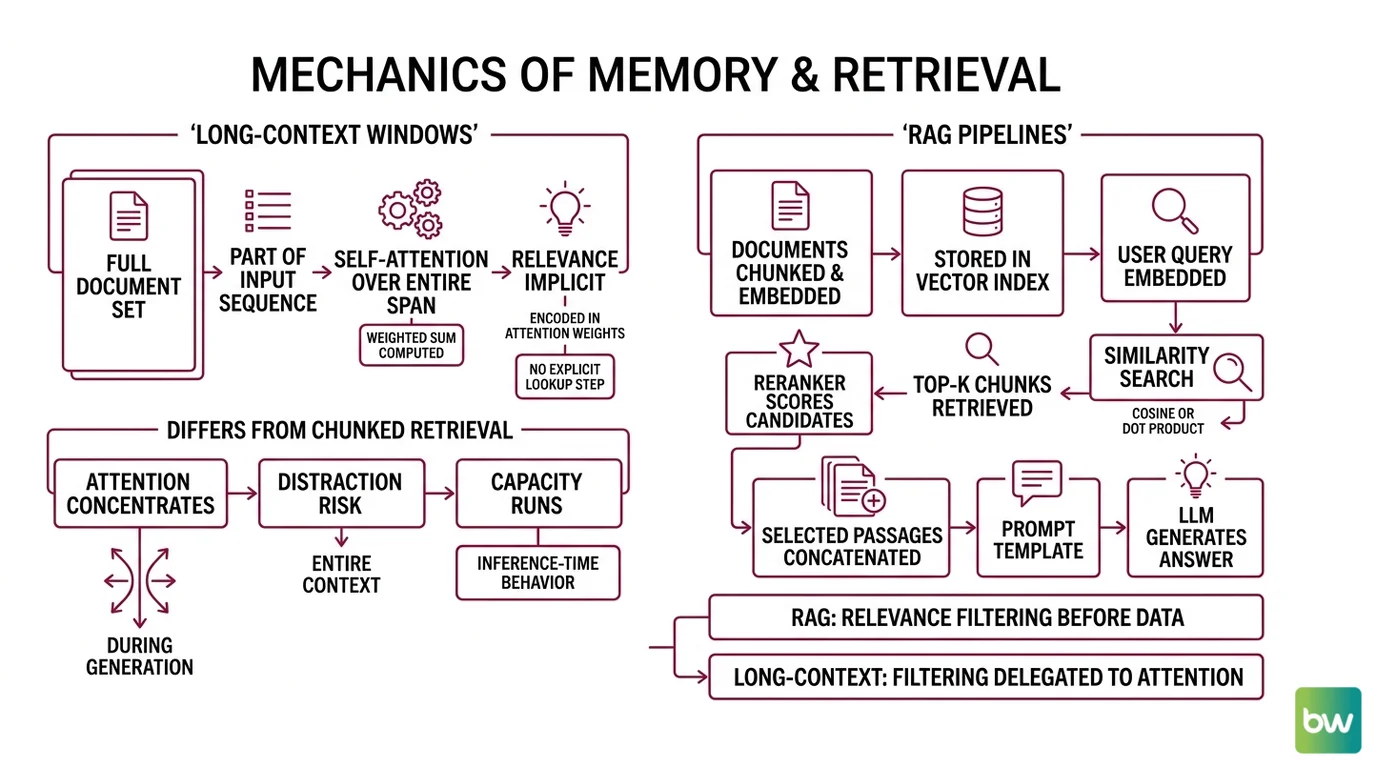
A long-context request is mechanically simple. The full document set becomes part of the input sequence. Self-attention runs over the entire span, with each token’s representation computed as a weighted sum of every other token’s representation. There is no explicit “lookup” step — relevance is implicit, encoded in the attention weights the model learns to assign during inference.
RAG is mechanically more interesting because retrieval is an external, inspectable step. A typical pipeline looks like this:
- Documents are chunked, embedded, and stored — usually in a dense vector index, sometimes augmented by sparse keyword retrieval for terms that don’t embed well
- A user query is embedded into the same vector space
- Top-k chunks are retrieved by similarity (cosine, dot product, or a learned scoring function)
- A reranker — often a smaller cross-encoder — re-scores the candidates against the query
- The selected passages are concatenated into a prompt template along with the question
- The LLM generates an answer conditioned on those passages plus the RAG Guardrails And Grounding instructions in the system prompt
The key asymmetry: RAG does relevance filtering before the model sees the data. Long-context delegates the filtering to attention itself. One is explicit and auditable; the other is implicit and statistical.
How does stuffing 1M tokens into context differ mechanically from chunked retrieval?
Mechanically, the difference shows up in three places: where attention concentrates, what the model can be distracted by, and what happens when capacity runs out.
Attention is not uniform across position. The 2024 finding from Liu et al. — known as “lost in the middle” — showed that LLMs perform best when relevant information sits at the very start or very end of the input, with a U-shaped degradation curve through the middle. The 2026 LDAR study confirmed that the effect persists even in current frontier long-context models. The model “sees” everything in the window, but it does not see everything equally.
That has a practical consequence. A 1M-token context with the answer hiding around position 500K may underperform a 4K-token RAG context where the answer sits at the top. Token count is not the same thing as accessible attention.
The second mechanism is distractor sensitivity. Yu et al. (2024) showed that adding more retrieved chunks initially raises answer quality — and then degrades it as irrelevant passages enter the context. The same pattern shows up in raw long-context: pasting an entire knowledge base in the hope that the model will sort it out tends to produce inverted-U accuracy curves, where more input is briefly better and then strictly worse. Databricks Mosaic Research saw this across most of the models they evaluated.
The third mechanism is capacity. Long context is token-inefficient. LDAR (2026) frames this directly — under limited model capacity, long-context strategies amplify both the lost-in-the-middle effect and the distractor effect simultaneously. The model is doing more work to ignore more noise.
What the Geometry Predicts
The mechanics give us a small set of reliable predictions — the kind of if/then statements that turn passive understanding into something you can plan around.
- If your relevant information is concentrated and your query is targeted, RAG will usually beat raw long-context at lower cost.
- If your task requires reasoning across an entire document — summarizing a contract, comparing arguments across chapters — long-context will usually outperform chunked retrieval, because chunking severs cross-references the model would otherwise see.
- If your retrieved chunks are noisy or your reranker is weak, adding more chunks will hurt before it helps. Tune the top-k downward, not upward.
- If the answer can land anywhere in a 500K-token document and you cannot pre-narrow the search, long-context with a high-capacity model is the safer bet — but expect a confidence dip on questions whose answers sit in the middle.
- If your knowledge changes frequently, RAG wins on update economics. Re-indexing a few documents is cheaper than re-running every query against an ever-growing prompt.
Rule of thumb: Use long-context when the question requires the whole document. Use RAG when the question requires a part of the corpus. Use both when you don’t yet know which you have.
When it breaks: Long-context degrades on inputs that exceed the model’s effective attention budget — not its advertised window size, but the position range where attention stays sharp. The published context length is a marketing number; the usable context length is an empirical question for each model and each task.
The Hybrid Architecture Nobody Voted For
The most interesting consequence of the LC-vs-RAG debate is that production systems increasingly do not pick a side. Xu et al. (2024) found that long-context wins on long-context understanding when the model is large enough, but RAG remains viable for inputs that exceed the window and for cost-sensitive deployments. The pragmatic answer is to use retrieval to narrow the candidate set and long-context to handle whatever the retriever returns.
This is not a compromise — it is a different architecture. The retriever’s job stops being “give the model the answer” and becomes “give the model a document collection small enough to reason over coherently.” The reranker becomes optional. The prompt template gets simpler. And the RAG Evaluation target shifts from “did the retriever surface the right chunk” to “did the retriever surface the right neighborhood.”
Whether you call this RAG with bigger chunks or long-context with a pre-filter is a vocabulary question. The mechanism is the same: bound the working set, then let attention do the rest.
The Data Says
Long-context and RAG are not competing technologies — they are different bets about where to spend your capacity budget. Long-context spends it on attention; RAG spends it on retrieval and ranking. As of May 2026, the research consensus from LaRA and LDAR is that neither bet wins universally — the right choice depends on model size, task type, the distribution of relevant information, and the noise profile of your retrieved chunks.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors