What Is the Attention Mechanism: Scaled Dot-Product, Self-Attention, and Cross-Attention Explained
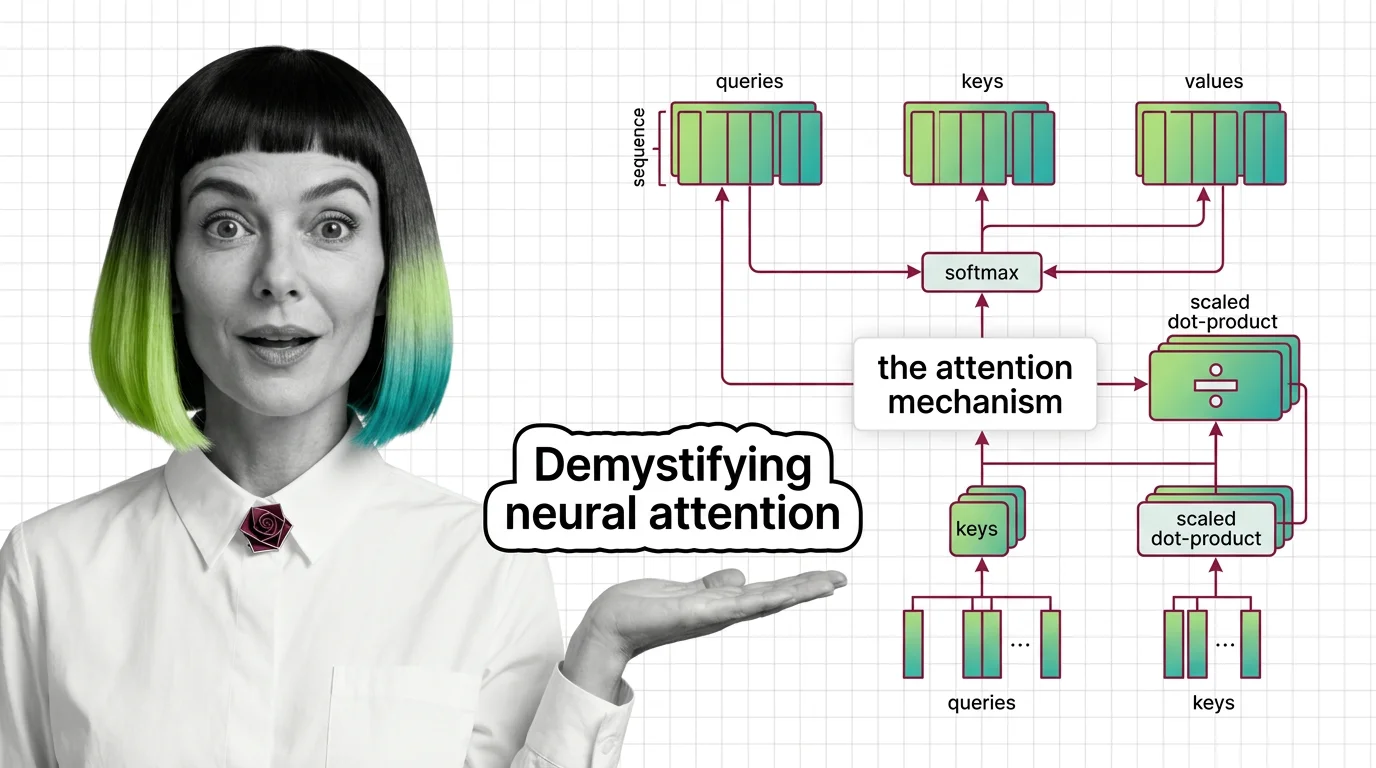
Table of Contents
ELI5
The attention mechanism lets a neural network decide which parts of the input matter most for each output, weighting relevant tokens instead of treating all equally.
The Misconception
Myth: Attention means the model “focuses” on important words the way a human reader does. Reality: Attention computes a weighted average over all positions using learned linear projections – there is no spotlight, only matrix arithmetic distributing probability mass. Symptom in the wild: Engineers assume attention maps are interpretable like eye-tracking heatmaps and build debugging tools on that assumption. The maps rarely correlate with human intuition about salience.
How It Actually Works
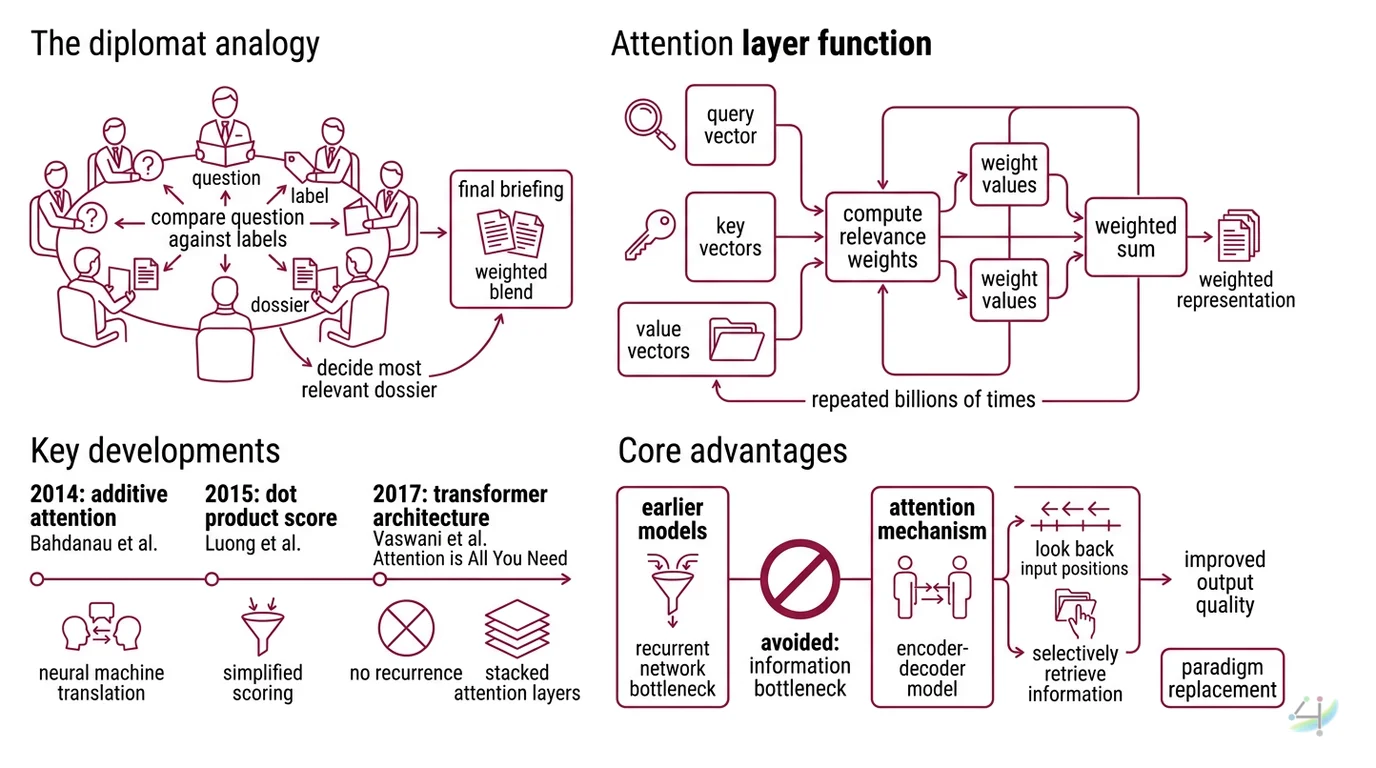
Picture a room full of diplomats at a round table. Every diplomat holds three documents: a question they need answered, a label describing what they know, and the actual dossier of information. Each diplomat compares their question against every other diplomat’s label, decides whose dossier is most relevant, and constructs their final briefing as a weighted blend of those dossiers.
That room is a single attention layer. The questions are queries, the labels are keys, and the dossiers are values. The mechanism is nothing more than a structured comparison followed by a weighted sum – repeated billions of times per inference pass.
What is the attention mechanism in deep learning?
The attention mechanism is a function that computes relevance-weighted representations of input elements. Rather than compressing an entire sequence into a single fixed-length vector – the bottleneck that plagued earlier sequence-to-sequence models – attention allows the model to look back at every position in the input when producing each element of the output.
The idea surfaced in 2014 when Bahdanau, Cho, and Bengio introduced additive attention for neural machine translation (Bahdanau et al.). Their encoder-decoder model learned alignment scores between source and target positions, and translation quality jumped because the decoder could selectively retrieve information from the encoder’s hidden states instead of squeezing everything through a single context vector.
Luong et al. simplified the scoring to a dot product in 2015. Then in 2017, Vaswani et al. removed recurrence entirely with “Attention Is All You Need,” building the Transformer Architecture on nothing but attention layers stacked in parallel.
Not an incremental improvement. A paradigm replacement.
The core insight was that attention could serve as the primary computation mechanism, not just an auxiliary alignment trick grafted onto recurrent networks. Self-attention over the full sequence, computed in parallel, replaced the sequential processing that had defined neural language modeling for years.
How does scaled dot-product attention work step by step?
The formula is deceptively compact:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) V
Here is what happens, step by step.
First, three linear projections transform the input into Query Key Value matrices: Q (queries), K (keys), and V (values). In the original Transformer, each head used d_k = 64 dimensions across h = 8 parallel heads, with d_model = 512 total (Vaswani et al.).
Second, the dot product QK^T computes raw similarity scores between every query and every key. This produces a square matrix of dimension (sequence_length x sequence_length) – one score for each pair of positions. The cost is quadratic in sequence length, and that quadratic scaling is the reason long-context inference remains expensive.
Third, the scores are divided by sqrt(d_k). This scaling factor prevents a subtle numerical trap: when d_k is large, dot products grow in magnitude, pushing softmax inputs into regions where gradients nearly vanish (Vaswani et al.). Without scaling, training stalls because the gradient signal disappears into the saturated tails of the softmax distribution.
Not a cosmetic adjustment. A numerical rescue operation.
Fourth, softmax normalizes the scaled scores into a probability distribution across positions. Each query now has a set of weights summing to one, expressing how much each key-position contributed to the answer.
Fifth, those weights multiply the value matrix V, producing the final weighted representation. The output at each position is a blend of all values, proportioned by relevance.
The original Transformer achieved BLEU scores of 28.4 on English-to-German and 41.8 on English-to-French benchmarks on WMT 2014 (Vaswani et al.) – state of the art at the time, using attention as the sole sequence-processing mechanism.
What is the difference between self-attention and cross-attention?
The distinction is geometric, not philosophical.
In self-attention, Q, K, and V are all derived from the same input sequence (IBM). Every token attends to every other token within the same sequence. This is how a language model builds contextual representations: the word “bank” in “river bank” attends to “river” and shifts its representation away from the financial meaning. Self-attention is the mechanism that gives transformers their ability to model long-range dependencies within a single sequence.
In cross-attention, the queries come from one sequence while the keys and values come from a different sequence (IBM). A machine translation decoder, for instance, generates queries from the partially translated target sentence and retrieves keys and values from the encoder’s representation of the source sentence. The decoder is literally asking: “Given what I have translated so far, which parts of the source are relevant for the next word?”
Cross-attention is also the bridge in text-to-image models. The text encoder produces keys and values; the image generation process produces queries. The visual representation learns to attend to the linguistic conditioning – which is why changing a single word in a prompt can radically alter the generated image.
The same mathematical operation. Different wiring. Self-attention looks inward; cross-attention looks across.
What This Mechanism Predicts
- If you increase sequence length while keeping d_k fixed, attention computation grows quadratically – doubling the context means roughly four times the cost.
- If you skip the scaling factor in dot-product attention, training will appear to work initially but gradients will vanish as d_k grows, and the model will plateau.
- If you replace self-attention with Linear Attention approximations, you gain sub-quadratic scaling but sacrifice exact pairwise comparison – the tradeoff is speed versus representational fidelity.
What the Math Tells Us
Attention is the reason transformers generalize across modalities. The same Q-K-V computation that parses language also aligns audio spectrograms with text transcripts and conditions image generation on natural language prompts. The mechanism is agnostic to what it compares – it only requires that inputs are projected into a shared vector space where dot products measure relevance.
Rule of thumb: If your task requires the model to relate any element to any other element in the input, attention is the right primitive. If your task is strictly local – a sliding-window filter over adjacent positions – you are paying the quadratic cost for nothing.
When it breaks: Standard dot-product attention scales as O(n^2) in both time and memory with respect to sequence length. For contexts beyond tens of thousands of tokens, the cost becomes prohibitive without approximate methods such as FlashAttention or sparse attention patterns. FlashAttention-3 achieves roughly 1.5-2.0x the throughput of its predecessor on H100 GPUs (FlashAttention-3 paper), but exact performance varies with sequence length and head dimension.
Compatibility note:
- FlashAttention versions: FA-3 targets Hopper GPUs (H100); FA-4 is in beta for Hopper and Blackwell GPUs (not yet stable as of early 2025). Version availability changes frequently – verify against Dao-AILab/flash-attention before pinning a dependency.
One More Thing
There is an elegant irony embedded in the attention timeline. Bahdanau introduced attention as a fix for a specific failure – the information bottleneck in encoder-decoder translation. A decade later, attention is no longer a fix. It is the entire architecture. The patch became the foundation, and the original structure it was meant to repair no longer exists in modern systems.
PyTorch has internalized this shift. The scaled_dot_product_attention function, introduced in PyTorch 2.0, automatically selects between FlashAttention, memory-efficient, and standard math backends depending on hardware (PyTorch Docs). The mechanism is so central that the framework optimizes it at the kernel level.
The Data Says
Attention is a weighted-sum operation over learned projections – nothing more, nothing less. Its power comes not from complexity but from universality: the same Q-K-V dot-product structure enables language modeling, machine translation, image synthesis, and cross-modal retrieval. Understanding the scaling factor, the self-versus-cross distinction, and the quadratic cost is the difference between using transformers and understanding why they work.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors