What Is Temperature in LLMs and How Softmax Scaling Controls Text Generation Randomness
Table of Contents
ELI5
Temperature divides each raw score (logit) before the softmax step, making the model’s next-word choices sharper or flatter — lower means more predictable, higher means more random.
Set temperature to zero. Expect the same answer every time. Run the same prompt twice.
Get two different outputs.
This happens more often than most engineers realize — and the reason lives inside a single division operation that most API documentation buries in a footnote. The parameter everyone treats as a “creativity slider” is doing something far more specific: it is rescaling the geometry of a probability distribution, and that rescaling has consequences that a slider metaphor cannot capture.
The Division That Reshapes Everything
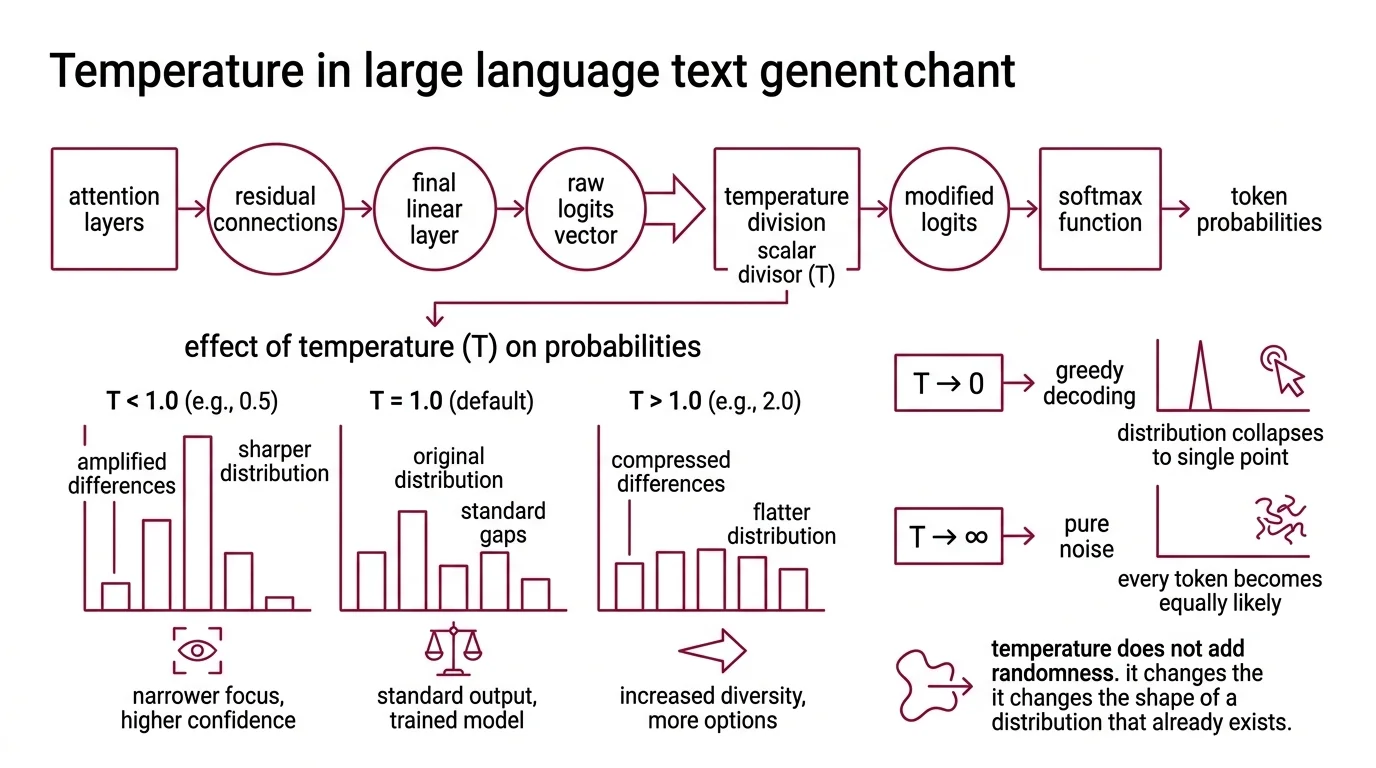
Before a language model picks its next token, it has already done the hard work. Attention layers have processed the context, residual connections have carried forward information, and the final linear layer has produced a vector of raw scores — one number per token in the vocabulary. These are Logits: unnormalized, unbounded, and useless for sampling until they pass through one more function.
That function is Softmax.
And temperature is the single number that intervenes between logits and softmax — changing what the model considers probable before it ever draws a sample.
What is temperature in large language model text generation?
Temperature is a scalar divisor applied to every logit before the softmax computation. The formula is direct (Wikipedia):
P(token_i) = e^(logit_i / T) / Sum_j e^(logit_j / T)
When T = 1.0, the softmax operates on the raw logits unchanged. This is the default behavior for most providers — the distribution the model was trained to produce.
When T drops below 1.0, each logit is divided by a number less than one, which amplifies it. The gaps between high-scoring and low-scoring tokens widen. The result: the highest-scoring token absorbs a larger share of the total probability mass, and the distribution sharpens toward a single peak.
When T rises above 1.0, the opposite occurs. Division by a number greater than one compresses the logit differences. Tokens that were improbable gain relative weight. The distribution flattens, and the model samples more evenly across the vocabulary.
At T approaching 0, the distribution collapses to a point mass on the highest-scoring token — which is equivalent to Greedy Decoding.
At T approaching infinity, every token becomes equally likely. Pure noise.
The intuition people miss: temperature does not add randomness. It changes the shape of a distribution that already exists. The logits carry all the information; temperature merely decides how much of that information the sampling step is allowed to use.
Not a source of randomness. A filter on it.
How does temperature scaling change the softmax probability distribution over tokens?
The mechanism is exponential amplification, and it matters because human intuition is linear.
Consider a vocabulary of three tokens with logits [5.0, 3.0, 1.0]. At T = 1.0, softmax produces probabilities approximately [0.87, 0.12, 0.02]. The top token is likely, but the second still has a chance.
At T = 0.5, the logits become [10.0, 6.0, 2.0] before softmax. The resulting probabilities shift to approximately [0.98, 0.02, 0.00]. The top token is now near-certain; the third token is effectively eliminated.
At T = 2.0, the logits become [2.5, 1.5, 0.5]. Probabilities shift to approximately [0.66, 0.24, 0.09]. All three tokens are in play.
The same three logits. The same model. Three entirely different behaviors — depending on a single divisor.
This is why treating temperature as a linear “more creative / less creative” dial misleads. The relationship between the parameter value and the resulting probability shift is nonlinear. Small changes near T = 0 produce dramatic effects; the same magnitude of change near T = 2.0 barely registers. The sensitivity is asymmetric, and anyone tuning temperature by intuition rather than by examining the actual distribution is optimizing blind.
Cutting the Tail: How Sampling Strategies Filter the Noise
Temperature reshapes the entire distribution — including the long tail of low-probability tokens that produce gibberish when sampled. The history of text generation is partly a history of increasingly sophisticated strategies for cutting that tail without losing the useful diversity in the middle.
How does nucleus sampling (top-p) decide which tokens to keep and which to discard?
Nucleus sampling — introduced by Holtzman et al. in their 2020 paper “The Curious Case of Neural Text Degeneration” — takes a fundamentally different approach than temperature. Instead of reshaping the distribution, it truncates it.
The algorithm sorts tokens by descending probability, then walks down the list, accumulating probability mass. The moment the cumulative sum reaches or exceeds a threshold p, it stops. Every token outside this nucleus is discarded; the remaining tokens are renormalized and sampled from.
The defining property: the nucleus size is dynamic. When the model is confident — one token dominates the distribution — the nucleus might contain only a handful of tokens. When the model is uncertain — probability spread across many candidates — the nucleus expands to dozens or hundreds.
This adaptiveness is what top-p offers over a simpler strategy like top-k, which always keeps a fixed number of candidates regardless of the distribution’s shape. Top-k with a set value keeps that many tokens whether the model is certain or confused; top-p with p = 0.95 keeps as few or as many as the distribution demands.
Google’s Gemini API defaults to a top_p of 0.95 (Google AI Docs). Anthropic recommends adjusting temperature alone and leaving top_p and top_k at defaults unless there is a specific reason to change them (Anthropic Docs). These are not arbitrary choices — they reflect the fact that temperature and top-p interact in ways that make simultaneous tuning unpredictable.
A newer strategy is gaining traction in open-source Inference stacks. Min-p sampling, proposed by Nguyen et al. and accepted as an oral presentation at ICLR 2025, sets a dynamic floor: any token whose probability falls below a fraction of the top token’s probability is discarded. Unlike top-p, which defines a ceiling on cumulative mass, min-p defines a floor relative to the leader. The threshold automatically adapts — strict when the model is confident, permissive when it is not. Min-p is already supported in Hugging Face Transformers, vLLM, and llama.cpp (Nguyen et al.), though it has not yet reached the official APIs of OpenAI or Anthropic.
What the Parameter Cannot Promise
Understanding the mechanism is useful. Knowing where it fails is more useful.
The most common misconception is that setting temperature to zero produces deterministic output. It does not — at least not reliably. Even at temperature 0.0, GPU floating-point arithmetic, Quantization effects, and Continuous Batching across requests can introduce variation. Anthropic’s documentation states this explicitly (Anthropic Docs), and OpenAI users report the same behavior. If your workflow requires bitwise-identical outputs, temperature alone will not deliver that guarantee.
Provider-specific ranges add another layer of confusion. OpenAI supports temperatures from 0 to 2 with a default of 1 (OpenAI Community). Anthropic’s Claude accepts 0.0 to 1.0, also defaulting to 1.0 (Anthropic Docs). Google’s Gemini supports 0.0 to 2.0 with a default of 1.0, but Google strongly recommends keeping Gemini 3 at the default — lower values may cause repetitive looping (Google AI Docs). A temperature of 0.7 means something different in each system, because the underlying logit scales and training distributions differ.
And then there is the question of whether temperature survives at all. OpenAI’s reasoning models — GPT-5, o3, and o4-mini — no longer accept temperature, top_p, or other sampling parameters; they use a reasoning_effort parameter instead (OpenAI Community). The model decides its own sampling behavior. This is not a minor API change — it signals that for some architectures, sampling control is moving inside the model.
When it breaks: Temperature fails silently when the logit distribution is already near-uniform (the model is genuinely uncertain) or near-degenerate (one token dominates by orders of magnitude). In the first case, no temperature setting produces coherent output because the model has nothing confident to say. In the second, temperature changes have almost no practical effect — the dominant token wins regardless.
Rule of thumb: Start at the provider’s default. Decrease in small increments for tasks requiring consistency; increase in small increments for tasks requiring diversity. Never tune temperature and top-p simultaneously unless you understand the interaction for your specific model.
The Data Says
Temperature is a divisor, not a dial. It operates on logits before softmax, reshaping a distribution that already contains the model’s judgment — and that reshaping is nonlinear, provider-specific, and increasingly optional as reasoning models remove the parameter entirely. Understanding the division is the prerequisite for using it well.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors