What Is Synthetic Data Generation and How Artificial Training Data Is Created
ELI5
Synthetic data generation builds artificial records that copy the statistical patterns of a real dataset without reusing any real entries. A model learns the shape of your data, then samples brand-new rows from it.
Take a hospital’s patient table, teach a model the statistical shape of it, then delete the original. Generate a fresh table of patients who never existed — every age, diagnosis, and lab value invented — and train a classifier on that instead. On a surprising number of tasks, it performs almost as if it had seen the real records.
The strange part is what survived the deletion. Not a single synthetic row maps to a real person, yet the correlations between columns are still there.
Most people hear “synthetic data” and picture anonymization: real records with the names blacked out. That mental model is wrong, and the error is expensive.
Not anonymized records. Samples from a learned distribution.
Faking a Name Is Not Faking a Dataset
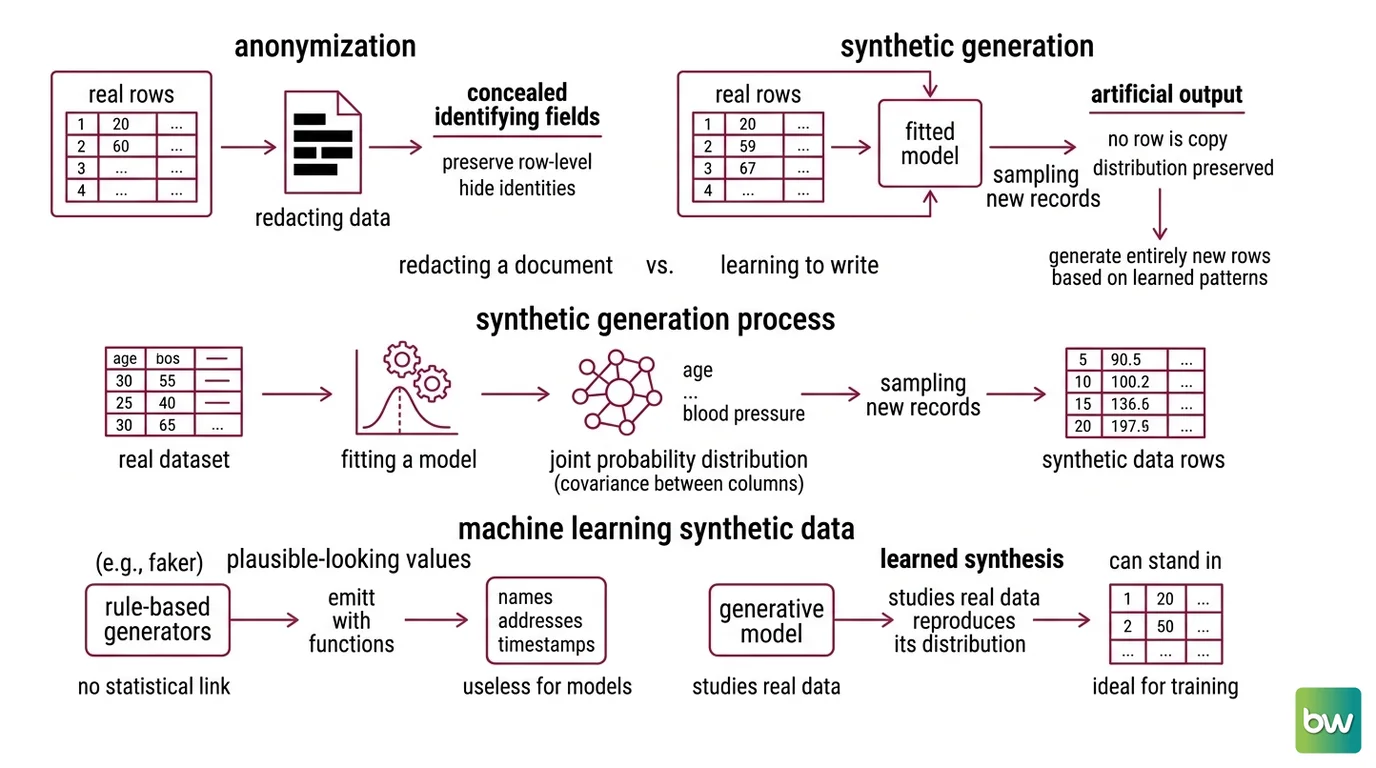
Anonymization starts with real rows and hides identifying fields. Synthetic generation never keeps the rows at all — it keeps a model of how the rows are distributed and draws new ones from it. The distinction is the difference between redacting a document and learning to write in its author’s hand. One conceals; the other generates.
What is synthetic data generation?
Synthetic data generation is the process of fitting a model to a real dataset’s joint probability distribution, then sampling new records from that fitted model. The output is artificial — no row is a copy of a real entry — but the relationships between columns are preserved. The asset is the distribution, not the rows.
Two fields like age and blood pressure are not independent; they co-vary. A useful generator captures that joint structure — the full cloud of how every column moves with every other — not just each column measured on its own. Get the joint distribution right and a model trained on the fiction behaves almost like one trained on the truth.
What is synthetic data in machine learning?
In machine learning, synthetic data is training data produced by an algorithm instead of collected from the world. It splits into two families that are routinely confused.
Rule-based generators, like Faker, emit plausible-looking values — names, addresses, timestamps — from provider functions with no statistical link to any real dataset (Faker Docs). They are ideal for filling a test database and useless for teaching a model the correlations that matter. Learned synthesis is the other family: a generative model studies a real dataset and reproduces its distribution, which is the only path to data that can stand in for the original during training. Keep that line sharp, because the two families fail in completely different ways, and so does the Training Data Quality you end up with.
How a Model Learns to Forge Its Own Training Set
Picture the dataset as a cloud of points in a high-dimensional space, one axis per column. Dense regions are common combinations; sparse regions are rare ones; empty regions are combinations that never occur. A generative model’s entire job is to learn the shape of that cloud — its ridges, its density, its holes — well enough to drop new points where real ones would plausibly land.
How does synthetic data generation work?
Three families of generative model dominate learned synthesis, and each maps the cloud differently (Synthetic Data Survey).
A Generative Adversarial Network pits two networks against each other: a generator inventing rows and a discriminator trying to catch the fakes. They train until the generator’s output is good enough to fool the critic. A Variational Autoencoder compresses each record into a compact latent space and learns to decode points back into records; sample a random point, decode it, and you have a new entry. Diffusion Models take a different route — they start from pure noise and remove it step by step, like static resolving into a photograph — and on image fidelity, diffusion now leads the field.
For tabular data — the messy mix of continuous and categorical columns most organizations actually hold — the reference technique is CTGAN, introduced by Xu et al. (NeurIPS 2019). It pairs a conditional GAN with mode-specific normalization to handle columns whose values cluster into several peaks rather than one tidy bell curve. CTGAN is bundled into the Synthetic Data Vault, maintained by DataCebo, which reached version 1.37.1 in June 2026 and is distributed under the Business Source License — source-available, not a classic open-source license (SDV on PyPI).
| Tool | Approach | What it actually captures |
|---|---|---|
| Faker | Rule / provider functions | Format only — no statistical fidelity |
| CTGAN | Conditional GAN + mode-specific normalization | Joint distribution of mixed tabular columns |
| SDV | Copulas, GANs, and VAEs for tabular and relational data | Single-table, multi-table, and sequential structure |
The Privacy Budget That Decides How Much the Model Remembers
A generator that learns its distribution too well becomes a liability. If it memorizes a real outlier and reproduces it verbatim, the synthetic dataset has quietly leaked a real person — the exact harm it was supposed to prevent. The formal defense is Differential Privacy, the (ε, δ) framework introduced by Cynthia Dwork (Harvard Privacy Tools).
The dial that matters is ε, the privacy budget. Smaller ε means stronger privacy — the generator is allowed to remember less about any single record, so no individual’s data measurably changes the output. Turn ε up and the synthetic data sharpens, but the guarantee weakens. Privacy and fidelity sit on opposite ends of the same lever.
This tension is exactly where the current tooling clusters. MOSTLY AI released an open-source Synthetic Data SDK for differentially private tabular synthesis in January 2025 (MOSTLY AI Blog); as of June 2026 its brand and assets belong to Syntho, now styled “MOSTLY AI, powered by Syntho,” though the open-source SDK remains usable (Syntho). Gretel, another differential-privacy-focused platform, is no longer an independent startup — NVIDIA acquired it in March 2025 in a deal reported at around $320 million (SiliconANGLE), folding synthetic-data tooling into its model-training stack.
Where Synthetic Data Earns Its Keep — and Where It Breaks
A generator can only hand back what it managed to learn. That single fact predicts most of its behavior, and it turns passive understanding into something you can act on.
- If your real dataset holds a rare but critical pattern — fraud, a rare diagnosis, an edge-case failure — expect the generator to under-represent it. Models compress the distribution and smooth over the thin tails where rare events live.
- If two columns are correlated in a subtle way the model missed, the synthetic data will look fine column-by-column and still break the relationship that mattered.
- If you validate only marginal distributions and they match, you can still have lost the joint structure entirely.
The technique also overlaps with Knowledge Distillation, where a larger model generates training signal for a smaller one — synthetic data wearing a different label.
Rule of thumb: Judge synthetic data by how well a model trained on it performs on real held-out data, not by how realistic the individual rows look.
When it breaks: Because generators compress the training distribution, they systematically under-sample rare events and can leak privacy through Overfitting — a synthetic row that memorizes a real outlier defeats the entire purpose of generating it.
The Data Says
Synthetic data is neither a privacy trick nor a cheap photocopy; it is a sample from a model of your data, and it inherits every strength and blind spot of that model. Capture the joint distribution well and it can stand in for real records on most downstream tasks. Capture it poorly and you have generated confident noise that happens to fit your schema.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors