What Is Sparse Retrieval and How BM25 and SPLADE Represent Documents as Weighted Term Vectors
Table of Contents
ELI5
Sparse retrieval stores each document as a long vector with one slot per vocabulary word. Most slots are zero. BM25 fills them with statistical term weights; SPLADE fills them with neural ones. An inverted index does the math fast.
A common assumption is that “sparse” means “old” — the keyword era before embeddings existed, kept around because nobody finished migrating. It is a tidy story. It also misses a sparse model trained by a transformer (SPLADE, SIGIR 2021), a 2026 ecosystem where Qdrant and Elasticsearch ship sparse encoders alongside their dense ones, and the inconvenient detail that BM25 still wins on a meaningful slice of the BEIR benchmark. The shape of the vector did not become obsolete. The way we fill in the numbers did.
The Vector Most Of Whose Coordinates Are Zero
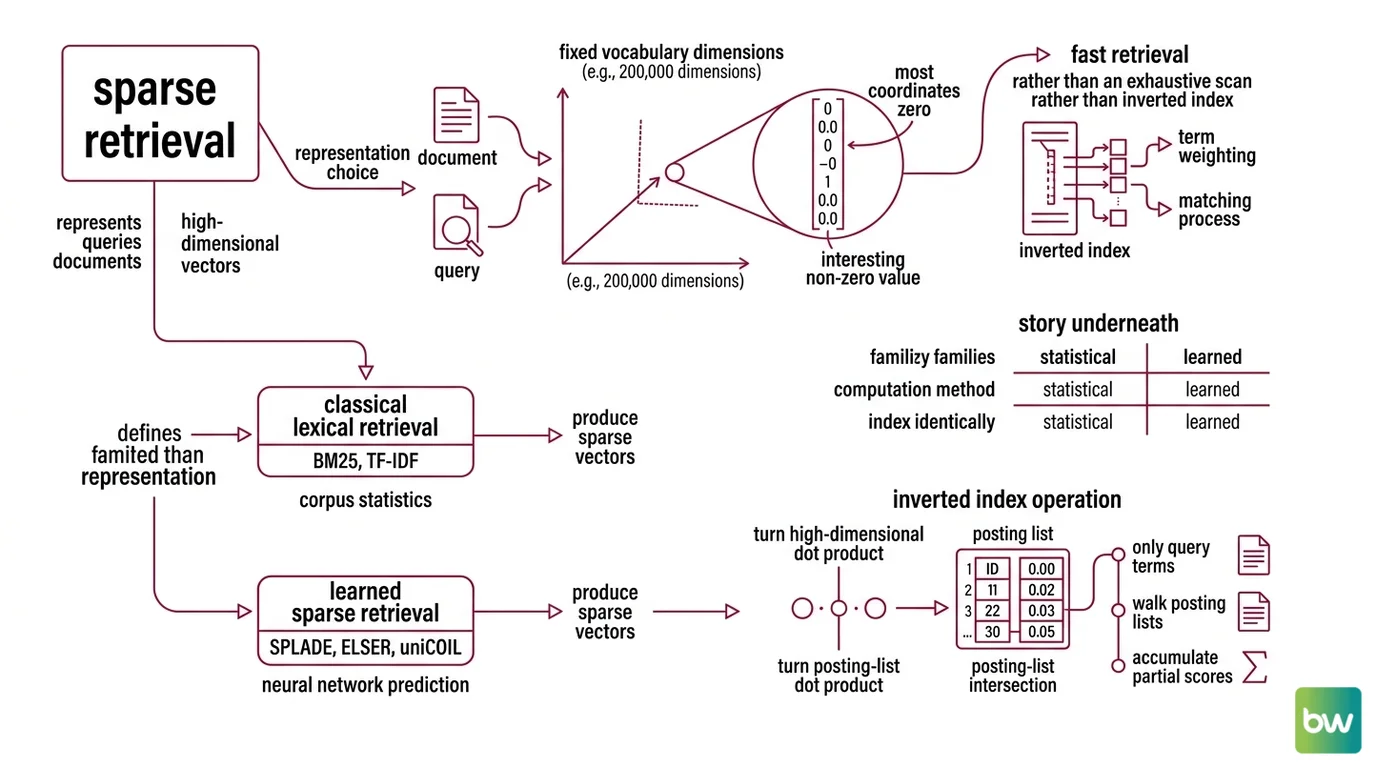
Sparse retrieval is a representation choice before it is an algorithm. Every document and query is mapped into the same enormous space — one dimension per vocabulary word — and almost every dimension is zero. The interesting question is what value goes in the dimensions that are not.
What is sparse retrieval in information retrieval?
Sparse retrieval is the class of information retrieval methods that represents queries and documents as high-dimensional vectors over a fixed vocabulary, where most coordinates are zero, and where matching happens over an Inverted Index rather than an exhaustive nearest-neighbor scan (Stanford IR Book). A vocabulary of two hundred thousand English terms produces a two-hundred-thousand-dimensional vector for every document. A typical news paragraph touches a few dozen of those dimensions. The rest are zero by construction, and that emptiness is the property the inverted index exploits to make retrieval fast.
Two families share this representation. Classical lexical retrieval — BM25, TF-IDF, query likelihood — computes each coordinate from corpus statistics. Learned sparse retrieval — SPLADE, ELSER, uniCOIL — computes it from a neural network trained to predict relevance. Both produce sparse vectors. Both index identically. The story underneath each coordinate is what differs, and most “sparse versus dense” comparisons silently mean “BM25 versus dense embeddings,” skipping the learned sparse middle where the recent progress actually sits.
How does sparse retrieval work with inverted indexes and term weighting?
Sparse retrieval works because the inverted index turns a high-dimensional dot product into a posting-list intersection. An inverted index maps each term to a list of (document id, term-frequency, position) tuples — every document containing the term, in one place. To score a query, the engine walks only the posting lists for the query terms, accumulates per-document weights, and ranks. Work scales with the number of query terms and their posting-list lengths, not corpus size. The weights in those lists are where the algorithms differ.
BM25, formalized by Robertson and Zaragoza (2009), assigns each query term a score combining three quantities: inverse document frequency, document Term Frequency, and document length. The score for a document D against a query Q is a sum over query terms:
score(D, Q) = Σ IDF(q_i) · [tf · (k1 + 1)] / [tf + k1 · (1 − b + b · |D| / avgdl)]
Two parameters shape the score. k1 saturates the contribution of repeated terms — a document mentioning “kidney” twenty times does not score twenty times higher than one mentioning it once. b normalizes by document length, dampening the bias toward longer documents. The defaults shipped by Lucene, Elasticsearch, and OpenSearch — k1 between 1.2 and 2.0, b near 0.75 — are empirical sweet spots for diverse English corpora, not theoretical optima (Stanford IR Book). Domains with unusually short, long, or repetitive documents are the first place those defaults misfire.
Notice what BM25 does not do. It does not represent meaning. It does not know “renal” and “kidney” share a referent. It scores a document highly if and only if the query’s exact tokens appear, weighted by how rare those tokens are. That property is a strength on identifier-heavy queries — model numbers, error codes, drug names — and a weakness on paraphrastic queries where the right document uses different words for the same idea.
What are the main components of a sparse retrieval system?
A production sparse retrieval system has four moving parts.
A tokenizer and analyzer decides what counts as a term. For BM25 that means lowercasing, stemming, stop-word removal, and language-specific normalization. For SPLADE the tokenizer is BERT’s WordPiece against a 30,522-token vocabulary (naver/splade-v3 model card). The tokenizer choice is implicitly a choice about which exact-match queries will work.
An encoder turns a document or query into the sparse vector. For BM25 the encoder is the IDF tables and length statistics implicit in the corpus — no model to train. For learned sparse retrievers the encoder is a transformer emitting a weight per vocabulary token; SPLADE max-pools masked-language-model logits and applies ReLU, expanding the non-zero set to semantically related tokens that never appeared in the original text.
An inverted index stores those vectors term-by-term. Lucene-based engines (Elasticsearch, OpenSearch) handle BM25 natively and store learned sparse vectors as “rank features” or impact-scored postings. Vector-native engines moved in the same direction from the other side: Qdrant added native BM25 in v1.15.2 and now indexes BM25, SPLADE++, and miniCOIL in one Query API.
A retriever and scorer walks the posting lists for query terms and returns the top-k. This is the layer benchmarked on standard datasets — most often MS MARCO, an 8.8-million-passage Bing-log corpus whose primary metric is MRR@10 (MS MARCO official), and BEIR Benchmark, the heterogeneous zero-shot evaluation introduced by Thakur and colleagues at NeurIPS 2021. Experiments typically run through Pyserini (Lin et al., SIGIR 2021), which wraps Lucene through Anserini and ships BM25, SPLADE, and uniCOIL baselines — current releases require Python 3.12 and Java 21 (Pyserini PyPI).
Where SPLADE Departs From BM25 — And Where It Does Not
The architectural surprise of learned sparse retrieval is that it slots into the same index BM25 uses. The semantic move happens before indexing, inside the encoder, not at retrieval time.
SPLADE, introduced by Formal, Piwowarski, and Clinchant in 2021 (arXiv 2107.05720), trains a transformer to produce a sparse weight distribution over BERT’s vocabulary. A document about “renal failure” emerges with non-zero weights on renal, failure, kidney, nephropathy, dialysis — terms the document never contained but that the model learned are predictive of relevance. The expansion happens at indexing time and produces a vector the inverted index can store like any other. SPLADE v2 (arXiv 2109.10086) and SPLADE-v3 (arXiv 2403.06789) refined the training recipe — distillation, hard-negative sampling, regularization tuning — without changing the underlying representation.
The honest BEIR comparison: BM25 is a strong zero-shot baseline; SPLADE outperforms it on most BEIR datasets, but not all — on certain subsets BM25 wins, particularly when queries are short and dominated by named entities (BEIR paper). The result depends on the corpus, the query distribution, and whether SPLADE has been distilled from a relevant teacher.
Two operational details often go unstated. The naver/splade reference repo is licensed CC-BY-NC-SA 4.0 — explicitly non-commercial — and its last release was October 2023 (naver/splade GitHub). Production deployments typically use engine-native encoders like Elastic’s ELSER or Qdrant’s miniCOIL, or independently-licensed SPLADE derivatives. ELSER itself is English-only and shipped with no fine-tuning required, but Elastic does not recommend it for non-English corpora (Elastic Docs).
The shared index is the architectural insight. Sparse-neural and sparse-lexical retrievers index identically and retrieve identically. They differ only in how the weights got there.
What The Sparse Geometry Predicts
Treat each retriever as a hypothesis about your queries. The predictions below are testable on your own evaluation set.
- If your queries contain rare exact tokens — drug names, SKUs, proper nouns absent from common pre-training — expect BM25 to outperform a generic SPLADE checkpoint. The IDF term does precisely what you want it to do.
- If your queries are short and intent-shaped, expect a SPLADE-family encoder to pull ahead, because term expansion compensates for query vocabulary BM25 cannot recover.
- If BM25 looks “broken” on a new corpus, the first thing to check is the analyzer chain — stemming, stop words, language detection — not the algorithm. BM25 quality is downstream of tokenization choices the defaults rarely get right on technical or multilingual content.
- If you run RAG Evaluation on a hybrid pipeline and the sparse retriever’s marginal contribution drops to near zero, the dense model has likely overfit to the corpus, not “won.” Inspect the queries the sparse retriever was catching before retiring it.
Rule of thumb: Start with BM25 on a properly configured analyzer. Add a learned sparse encoder only after evaluation shows BM25 leaves recall on the table for paraphrastic queries.
When it breaks: Sparse retrieval breaks when queries and documents share no surface overlap and no learned expansion bridges them. A colloquial query against a corpus written in formal jargon will under-perform on BM25 and on SPLADE checkpoints not trained on the target distribution. The fix is upstream — query rewriting, domain-adapted training, or pairing with a dense retriever — not a different sparse model.
Security & compatibility notes:
- SPLADE license (BREAKING): The naver/splade weights are CC-BY-NC-SA 4.0 — non-commercial only (naver/splade GitHub). For production, use engine-provided sparse encoders (ELSER, Qdrant miniCOIL) or independently-licensed SPLADE derivatives.
- SPLADE maintenance (WARNING): The naver/splade repo’s last release was October 2023. Treat the official repo as research code, not as an actively maintained production library.
- ELSER v1 (WARNING): Remains in technical preview; users should migrate to ELSER v2, which has been GA since Elasticsearch 8.11 (Elastic Docs).
- Pyserini Java requirement (INFO): Current Pyserini requires Java 21, not Java 11 or 17 (Pyserini PyPI). Older JDK environments need an upgrade before installation.
The Quiet Convergence Underneath The Sparse Label
Dense and sparse are not categories — they are points on a continuous design axis. SPLADE produces a sparse vector with neural weights. Dense retrievers produce a dense vector with neural weights. Both are learned representations; dimensionality and sparsity pattern are implementation choices that affect which index can store the result, not statements about which approach “understands” language. A 2026 RAG pipeline running BM25, SPLADE, and a dense model is not three paradigms — it is three encoders producing vectors of different shapes, and the engine indexing them is increasingly indifferent to which is which.
The Data Says
Sparse retrieval is not the keyword era’s residue. It is a representation choice — long vectors over a vocabulary, mostly zero, indexed for speed — that now hosts both classical statistical weighting and trained neural encoders. BM25 remains a strong zero-shot baseline whose defaults are corpus-dependent, not theoretical optima. Learned sparse models like SPLADE and ELSER outperform BM25 on most, but not all, BEIR tasks. Treat “sparse” as a shape, not a vintage.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors