What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
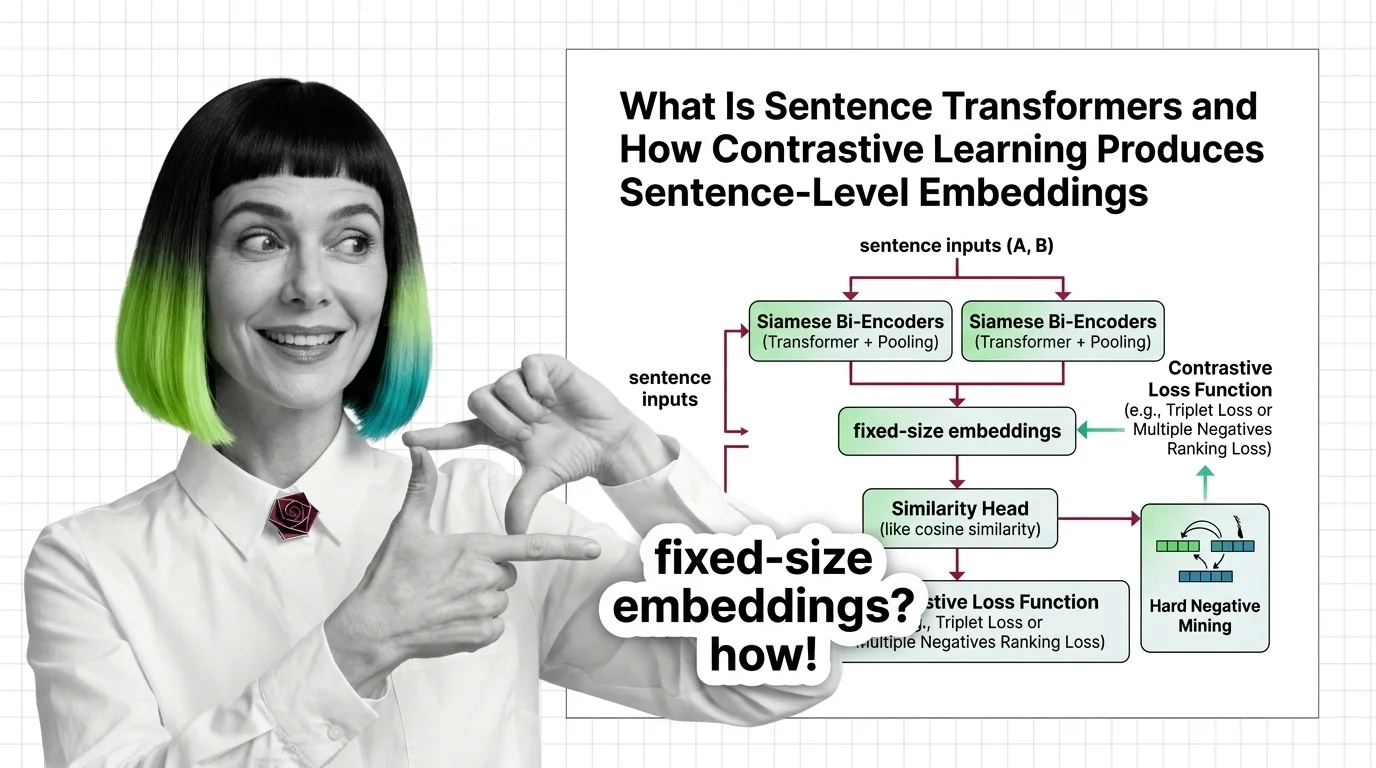
Table of Contents
ELI5
Sentence Transformers is a framework that trains transformer models to compress full sentences into fixed-size vectors, so machines can compare meaning using simple distance math instead of expensive pairwise inference.
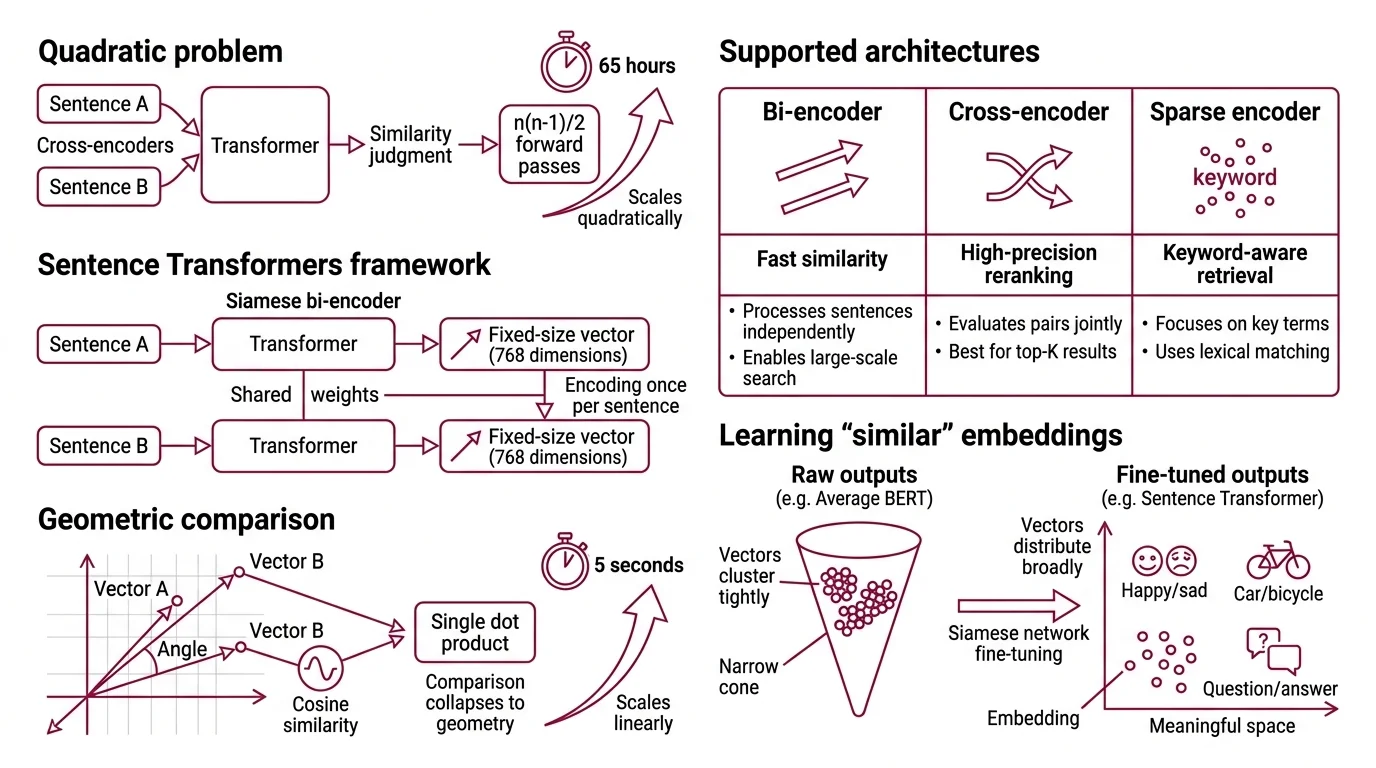
BERT was supposed to understand language at the sentence level. And in isolation, it does — feed two sentences through a cross-encoder and the similarity score is excellent. But when Reimers and Gurevych needed to find the most similar pair among 10,000 sentences, BERT required approximately 65 hours of pairwise comparisons. The same task, restructured through a siamese bi-encoder, completed in about 5 seconds (Reimers & Gurevych 2019).
That is not an optimization. That is an architectural correction.
The Sixty-Five-Hour Wall
The problem was never comprehension. Cross-encoders — where both sentences pass through the transformer jointly — produce excellent similarity judgments. But they require evaluating every possible pair. For n sentences, that means n(n-1)/2 forward passes. Scale does not penalize you linearly; it punishes you quadratically.
What the Sentence Transformers framework did was reframe the question: instead of asking “how similar are these two sentences?” for every combination, it asks “where does each sentence live in vector space?” — and then lets geometry handle the rest.
What is the Sentence Transformers framework and how is it different from regular transformer embeddings?
Sentence Transformers is a Python framework, built on PyTorch and Hugging Face Transformers, that converts pre-trained transformer models into sentence-level Embedding encoders. The architectural difference is structural: instead of feeding two sentences through one model simultaneously (cross-encoding), it processes each sentence independently through a shared-weight network — a siamese bi-encoder — and outputs a fixed-size vector for each.
Once you have vectors, comparison collapses to geometry. Cosine similarity between two 768-dimensional vectors is a single dot product. No forward pass required. This is what collapsed 65 hours into 5 seconds; the encoding happens once per sentence, not once per pair, and the comparison itself becomes arithmetic.
The framework now hosts thousands of pretrained models on Hugging Face and supports three distinct architectures: bi-encoders for fast similarity, cross-encoders for high-precision reranking, and sparse encoders for keyword-aware retrieval (SBERT Docs).
The Geometry of Learning “Similar”
Raw transformer outputs are not meaningful sentence embeddings. Average BERT’s token-level outputs without fine-tuning and you get vectors that cluster tightly in a narrow cone of the embedding space — a phenomenon sometimes called the anisotropy problem. Sentences with wildly different meanings land near each other because the base model was never trained to separate them at the sentence level.
Contrastive learning fixes this by reshaping the geometry itself.
How does contrastive learning with siamese bi-encoder networks produce fixed-size sentence embeddings?
The siamese architecture duplicates the transformer into two identical branches sharing the same weights. Sentence A enters one branch; sentence B enters the other. Each branch produces token-level representations, which are then collapsed into a single vector through a pooling layer — Mean Pooling by default, averaging all token embeddings into one fixed-size representation (SBERT Docs).
The contrastive training objective does the geometric work. Given a batch of anchor-positive pairs, the loss function pushes matching sentences closer together in vector space while pushing non-matching sentences apart. The model never learns “what a sentence means” in any philosophical sense. It learns a distance function that encodes semantic similarity as spatial proximity.
The original Sentence-BERT paper added a softmax classification head during training for natural language inference — predicting whether sentence pairs entail, contradict, or are neutral. At inference time, the classification head is discarded. Only the encoder and pooling layer survive. The sentence vector is the product; the training apparatus is scaffolding.
What role do hard negative mining and in-batch negatives play in Sentence Transformers training?
A contrastive model is only as discriminating as its negatives. If the “wrong” examples in your training batch are obviously wrong — comparing “The cat sat on the mat” with “Quarterly earnings exceeded projections” — the model learns nothing useful. It needs negatives that are almost right; the cases that sit near the decision boundary.
In-batch negatives are the simplest strategy: within each training batch, every positive pair’s anchor treats every other pair’s positive as a negative. A batch of 64 pairs yields 63 negatives per anchor automatically, with no additional data collection. MultipleNegativesRankingLoss, the framework’s recommended default, implements exactly this using the InfoNCE objective (SBERT Loss Overview).
Hard negative mining sharpens the blade further. The mine_hard_negatives() function uses an existing embedding model to find sentences that are semantically close to the anchor but are not true positives — then an optional cross-encoder rescoring step filters out false negatives that actually are valid matches (SBERT Docs).
The effect is precise: hard negatives force finer-grained distinctions in regions of the embedding space where sentences cluster ambiguously. Without them, the model draws coarse neighborhood boundaries. With them, it carves sharper ones.
Inside the Training Stack
Loss functions, pooling strategies, and training heads are not interchangeable accessories. Each one directly alters the geometry of the output space, and swapping one component can shift where your sentences land by enough to break downstream retrieval.
What are the loss functions, pooling strategies, and training heads in Sentence Transformers?
Pooling determines how token-level outputs collapse into a sentence vector. Sentence Transformers supports six modes: CLS token, last token, max-over-time, mean, length-weighted mean, and square-root-length-weighted mean. Mean pooling is the default when initializing from a base Transformers model — and for most tasks it outperforms CLS pooling, because averaging distributes information across the full token sequence rather than compressing it into a single position.
Loss functions define the training signal. The framework’s recommended losses divide into two families:
| Loss | Input Format | Mechanism |
|---|---|---|
| MultipleNegativesRankingLoss | (anchor, positive) pairs | InfoNCE with in-batch negatives |
| CoSENTLoss | (sentence_a, sentence_b, score) | Pairwise ordering; recommended over CosineSimilarityLoss |
| MatryoshkaLoss | Wrapper around any loss | Trains at multiple dimensionalities simultaneously |
MatryoshkaLoss deserves separate attention. It enables Multi Vector Retrieval efficiency by training embeddings that remain performant even when truncated to smaller dimensions — 256 or 128 instead of 768 — without notable performance degradation. You train once; you choose your speed-accuracy tradeoff at inference time.
Training heads sit between the pooling layer and the loss function during training. For classification tasks (NLI), a softmax head maps concatenated sentence vectors to class probabilities. For regression tasks (STS), a cosine similarity layer computes the score directly. These heads are training scaffolding — discarded at inference. The sentence vector is the only artifact that survives.
Where the Geometry Holds — and Where It Fractures
If your downstream task is Similarity Search Algorithms over semantically distinct documents — retrieval, clustering, deduplication — the bi-encoder architecture gives you sub-second comparisons at scale. Pair it with Vector Indexing and approximate nearest neighbor search, and you have a retrieval system that scales to millions of entries.
If you change the domain without retraining, expect degradation. A model fine-tuned on scientific abstracts will encode legal contracts into a geometry it was never taught to differentiate. The embeddings will cluster, but the clusters will not mean what you need them to mean.
If you need comparison precision above a threshold — reranking the top candidates for exact match — switch from bi-encoder to cross-encoder for that final stage. The architectural tradeoff is explicit: you buy speed at the cost of pairwise interaction, and you buy precision by giving it back.
When it breaks: Sentence Transformers embeddings degrade on out-of-distribution text and on tasks requiring fine-grained negation sensitivity. A model may place “The patient has no fever” and “The patient has a fever” close together in vector space, because token overlap dominates the negation signal — a fundamental limitation of distributional similarity.
Compatibility notes:
- SentenceTransformer.fit(): Soft-deprecated since v3. Use
SentenceTransformerTrainerfor new training pipelines.- encode_multi_process(): Deprecated. Use
encode()withdevice,pool, andchunk_sizearguments instead.
The Data Says
Sentence Transformers solved a concrete problem: making sentence-level semantic comparison computationally tractable. The mechanism is contrastive learning applied through siamese bi-encoders — reshaping vector geometry so that spatial distance encodes meaning. The framework’s lasting value is not any single model but the training infrastructure that lets you build one tuned to your domain, your data, and your definition of “similar.”
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors