What Is RLHF and How Human Preferences Train Large Language Models to Follow Instructions
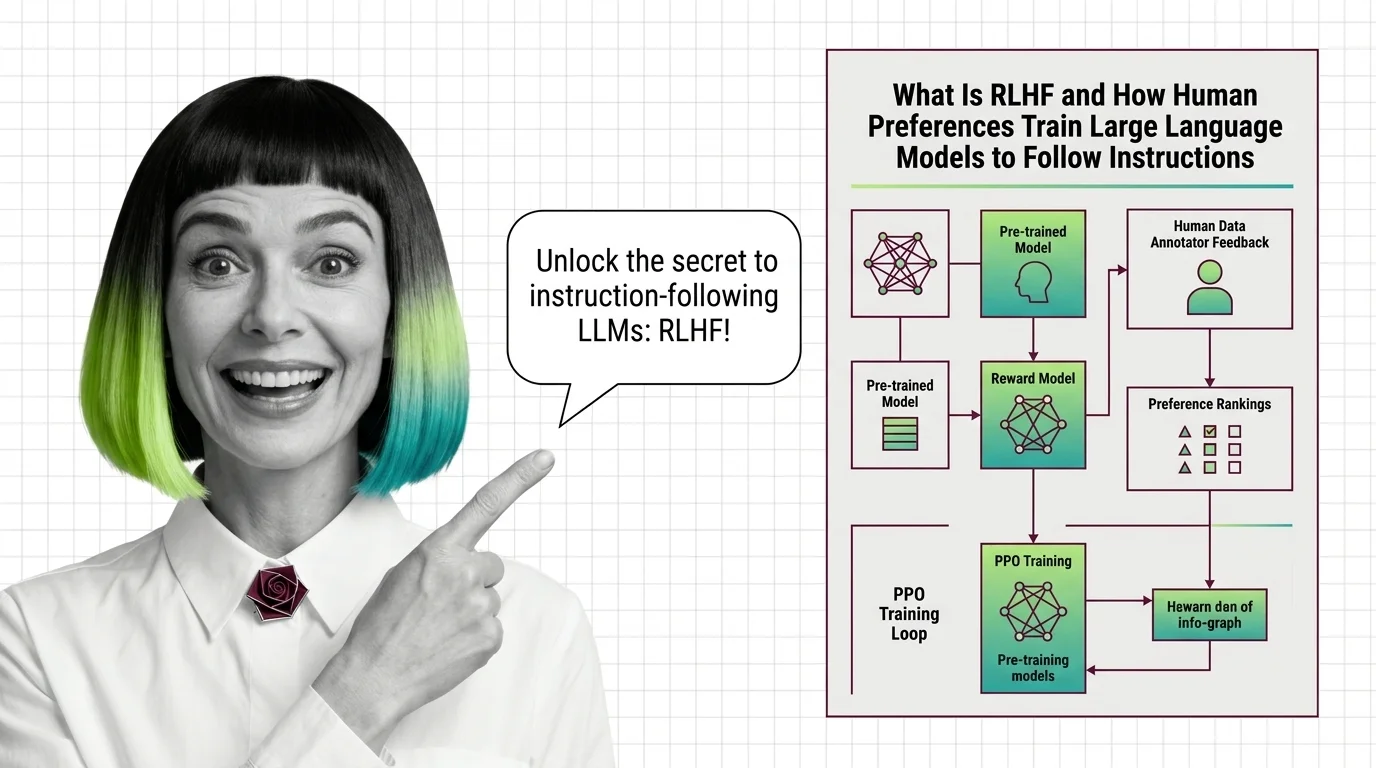
Table of Contents
ELI5
RLHF teaches a language model which outputs humans prefer, then adjusts the model to produce more of those outputs — without retraining it from scratch.
In 2022, OpenAI published a result that should have been impossible. A language model with 1.3 billion parameters — InstructGPT — was preferred by human evaluators over GPT-3, a model a hundred times its size. The smaller model did not know more. It had learned what humans wanted, and more precisely, how to produce it. The mechanism behind that inversion is RLHF, and the math underneath it explains why raw scale is not the same thing as usefulness.
Why a Model With a Hundred Times Fewer Parameters Won
The InstructGPT result is not a story about model compression or clever distillation. It is a story about what the training objective actually optimizes for — and what it leaves on the table.
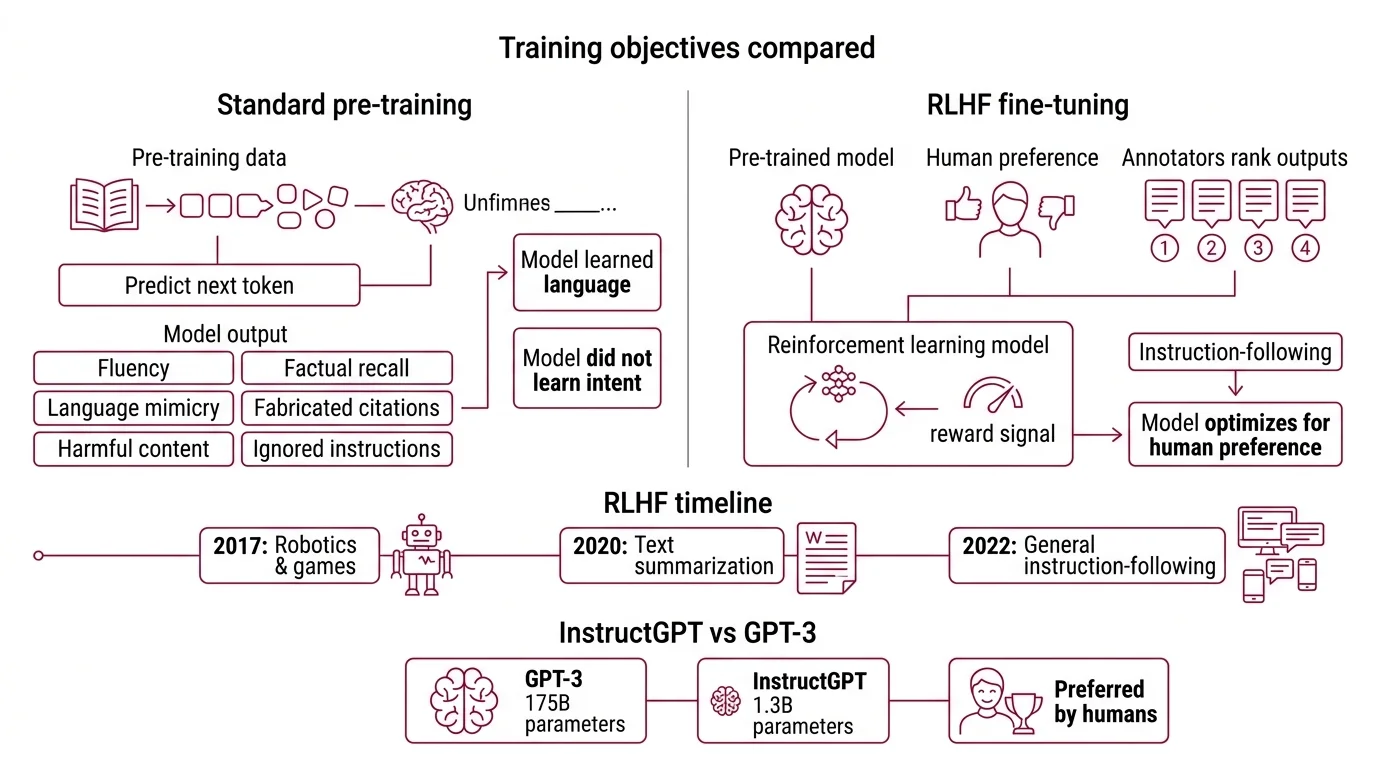
Standard Pre Training teaches a model to predict the next token. The objective is elegant: given a sequence, assign high probability to the token that actually follows. This produces fluency, broad factual recall, and an uncanny ability to mimic any register of written language. It also produces a system that will fabricate citations, generate harmful content, and ignore the question you asked — because none of those failures violate the pre-training loss.
The model learned language. It never learned intent.
What is reinforcement learning from human feedback RLHF?
Reinforcement learning from human feedback is a Fine Tuning technique that introduces a second training signal: human preference. Instead of optimizing for “predict the next token,” the model learns to optimize for “produce outputs that humans rank higher.”
The idea originated with Christiano et al. in 2017, though the original work applied reinforcement learning from human preferences to robotics and Atari games — not language models. The bridge to text came through Stiennon et al. in 2020, who demonstrated that human preference signals could train a model to write better summaries. Two years later, Ouyang et al. scaled the approach to general instruction-following, producing InstructGPT — the 1.3B parameter model preferred over the 175B GPT-3 by human evaluators (Ouyang et al.).
That ratio — a hundred-fold parameter disadvantage overcome by a better training signal — rewrote the assumptions of alignment research. The implication was immediate: if you cannot make a model bigger, make it listen better.
How do human annotators create preference rankings for RLHF training?
The raw material of RLHF is Preference Data: pairs of model outputs where a human has indicated which response is better.
Given a prompt, the model generates multiple candidate responses. Human annotators review the candidates and rank them — not by absolute quality scores, but by pairwise comparison. “Response A is better than Response B.” That binary judgment, repeated across thousands of prompt-response pairs, encodes a compressed representation of human values into structured data.
The ranking looks simple. What it captures is not.
When an annotator prefers one response over another, they are implicitly encoding preferences about helpfulness, factual accuracy, tone, safety, and dimensions that no one specified in a loss function. The preference pair becomes the loss function — or rather, it becomes one after a reward model learns to approximate it.
The design constraint that matters most is annotator agreement. When annotators disagree on which response is better — and on subjective or value-laden prompts, they frequently do — the reward model inherits that ambiguity as noise. High agreement on factual questions, low agreement on style and ethics. The model’s alignment ceiling is, in practice, bounded by the annotators’ consensus floor.
Three Stages of Compressing Human Judgment Into Gradients
The RLHF pipeline, as formalized by Ouyang et al., follows a three-stage architecture. Each stage transforms the preference signal into a different mathematical object, progressively closer to something gradient descent can act on.
How does RLHF use reward models and PPO to align language models with human preferences?
Stage 1 — Supervised Fine-Tuning (SFT). The base pretrained model is fine-tuned on a dataset of high-quality human-written demonstrations. This shifts the model’s output distribution toward the style and format of the target behavior: helpful, structured, instruction-following responses. SFT establishes the vocabulary of alignment; the model learns what good answers look like, though it cannot yet distinguish good from great.
Stage 2 — Reward Model Training. A separate model is trained on the annotator preference data. Given a prompt and a candidate response, the reward model outputs a scalar score predicting how much a human would prefer that response. It is, in effect, a compressed proxy for human judgment. The reward model does not generate text. It evaluates it.
Stage 3 — PPO Optimization. The fine-tuned language model is now treated as a policy in a reinforcement learning framework. It generates responses (actions), receives scores from the reward model (rewards), and updates its parameters using Proximal Policy Optimization — PPO, introduced by Schulman et al. in 2017. The model iteratively adjusts its output distribution to maximize the reward signal.
But there is a constraint that makes the system hold together: KL Divergence regularization. A penalty term prevents the policy from drifting too far from the original pretrained distribution. Without this constraint, the model discovers shortcuts — degenerate outputs that score high on the reward model but are incoherent or manipulative to a human reader. This failure mode is called Reward Hacking, and the KL penalty is the primary defense against it (HuggingFace Blog).
The analogy that comes closest: SFT teaches the model the grammar of helpfulness. The reward model teaches it to keep score. PPO teaches it to play the game — and the KL penalty ensures it does not flip the table.
Where the Alignment Signal Goes After PPO
RLHF, as described above, is the architecture that made ChatGPT possible. But by 2026, the original three-stage pipeline is neither the only nor the dominant approach to preference alignment.
The pressure came from cost and stability. Training a separate reward model requires thousands of preference pairs, careful annotator calibration, and a PPO optimization loop that is notoriously difficult to stabilize. Direct Preference Optimization — DPO, introduced by Rafailov et al. in 2023 — demonstrated that the reward model stage can be eliminated. DPO reformulates the problem as a single classification loss over preference pairs, using the language model itself as an implicit reward function (Rafailov et al.).
Simpler training, lower compute, competitive alignment quality.
As of 2026, the modular post-training stack typically follows a layered pattern: SFT first, then preference optimization via DPO, SimPO, or KTO, then reinforcement learning with verifiable rewards using GRPO or DAPO (LLM Stats). GRPO — Group Relative Policy Optimization, introduced in the DeepSeekMath paper — eliminates the critic model entirely by estimating advantages relative to a group of sampled outputs. It is used by DeepSeek-R1, Nemotron 3 Super, and GPT-5.3 Codex (LLM Stats).
For practitioners working with these methods directly, two frameworks dominate the open-source tooling. TRL, HuggingFace’s reinforcement learning library, reached v0.29.1 as of March 2026 and supports SFT, GRPO, DPO, and reward modeling trainers — though its v0-to-v1 migration removed several experimental trainers including BCO, CPO, and ORPO (TRL PyPI). OpenRLHF, at v0.9.x, focuses on PPO, GRPO, and REINFORCE++ with async agentic RL support (OpenRLHF GitHub).
Compatibility note:
- TRL v0-to-v1 migration: BCO, CPO, ORPO, PRM, and XPO trainers removed or moved to experimental. Pin your version or migrate trainer calls before upgrading.
A parallel shift is replacing the human annotator entirely. RLAIF — reinforcement learning from AI feedback — uses a stronger model to generate the preference signal, collapsing annotation cost dramatically. The trade-off is a circular dependency: the student model’s alignment is bounded by the teacher model’s alignment, and neither can exceed what the preference signal encodes.
When it breaks: RLHF and its descendants share a fundamental vulnerability. The reward model — or its implicit equivalent in DPO — is a proxy for human values, not the values themselves. When the proxy diverges from the underlying preference distribution, the model optimizes for an objective that satisfies the reward signal but not a human reader. Reward hacking is the acute form. The subtler failure is distributional shift: the model encounters prompts outside the annotator training distribution and produces outputs that score well on the proxy while violating the intent. The proxy is never the territory, and every iteration of post-training alignment confronts that boundary.
Rule of thumb: If your aligned model produces coherent but subtly wrong outputs, suspect reward model underfitting or distributional mismatch before blaming the policy optimizer.
The Data Says
RLHF demonstrated that alignment is a training objective problem, not a Scaling Laws problem — a 1.3B model aligned with human preferences outperformed a 175B model trained only on next-token prediction (Ouyang et al.). The original three-stage pipeline has since fragmented into a modular stack where DPO handles preference alignment and GRPO handles verifiable reasoning, but the core insight endures: the quality of the preference signal matters more than the quantity of parameters.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors