What Is Reward Model Architecture and How Bradley-Terry Scoring Shapes LLM Alignment
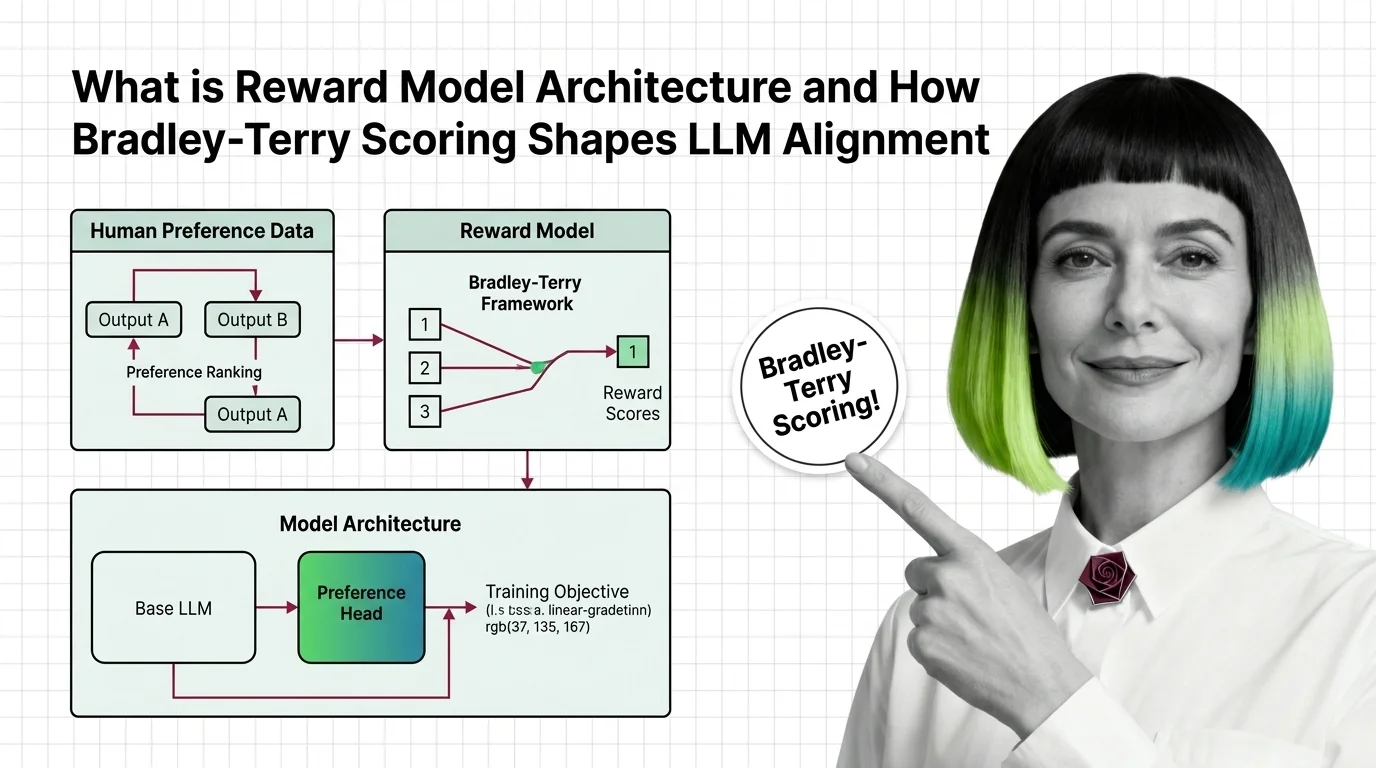
Table of Contents
ELI5
A reward model is a neural network trained to score AI responses the way a human would — higher for helpful answers, lower for bad ones. It learns scoring from thousands of human preference comparisons.
Ask a hundred people what makes a good AI response and you will get a hundred different answers — most of them contradictory. But show the same hundred people two responses side by side and ask “which one is better?” and something curious happens: they converge. Not on a definition of quality, but on a ranking. That gap — between the inability to articulate preference and the ability to express it through comparison — is the exact asymmetry that reward models in RLHF exploit.
The Machine That Learns What ‘Better’ Means
Reward models exist because writing explicit rules for “good AI output” fails the moment you try it. Is concise better than thorough? Is formal better than direct? The answer shifts with every context, every prompt, every user. But given two candidate responses side by side, a human annotator can almost always point at one and say: that one.
A reward model converts that pointing gesture into a differentiable signal.
What is a reward model architecture in RLHF?
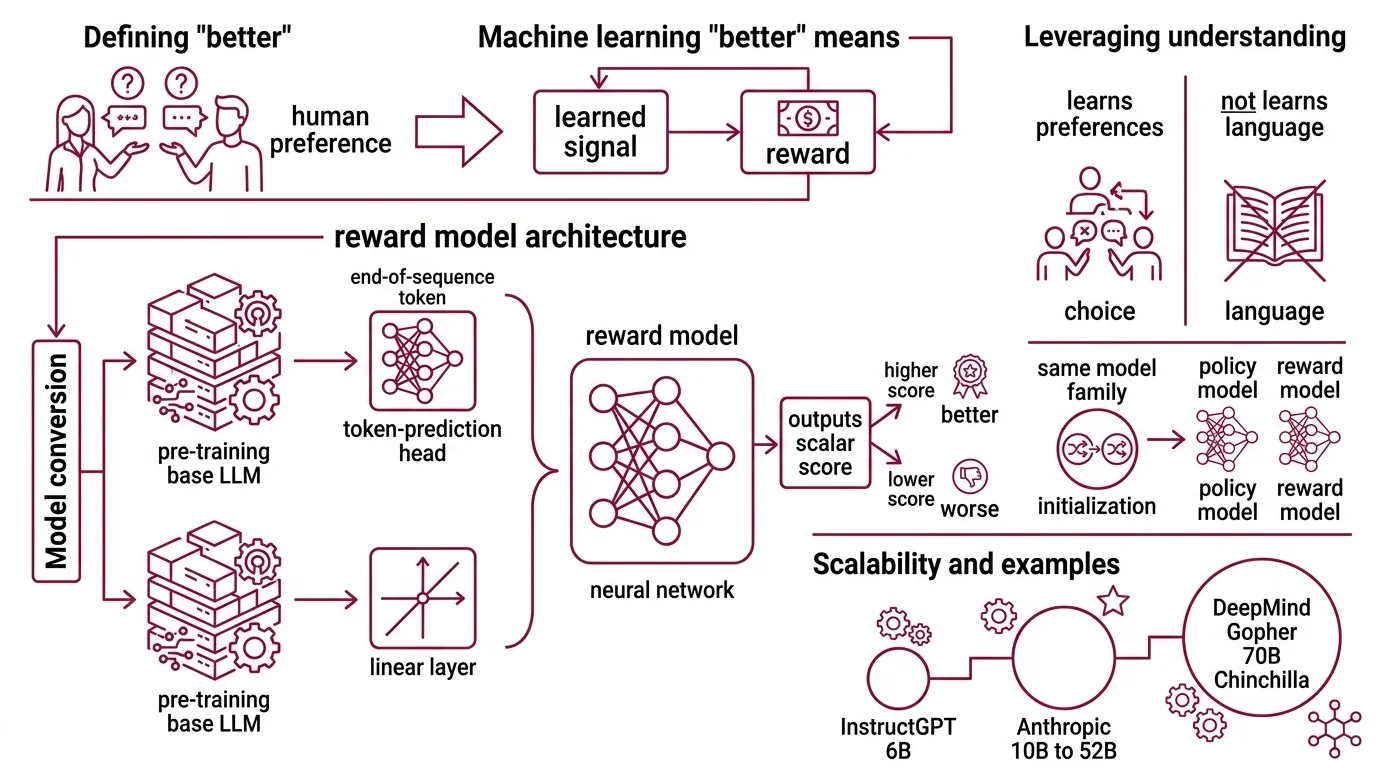
A reward model in RLHF is a neural network — typically a large language model with its generation head replaced by a single linear layer — that takes a prompt-response pair as input and outputs a scalar score. The higher the score, the more the response aligns with learned human preferences.
The architecture is deceptively minimal. Take a
Pre Training base LLM, remove the token-prediction head, and attach a linear projection from the final hidden state at the end-of-sequence token to a single floating-point number (RLHF Book). That number is the reward. In practice, libraries like HuggingFace’s AutoModelForSequenceClassification handle this abstraction — same transformer backbone, different output layer.
The key insight is that the base model already understands language. It has already compressed millions of patterns about coherence, style, factuality, and reasoning during pre-training. The reward head doesn’t need to learn language from scratch; it only needs to learn which patterns humans prefer over others.
This is why reward models are almost always initialized from the same model family as the policy they will later train. InstructGPT’s team explored reward models at multiple scales and settled on 6B parameters for the final model (Ouyang et al.). Anthropic scaled their reward models from 10B to 52B parameters, while DeepMind used a 70B Chinchilla-based reward model for their 280B Gopher (HuggingFace Blog).
Not a quality detector. A preference compressor.
How does a reward model learn human preferences from pairwise comparisons?
Training data for a reward model looks nothing like training data for a language model. Instead of text and next-token labels, you get triplets: a prompt, a chosen response (the one the human preferred), and a rejected response (the one the human did not prefer).
InstructGPT was trained on approximately 50,000 such labeled preference samples (Ouyang et al.). Each sample encodes a single human judgment — not “this response is good” but “this response is better than that one.”
The training objective pushes the model to assign a higher scalar score to the chosen response than to the rejected one. The absolute values of those scores are meaningless. Only the gap between them carries information. If the model scores the chosen response at 2.3 and the rejected at 1.1, that is equivalent — in terms of the training signal — to scoring them at 7.8 and 6.6.
The model learns a ranking function, not a rating function.
A rating function would need calibration — what does a score of 4.5 mean in absolute terms? A ranking function only needs consistency: if humans prefer A over B and B over C, the model should assign scores where r(A) > r(B) > r(C). The absolute magnitudes are free parameters. This distinction has a practical consequence — you cannot compare reward scores across different models or even across different training runs of the same architecture.
A Formula From 1952 Inside Every Aligned LLM
The mathematical framework that makes pairwise preference learning tractable was not invented for AI. It was invented for chess.
How does the Bradley-Terry framework convert preference rankings into scalar reward scores?
In 1952, Ralph A. Bradley and Milton E. Terry published a model for estimating the relative strength of competitors from pairwise comparison data — building on ideas Ernst Zermelo had explored in the 1920s for ranking chess players. The core formula is elegant:
P(i beats j) = sigma(r_i - r_j)
where sigma is the sigmoid function and r_i, r_j are the “strength” scores of the two competitors. The probability that player i beats player j depends only on the difference in their scores — not on their absolute values.
When applied to RLHF, the “players” become response candidates and the “match outcome” becomes a human annotator’s preference. The reward model assigns a score r(y|x) to each response y given prompt x, and the probability that the chosen response y_c is preferred over the rejected response y_r becomes:
P(y_c > y_r | x) = sigma(r(y_c|x) - r(y_r|x))
The loss function follows directly:
L = -log(sigma(r(y_c|x) - r(y_r|x)))
This is a binary cross-entropy loss on the preference pair — the model is penalized when it assigns a higher score to the rejected response (RLHF Book). Training minimizes this loss across all preference pairs in the dataset, gradually shaping the reward surface.
The sigmoid turns a difference into a probability. That is the entire trick. Every preference pair becomes a gradient signal that nudges the chosen response’s score up and the rejected response’s score down — relative to each other, never in absolute terms.
What are the key components of a reward model architecture — preference head, base LLM, and training objective?
Three components, tightly coupled:
Base LLM. The pretrained transformer that provides language understanding. Larger base models generally produce better reward models — not because they score more accurately in isolation, but because they represent the input space more richly. The final hidden state at the end-of-sequence token carries a compressed representation of the entire prompt-response pair.
Preference head. A single linear layer that projects the hidden state to a scalar. This is the only new parameter added during reward model training. Everything else is Fine Tuning of existing weights. The simplicity of this head is deliberate: the representational heavy lifting happens in the transformer, not in the output layer.
Training objective. The Bradley-Terry loss applied to human preference pairs. The objective does not require the model to output a specific score — only to produce a score difference that correctly reflects the human preference direction. This is why reward model scores live on an arbitrary scale and cannot be compared across different models.
Anthropic introduced Preference Model Pretraining (PMP), which pre-trains the reward model on a large corpus of preference-like data before fine-tuning on human comparisons. The motivation is sample efficiency: human preference data is expensive to collect, so extracting more signal from each labeled pair matters.
When the Reward Signal Lies
The Bradley-Terry framework makes a clean assumption: preferences are transitive. If humans prefer A over B and B over C, they should prefer A over C. In practice, human preferences are noisy, context-dependent, and sometimes contradictory.
The independence from irrelevant alternatives assumption — that the preference between two items does not change when a third option appears — breaks routinely in real annotation data (Sun et al.). The model learns a consistent ordering that the actual annotators never held. When the preference data is clean and abundant, this imposed consistency produces gradients that reliably improve the policy. When the data is sparse or contradictory, those same gradients can push the policy toward outputs that exploit the reward model’s simplifications — a phenomenon called reward hacking.
The Scaling Laws that govern language model capability apply to reward models too, but in a less explored direction. Larger reward models generalize better to unseen preference patterns, yet they also become more confident in their scores — including on edge cases where the right answer is uncertainty, not conviction.
RewardBench, developed by the Allen Institute for AI (Lambert et al., 2024), was the first systematic benchmark for evaluating reward models across capability dimensions — chat, reasoning, and safety (AI2 Blog). It exposed a pattern: many reward models excelled at casual conversation preferences but failed on safety-critical ones. RewardBench v2, released in 2025, expanded to math, factuality, and precise instruction following, and demonstrated correlation between benchmark scores and downstream policy improvement in both best-of-N sampling and PPO training (RewardBench 2 paper).
The alternatives are converging fast. A 2025 ICLR paper proposed classification-based reward models — treating each prompt-response pair independently rather than as part of a pairwise comparison — to address BT’s struggle with sparse data and false transitivity (Sun et al.). Direct Preference Optimization (DPO) bypasses the explicit reward model entirely, learning an implicit Bradley-Terry reward function while directly optimizing the policy in a single supervised step. And Group Relative Policy Optimization (GRPO), which has gained significant traction since 2025, eliminates the separate reward model altogether by computing relative rewards within groups of sampled responses.
Security & compatibility notes:
- Rubric drift: Annotation rubric changes between data collection rounds can break reward model stability assumptions. If your preference dataset spans multiple rubric versions, validate score consistency across batches before training.
Rule of thumb: The reward model is only as stable as the annotation process that produced its training data. Change the rubric, and you change what the model means by “better.”
When it breaks: Reward models trained on narrow preference distributions — annotators from a single demographic with consistent style preferences — produce reward signals that look clean in training but collapse when the policy encounters out-of-distribution prompts. The model scores confidently, the policy follows the confident wrong signal, and nobody notices until the outputs are already in production.
The Data Says
Reward model architecture is a compression problem. Thousands of pairwise human judgments — each one subjective, noisy, context-dependent — get compressed into a scalar-valued function that speaks with the authority of a number. The Bradley-Terry framework makes this compression tractable by reducing preference to a sigmoid on a score difference. The cost is every assumption that reduction encodes: transitivity, independence, a single axis of quality. When those assumptions hold, the reward signal is effective. When they do not, the model optimizes for a version of “better” that no human ever endorsed.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors