What Is RAG and How LLMs Use Vector Search to Ground Their Answers
ELI5
RAG lets a language model fetch relevant documents from a vector index before answering, so its reply is grounded in real evidence — not only patterns it memorized during training. Retrieve first. Generate second.
The first time most engineers meet RAG, it looks deceptively simple: a search bar bolted onto ChatGPT. The model gets fresh facts, hallucinations disappear, business problem solved. Then real users ask real questions, and the model confidently quotes a document that does not exist. The architecture is doing exactly what it was designed to do — and that is the interesting part.
The Four Stages Hidden Behind the Word “RAG”
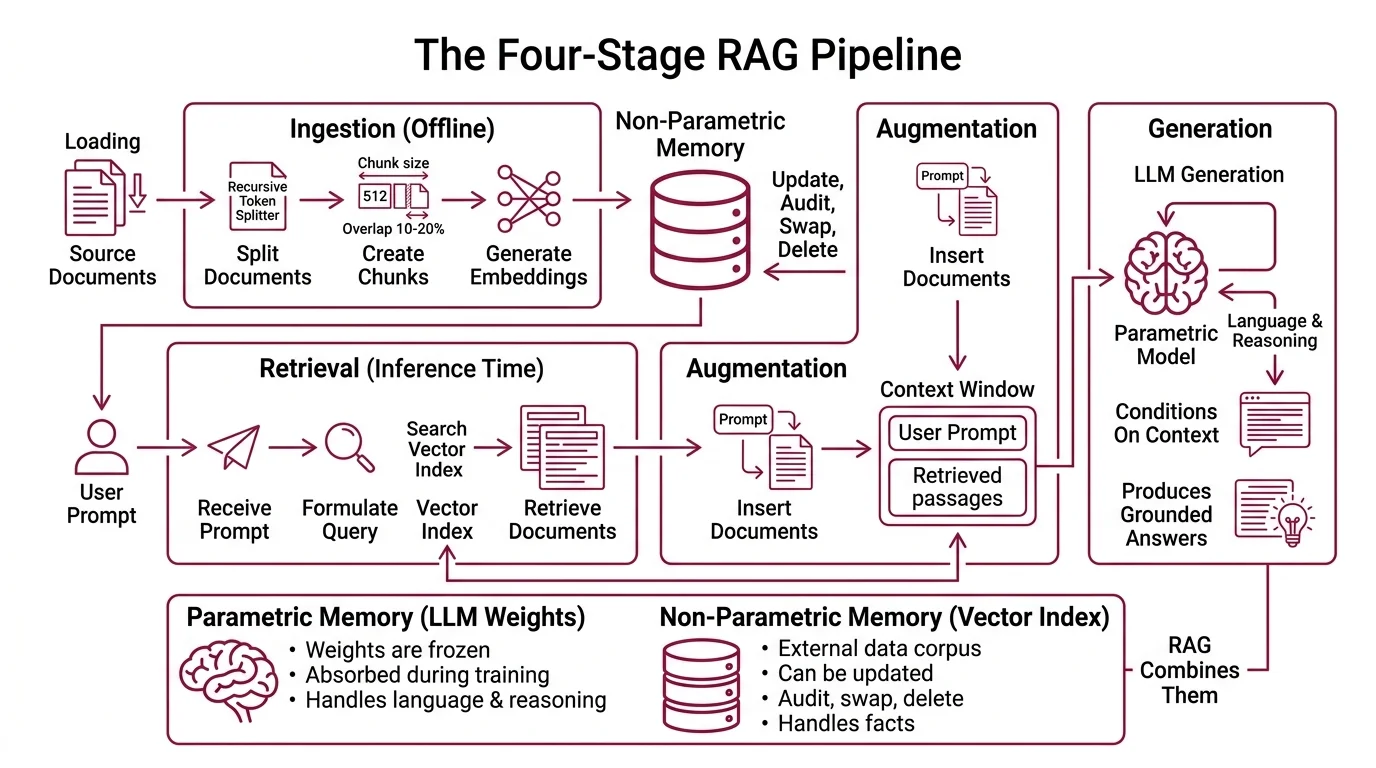
RAG is not a single algorithm; it is a four-stage pipeline — Ingestion, Retrieval, Augmentation, Generation — and each stage quietly reshapes what the model finally sees. Understanding the stages individually is the difference between debugging a broken RAG system and rebuilding one from scratch. The original 2020 paper paired a pre-trained sequence-to-sequence model (BART) with a dense vector index of Wikipedia, accessed via a neural retriever (Lewis et al., 2020).
What is retrieval-augmented generation (RAG) in simple terms?
RAG is the technique of giving a language model an external memory it can look things up in, on the fly, before it generates an answer. The model itself does not change. Its weights stay frozen; no fine-tuning, no retraining. What changes is the context window — the text the model conditions on at inference time. RAG inserts retrieved documents into that context window, so the next-token predictions are now constrained by passages from your corpus rather than relying solely on the parametric memory baked into the weights during pre-training.
The original formulation made the point cleanly: an LLM is parametric memory — it knows what it absorbed during training. A vector index is non-parametric memory — it can be updated, audited, swapped, deleted. RAG combines them. The parametric model handles language and reasoning; the non-parametric index handles facts.
Not a search bar bolted onto ChatGPT. A pipeline that reshapes the conditional probability distribution the model samples from.
How does RAG combine retrieval with an LLM to produce grounded answers?
Through four sequential stages, each with its own failure modes (Pinecone Learn).
Ingestion is the offline preparation. Source documents are split into chunks — typically around 512 tokens with a 10–20% overlap, using a recursive token splitter. Each chunk is run through an embedding model that maps text to a high-dimensional vector. Typical embedding dimensions sit between 768 and 3072 depending on the model: OpenAI’s text-embedding-3-small produces 1536-dimensional vectors, -large produces 3072. The vectors are stored in a vector index alongside the original chunk text. Tools like
LlamaIndex formalize this as a Document → Node → Index → Query Engine flow, where a Node is the atomic embeddable unit.
Retrieval happens at query time. The user’s question is embedded with the same model, and the index returns the top-k chunks whose vectors are closest to the query vector. Most production indexes use cosine similarity, though dot product and Euclidean distance are also valid choices depending on whether vectors are normalized.
Augmentation is the moment the retrieved chunks are stitched into a prompt. The system constructs a context that contains the user query plus the retrieved passages, often with explicit framing (“Answer using only the following sources…”). This is where most production prompt logic lives.
Generation is the final LLM call. The model receives the augmented prompt and produces the answer. Frameworks like LangChain orchestrate the entire flow, calling the embedding model, the vector store, and the generator LLM in sequence.
The four stages compose into one architectural promise: every claim in the answer should trace to a chunk in the index. When that promise breaks, the failure can usually be located at exactly one stage.
Where the Probability Gets Reshaped
The phrase “the model retrieves” makes RAG sound like database lookup. It is more interesting than that. The retrieved chunks do not bypass the LLM’s probability distribution — they reshape the conditional prior the model samples from. Every retrieved token in the prompt becomes a context token that influences attention, which influences which next tokens become likely. The retrieved evidence is not handed to the model as a fact; it is handed as conditioning.
How does a RAG pipeline flow from user query to final answer?
Trace one query through the system. A user asks: “What is our refund policy for enterprise customers in Germany?”
First, the query is embedded into a vector — a fixed-length array of floats that encodes its semantic position in the embedding space. Phrasings that mean similar things land in similar regions; the same question expressed three different ways produces three vectors in the same neighborhood.
Second, the index performs an approximate nearest-neighbor search and returns the top-k chunks (typically k = 10 to 50 in modern systems). Managed vector databases like Pinecone make this lookup sub-second across millions of vectors using algorithms such as HNSW.
Third, those candidates are reranked by a smaller, more expensive cross-encoder model that scores each (query, chunk) pair directly rather than via vector distance. Cohere Rerank v3.5, the current production default, supports over 100 languages and prices at $2.00 per 1,000 searches (Cohere Rerank page). Reranking trims the top-k down to a top-3 or top-5 that actually matter.
Fourth, the surviving chunks are assembled into the augmented prompt and sent to the generator LLM, which now has the relevant German enterprise refund clauses inside its context window. The model answers from those clauses — not from whatever fragment of refund-policy text it absorbed during pre-training.
The geometry here is the point. The same generator that would have hallucinated a refund policy is now generating tokens conditioned on a passage that contains the answer. The probability mass shifts. Not because the model is “looking up” the answer, but because the answer’s tokens have suddenly become much more likely than the alternatives.
The 2026 Production Default: Hybrid Search and Rerankers
A pure dense-vector RAG system was the 2023 default. By 2026, dense retrieval alone is no longer enough for serious workloads. Three paradigms now sit on the same spectrum — Naive, Advanced, and Modular RAG (Gao et al., RAG Survey) — and naive (single-step dense retrieval, no rerank) is mostly used in demos, not production.
The dominant production pattern is hybrid search: the index runs both a sparse retriever (BM25, which excels at exact keyword matches like product codes and proper nouns) and a dense retriever (which excels at semantic paraphrase). The two result lists are merged with Reciprocal Rank Fusion, then a reranker reorders the merged set. Benchmarks across enterprise corpora show recall uplifts of 5–30% versus dense-only retrieval (Superlinked VectorHub). Vertex AI, OpenSearch, Pinecone, Weaviate, and Milvus all now support hybrid search natively, so the architectural option is no longer gated by tooling.
Modular RAG goes further: the retrieval step itself becomes adaptive. The system decides whether to retrieve, what to retrieve, and whether to retrieve again based on intermediate model output. This is the foundation of Agentic RAG, where the LLM controls retrieval as a tool rather than receiving it as a fixed pre-step.
What the Pipeline Predicts (and Where It Quietly Breaks)
Once you see RAG as a probability-reshaping pipeline, certain failures stop looking surprising.
- If your chunks are larger than the model’s effective attention span for retrieved context, expect the model to ignore evidence buried in the middle of long passages — the “lost in the middle” effect.
- If your chunks straddle semantic boundaries (a sentence cut mid-thought), expect the embedding model to encode something incoherent, and expect retrieval recall to drop.
- If you skip the reranker, expect the top-k to contain plausible-but-wrong matches that the generator will faithfully cite.
- If your query distribution drifts from the corpus distribution, expect retrieval to silently degrade — the model will confidently answer questions for which the index has no good evidence.
Rule of thumb: every RAG bug is a retrieval bug until proven otherwise. The generator is the messenger; the retriever decides what the messenger has to work with.
When it breaks: RAG reduces hallucination but does not eliminate it. The LLM can still misuse retrieved context — fabricating around it, ignoring it, or stitching together plausible claims that contradict the evidence. Grounding is a prior; it is not a guarantee.
Compatibility notes:
- LangChain v1 (Oct/Nov 2025): Legacy chain classes (
LLMChain,AgentExecutor,ConversationBufferMemory,ConversationalRetrievalChain) moved to thelangchain-classicpackage. Old imports still work but emit deprecation warnings; removal is slated for 2.0. Migrate before upgrading (LangChain Docs).- Pinecone pod-based indexes: Marked legacy as of 2026 — Serverless v2 is the default plan. Existing pod code still functions, but new builds should target Serverless v2.
The Data Says
RAG is no longer a niche pattern. Enterprise adoption sits at 86%, with most organizations augmenting their LLMs with retrieval and vector databases rather than running base models alone (Squirro state-of-RAG). The frontier has shifted from “should we use RAG?” to “is our retrieval good enough?” — and the answer to the second question is almost always: not yet.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors