What Is Reranking and Why Cross-Encoders Rescore RAG Retrieval
ELI5
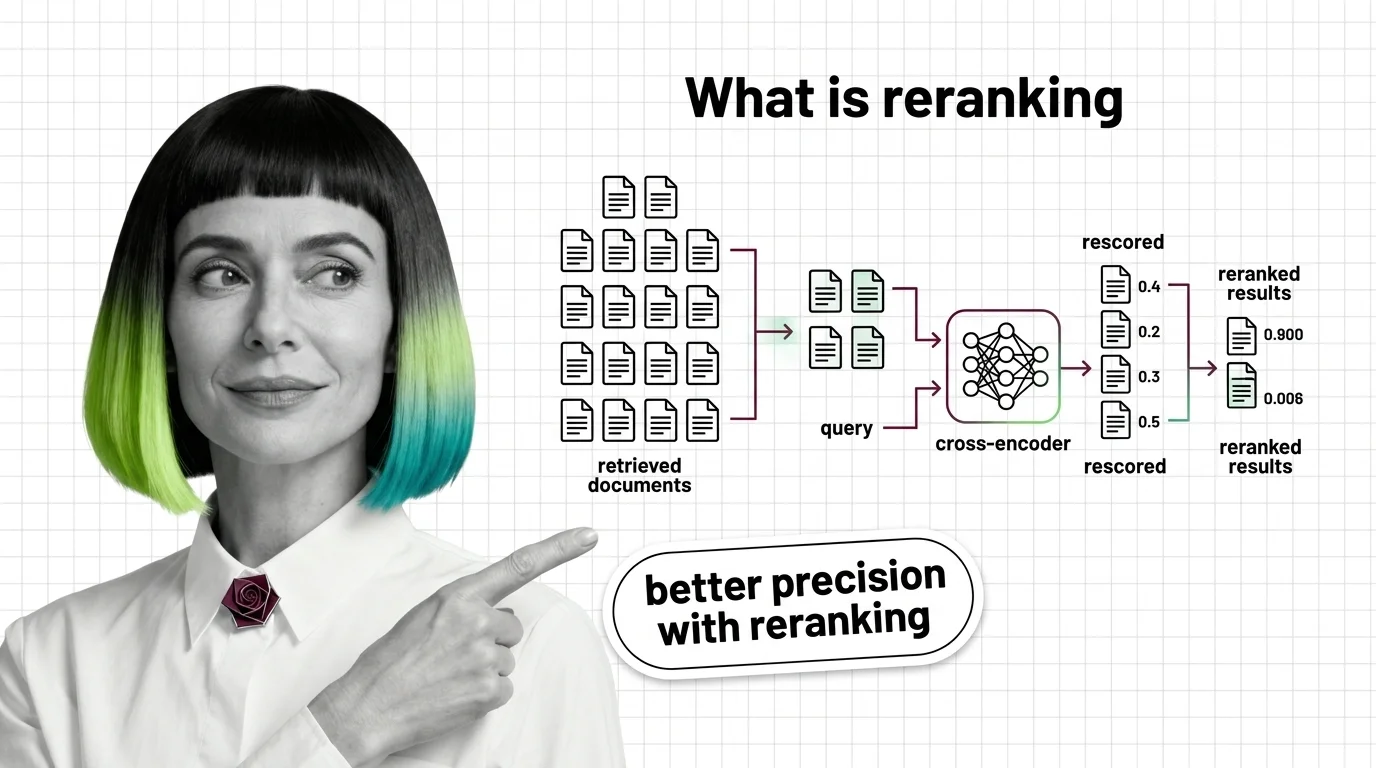
Reranking is a second-stage scoring pass over a small set of candidate documents. A cross-encoder reads each query-document pair together and outputs a relevance score, sharpening the order so the right answer ends up at the top.
Picture a Retrieval Augmented Generation pipeline running in production. Top-K vector search returns documents that look relevant — same vocabulary, same domain, plausible neighbors in embedding space — but the model still hallucinates. Inspect the rankings and the truth surfaces: the document that actually answers the user’s question sat at position 9, while position 1 was a confident decoy. That gap between “topically close” and “actually relevant” is the problem reranking exists to solve.
The Two-Pass Architecture Hidden Inside Production Retrieval
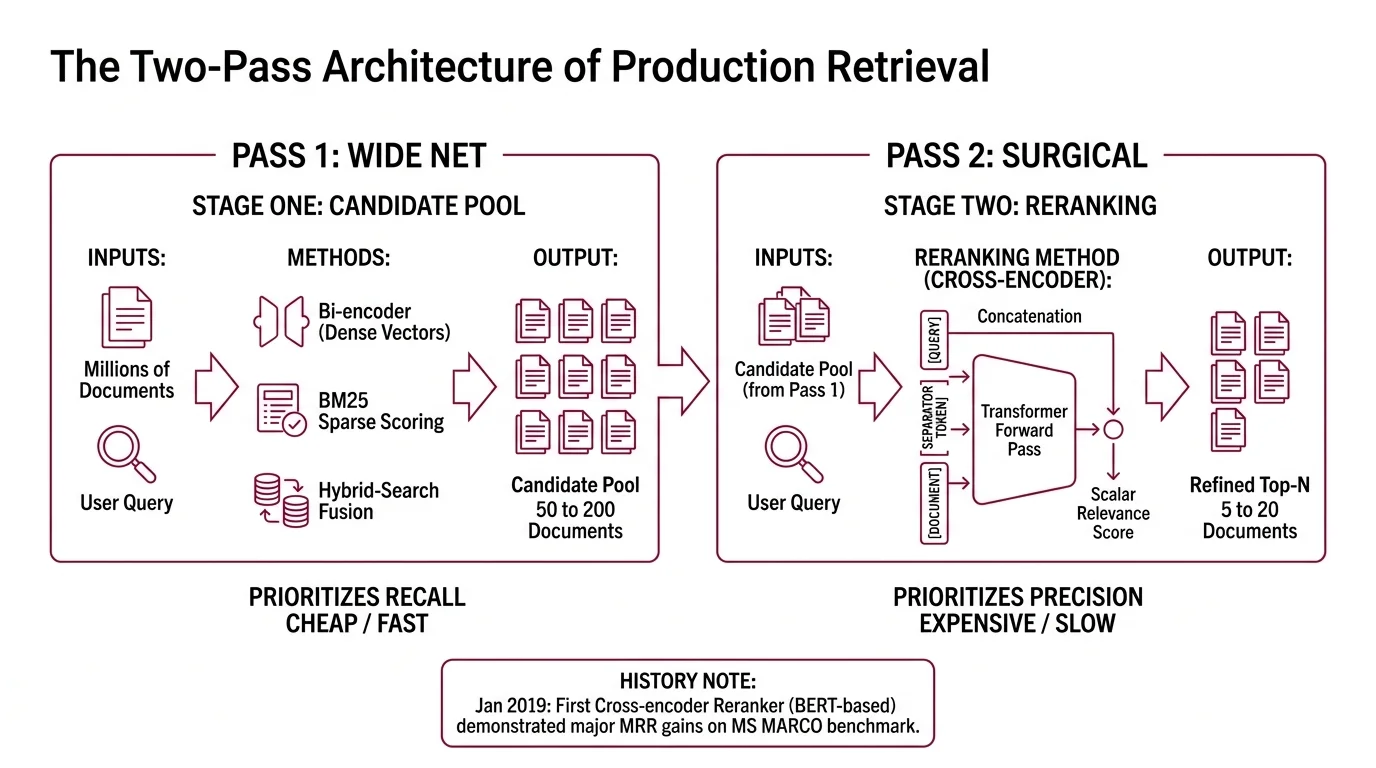
Modern retrieval pipelines do not pick top-N documents in a single shot. They make two passes over the corpus, each optimized for a different statistical objective. The first pass is fast and casts a wide net — recall over precision. The second pass is slow, expensive, and surgical — precision over recall. Reranking is what happens in pass two.
What is reranking in retrieval systems?
Reranking is the second of two retrieval stages. Stage one — a Bi-Encoder producing dense vectors, BM25 sparse scoring, or Hybrid Search fusing both — pulls a candidate pool of typically 50 to 200 documents from the full corpus. Reranking then rescores that pool with a more expensive model and returns a tighter top-N for the LLM to consume, usually 5 to 20.
The split is deliberate. Stage one operates over millions of documents and has to be cheap; it sacrifices ordering quality for index throughput. Stage two operates over a few hundred and can afford to be careful (Weaviate Blog).
The first viable Cross-Encoder reranker came from Nogueira & Cho’s “Passage Re-ranking with BERT” in January 2019. Their approach concatenated the query and a candidate passage into a single BERT input and trained the model to output a relevance probability. On the MS MARCO passage ranking task at the time, it took the top leaderboard spot with a 27% relative MRR@10 gain over the prior state of the art (arXiv). That figure belongs to that benchmark in 2019 — not to modern rerankers, which are evaluated against very different baselines.
The vendors have changed since. The two-pass shape has not.
How does a cross-encoder reranker score query-document pairs?
A cross-encoder takes a query and a document and treats them as one sequence. The query, a separator token, the document — concatenated, fed into a single transformer forward pass, and emerging as a scalar relevance score, typically between 0 and 1 (Sentence Transformers Docs).
The mechanism that matters is full self-attention across the joint sequence. Every query token can attend to every document token, and vice versa, at every transformer layer. The model is not comparing two pre-computed vectors; it is reading them together, the way a human reader compares a question to a paragraph and decides whether one answers the other.
This is the structural difference from a bi-encoder. A bi-encoder encodes the query once, encodes each document once, and reduces the comparison to a vector dot product. The query never sees the document during encoding. Whatever interaction happens between them happens in a single number at the end.
A cross-encoder refuses that compression.
Both sides shape each other’s representation throughout the forward pass. The cost is brutal: O(N) full transformer forward passes for N candidates, versus O(1) similarity per pair after indexing for a bi-encoder (Sentence Transformers Docs). That is exactly why nobody runs a cross-encoder over a million-document corpus — it would be intractable. Stage one exists to shrink N to something the cross-encoder can afford.
Why a Bi-Encoder Cannot Match Cross-Encoder Precision
The two architectures are not on a quality spectrum where one is “better.” They optimize different objectives under different constraints, and their failure modes are different.
Why does reranking improve precision compared to bi-encoder retrieval alone?
A bi-encoder collapses each document into a single vector before any query exists. That vector has to be a useful summary against every possible future query — a kind of pre-compressed gist of the document’s meaning. The geometry that lands a document near a query in embedding space is approximate by construction. Two documents that share vocabulary and topic can sit closer to a query than the document that actually contains the answer.
Cross-encoders do not have to commit before the query arrives. They see the query and the document together and can let the query reweight which parts of the document matter. A subordinate clause that disambiguates the answer, a negation that flips the meaning, a numeric figure that satisfies a specific constraint — these are the signals a bi-encoder routinely loses in compression and a cross-encoder is built to preserve.
Empirically, cross-encoder reranking on top of dense retrieval has been measured at nDCG@10 = 37.56 versus dense-only at 27.35 on representative IR benchmarks (Sentence Transformers Docs). Treat that gap as illustrative, not universal — typical reported uplifts span roughly 5 to 20 nDCG points depending on dataset, retriever, and reranker. The pattern is real. The exact magnitude is yours to measure.
That is why every serious RAG architecture in 2026 looks the same: a cheap stage-one retriever feeding a cross-encoder reranker that decides what the LLM actually reads.
The Reranker Market in April 2026
The reranker space is multi-vendor and moving fast. As of April 2026, several models share the frontier; no single name dominates across accuracy, latency, context length, instruction-following, and license simultaneously.
Cohere released Rerank 4 (rerank-v4.0-pro and rerank-v4.0-fast) on December 11, 2025, with a 32K-token context per query-document pair, support for 100+ languages, and a token-based pricing model at $2.50 per million input tokens for the Pro tier (Cohere Docs; Cohere’s pricing page). Rerank 4 replaced Rerank 3.5 as the recommended default.
Voyage released rerank-2.5 and rerank-2.5-lite on August 11, 2025 — Voyage’s first instruction-following rerankers, with a 32K context and accuracy gains of +1.85% and +3.40% over rerank-2 at the same per-token price (Voyage AI Blog). The Voyage Rerank family is hosted-only.
Jina released Jina Reranker v3 on October 3, 2025: a 0.6B-parameter open-weight model under CC-BY-NC 4.0, with a 131K-token context window and a “last but not late” Listwise Reranking architecture built on a Qwen3-0.6B backbone. Jina reports 61.94 nDCG@10 on BEIR — state of the art among the rerankers they evaluated (Jina AI Blog).
For Apache-licensed open weights, BAAI’s
BGE Reranker v2 family — bge-reranker-v2-m3 (568M parameters, multilingual), bge-reranker-v2-gemma, and bge-reranker-v2-minicpm-layerwise — remains the default open baseline (BAAI BGE Docs). MixedBread’s
Mixedbread Rerank v2, released February 2026 in 0.5B base and 1.5B large variants, adds reinforcement-learning training under the same Apache license (MixedBread Blog).
ZeroEntropy launched zerank-2 on November 18, 2025 — a hosted, multilingual, instruction-following cross-encoder priced at $0.025 per million tokens, positioned as an aggressive price-leader (ZeroEntropy Blog). Public details on parameter count and context window are not disclosed at launch; treat the precision claims as vendor-reported until you measure them on your data.
Cohere migration & deprecation note (effective dates already passed):
- Cohere Rerank 2.0 family: Model IDs
rerank-english-v2.0andrerank-multilingual-v2.0became unavailable on April 4, 2026; live code still referencing them will fail. Migrate to Rerank 4 (rerank-v4.0-proorrerank-v4.0-fast).- Cohere Rerank fine-tuning: Fine-tuning of rerank models is being retired; previously fine-tuned rerank instances lose access. Plan a hosted-base-model migration.
- Cohere Rerank 3.5: Still available but no longer current; Rerank 4 brings native semi-structured input handling and the new token-based pricing model.
What the Two-Pass Geometry Predicts
Once you see retrieval as a recall stage feeding a precision stage, several observable behaviors stop being mysterious:
- If your stage-one candidate pool is too small (top-10 or top-20), the reranker has nothing to rescue. The right document was never in the pool.
- If your stage-one pool is too large (top-1000), latency dominates. Cross-encoders are O(N) in candidates; doubling N doubles your reranker bill and tail latency.
- If your queries are short and lexically tight (“ICD-10 code for migraine”), a hybrid retriever often surfaces the right document near the top and reranking moves the needle less. Long, ambiguous, or paraphrased queries are where cross-encoder reranking earns its keep.
- If your reranker scores are bunched near zero across all top candidates, your retriever is feeding it garbage; precision cannot recover from absent recall.
Rule of thumb: Rerank only what you can afford to read carefully — the smallest candidate pool that still contains the right answer.
When it breaks: Cross-encoder latency. Production rerankers process 50 to 200 candidates per query through a full transformer forward each; under load, that becomes the latency floor of the whole pipeline. There is no clever indexing trick that escapes the O(N) cost — only smaller pools, smaller models, or batching that trades quality for throughput.
A Geometry Beyond Pointwise Scoring
Most production cross-encoders are pointwise — they score each query-document pair independently. Listwise rerankers like Jina v3 take the full candidate set as a single input and let the model decide ordering with all candidates visible at once. The intuition is that “best document for this query” is partly a comparative judgment, not a per-document property.
Listwise approaches are more expensive per call but can reduce inconsistencies that pointwise models exhibit when two near-tied documents need to be ordered. As Agentic RAG systems start querying retrieval as a tool inside multi-step reasoning loops, the cost of getting that ordering wrong compounds. The agent acts on the top result, and a misordering at step one cascades through every subsequent decision.
The Data Says
Reranking is not a quality knob you turn; it is the second axis of a system that decoupled recall from precision. Stage-one retrievers maximize the chance that the right document is somewhere in the top 50; cross-encoder rerankers do the joint reading that picks it out. The 5-to-20-point nDCG uplift reported across benchmarks is the visible effect; the structural reason is that a query and a document need to share attention layers, not a dot product.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors