What Is Red Teaming for AI and How Adversarial Testing Exposes Model Failures Before Deployment
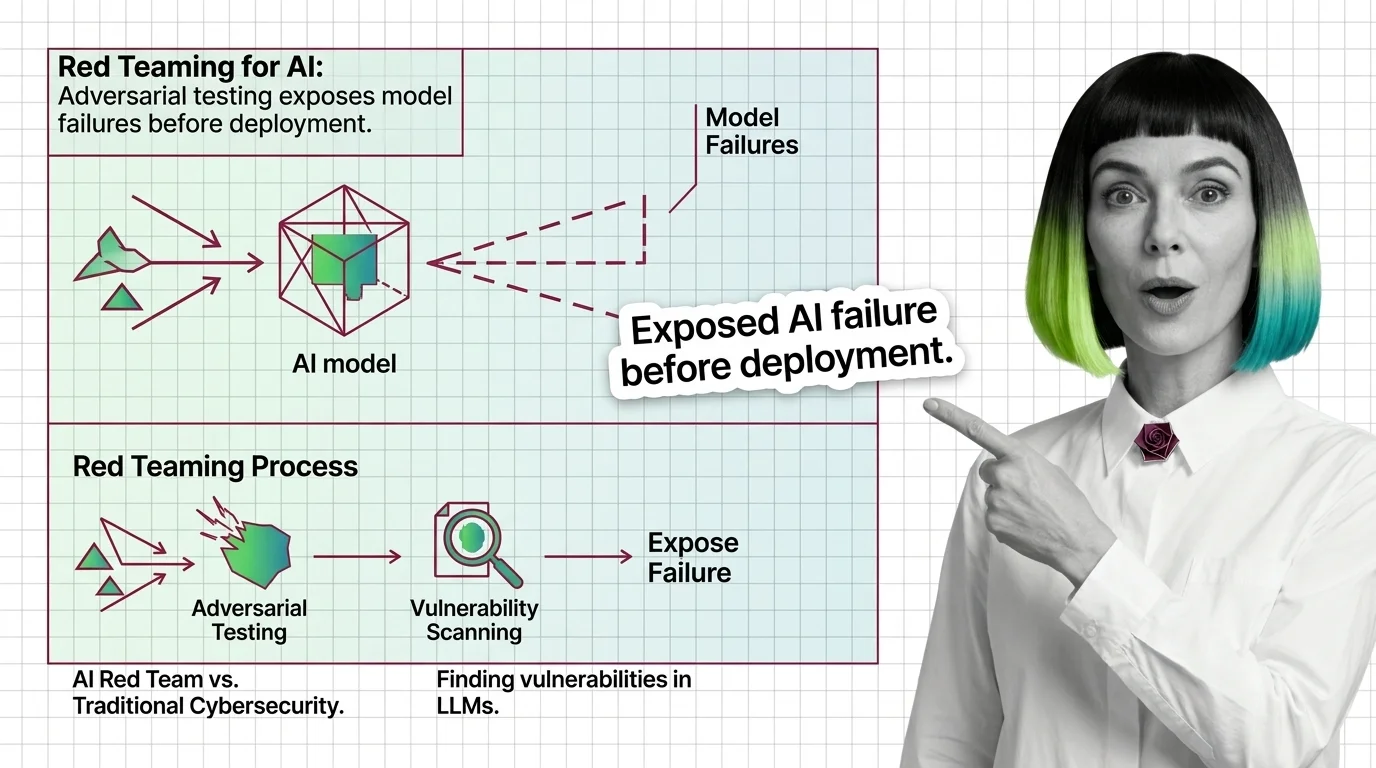
Table of Contents
ELI5
Red teaming for AI means deliberately attacking an AI system under controlled conditions to find the failures before real users do.
A language model passes every benchmark on the evaluation suite. Accuracy scores land in the high nineties. The safety team signs off. Three weeks after launch, a user discovers that rephrasing a blocked request as a bedtime story bypasses every safety filter the model has. The benchmarks didn’t lie. They just never asked the right wrong question.
What Happens When You Attack a Probability Distribution
The premise sounds simple: before your users find the failure modes, someone on your team should find them first. But AI systems fail in ways that don’t map onto traditional software bugs, and understanding why requires looking at what the attacker is actually targeting.
What is red teaming for AI?
Red teaming for AI is structured Adversarial Attack testing — a deliberate, methodical effort to make an AI system do things it was designed not to do. NIST’s formal definition describes it as “a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with developers of AI” (NIST CSRC).
The definition sounds bureaucratic. The practice is not.
A traditional software test asks: does this function return the correct output for a given input? An AI red team asks something fundamentally different: can we construct an input that makes the system produce an output its designers believed was impossible?
That distinction matters because language models don’t execute logic the way deterministic code does. They sample from probability distributions shaped by billions of parameters. A Guardrails layer — content filters, system prompts, safety fine-tuning — constrains those distributions. Red teaming probes whether those constraints hold under adversarial pressure, or whether they’re suggestions the model can be talked out of.
Not a QA pass. An adversarial experiment.
How does AI red teaming find vulnerabilities in large language models?
The attack surface of a large language model is not a network port or an API endpoint. It is the entire space of possible input sequences and the model’s learned responses to each one.
Red teams exploit this by constructing inputs designed to push the probability distribution into regions the safety training didn’t cover. The techniques fall into recognizable categories, though the taxonomy keeps expanding.
Prompt injection is the most persistent. The Owasp LLM Top 10 2025 edition lists it as the number-one vulnerability for the second consecutive year (OWASP). An attacker embeds instructions inside user-supplied data — a document, a web page, a database record — and the model follows those instructions because it cannot reliably distinguish its system prompt from injected content. The failure isn’t carelessness; it’s architectural. The model processes all tokens in its context window through the same attention mechanism, and no amount of prompt engineering has reliably solved the disambiguation problem.
Jailbreaking targets a different layer. Safety fine-tuning teaches the model to refuse certain requests, but that refusal is a learned behavior — a pattern in the weights, not a hard constraint. Red teams discover that encoding the same request in Base64, framing it as fiction, or translating it into an obscure language can shift the probability mass away from the refusal token and toward compliance. The model didn’t “decide” to comply; a different token sequence simply activated a different region of the distribution.
Then there are the structural attacks that bypass prompts entirely. Mitre Atlas cataloged 15 tactics and 66 techniques as of October 2025, with 14 new techniques added that year specifically for agentic AI systems (MITRE ATLAS). These include data poisoning — corrupting training or retrieval data so the model’s outputs are compromised before any user ever interacts with it — and embedding manipulation, where vector representations in a retrieval-augmented system get altered to surface attacker-controlled content.
Tools like Promptfoo automate much of this work, testing over 50 vulnerability types including jailbreaks, injections, RAG poisoning, and compliance violations (Promptfoo Docs). Promptfoo was acquired by OpenAI in March 2026 and remains open-source under MIT license, with over 350,000 developers using it (TechCrunch). The acquisition itself signals something worth noticing: the company building the frontier models decided it needed to own the tool that breaks them.
The Attack Surface That Doesn’t Have Walls
Not every vulnerability lives in the prompt. The deeper pattern — and the one that explains why AI red teaming keeps growing more complex — is that language models have no perimeter in the traditional sense. Traditional security assumes you can draw a boundary around the system and defend it. With a probabilistic model, the boundary is the space of all possible inputs, which is effectively infinite.
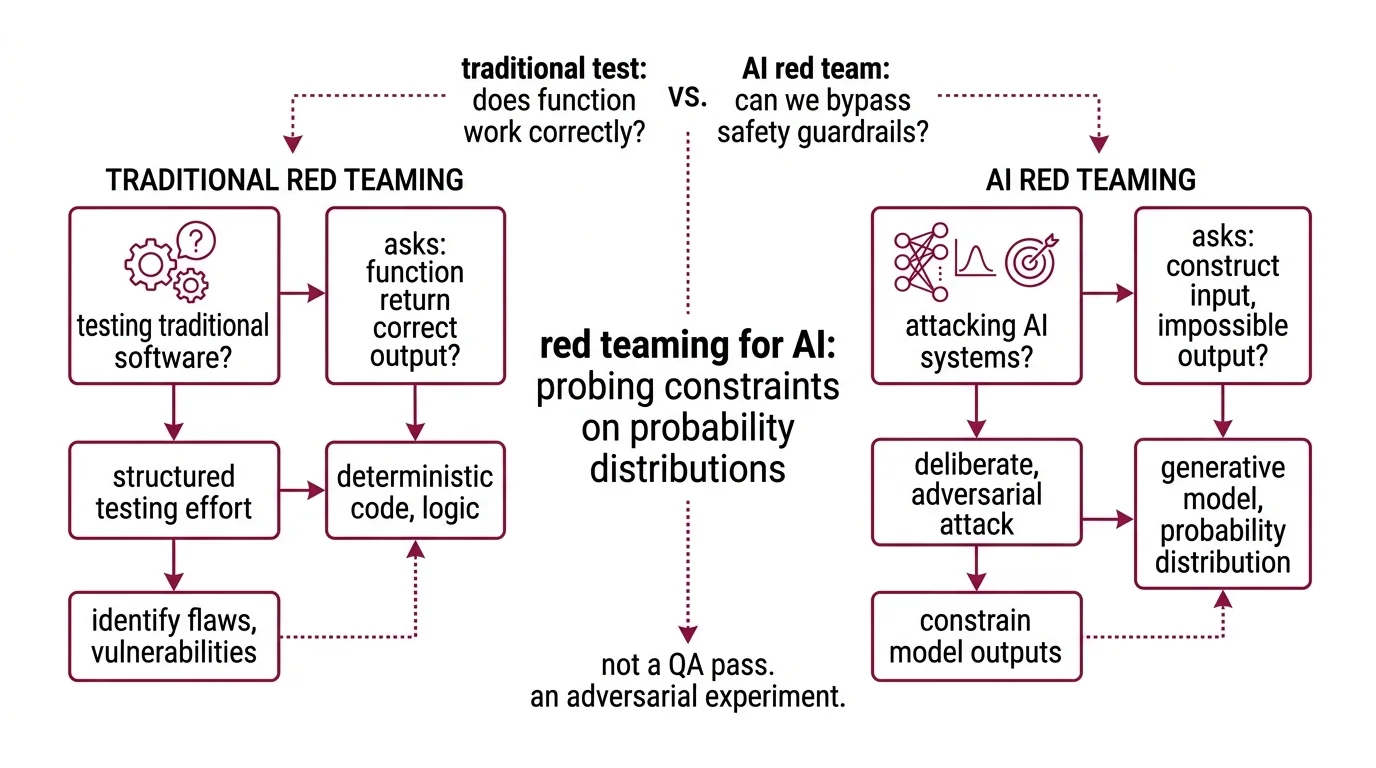
What is the difference between AI red teaming and traditional cybersecurity red teaming?
Traditional cybersecurity red teaming targets infrastructure: networks, endpoints, privilege escalation paths. The attacker looks for misconfigurations, unpatched services, weak credentials. The attack surface is finite and enumerable — every port, every service, every user account can in principle be cataloged.
AI red teaming targets something fundamentally different. The vulnerability isn’t in the infrastructure; it’s in the learned behavior of the model itself — the statistical patterns encoded across billions of parameters. The attack surface spans every possible input sequence the model might encounter, making it orders of magnitude larger than a traditional network perimeter.
The methodology diverges at every level:
| Dimension | Traditional Red Teaming | AI Red Teaming |
|---|---|---|
| Target | Infrastructure, code, configurations | Model behavior, probability distributions, learned patterns |
| Attack surface | Finite (ports, services, credentials) | Effectively unbounded (all possible input sequences) |
| Vulnerability type | Logic errors, misconfigurations | Behavioral failures, distributional gaps |
| Reproducibility | High — same exploit, same result | Variable — stochastic outputs mean the same attack may not work twice |
| Tooling | Penetration testing frameworks | Prompt fuzzing, embedding perturbation, automated adversarial generation |
The reproducibility gap is particularly revealing. A traditional exploit either works or it doesn’t. An AI Hallucination might surface in one run and vanish in the next, because sampling temperature introduces randomness into every generation pass. Red teams have to think statistically: not “does this attack work?” but “what is the probability this attack succeeds across a distribution of runs?”
Much of what currently passes for AI red teaming is closer to stress testing than to the full-scope adversarial simulation that traditional red teaming implies — a critique raised by Georgetown CSET before several recent framework updates (Georgetown CSET). The observation has aged, but the core tension persists: the field is still negotiating what “thorough” means for systems whose failure modes are probabilistic rather than deterministic. The OWASP LLM Top 10 now includes agentic risks via a separate Agentic Top 10 released in December 2025, and MITRE ATLAS expanded in 2026 to cover execution-layer exposure and autonomous workflow chaining — but the taxonomy race has no finish line.
What a Failure Taxonomy Predicts
If you know the taxonomy, you can predict where the next generation of failures will surface — and which defenses will prove insufficient.
If your system accepts user-supplied documents and feeds them into a language model’s context window, prompt injection is not a hypothetical risk. It is a structural certainty. The model will treat injected instructions as legitimate unless you build an explicit content separation layer — and even then, the separation is a probabilistic filter, not a guarantee.
If you fine-tuned for safety but didn’t test against encoding attacks — Base64, ROT13, multilingual paraphrasing — your refusal behavior has blind spots proportional to the encodings you didn’t cover. The model doesn’t “understand” that a request in Zulu is the same request it learned to refuse in English. It processes token sequences, and different sequences activate different probability paths.
If your retrieval-augmented generation pipeline doesn’t validate its data sources, an attacker who poisons a single indexed document can influence every response that retrieves from that corpus. The failure is silent: no error message, no crash, just subtly wrong outputs that erode trust over time.
The EU AI Act now requires general-purpose AI providers to document their adversarial testing practices, with additional high-risk system obligations expected in 2026. The specific code of practice remains unfinalized, but the regulatory direction is clear: red teaming is shifting from optional security hygiene to a compliance requirement.
Rule of thumb: If you can describe your model’s attack surface in a single paragraph, you haven’t thought about it long enough.
When it breaks: Red teaming finds the vulnerabilities it’s designed to look for, but the taxonomy of AI failures grows faster than any team can test. Novel attack categories — multi-step agentic exploits, cross-model prompt relay, tool-chaining in autonomous workflows — emerge faster than frameworks can catalog them. Even a thorough red team exercise provides a snapshot of risk, not a permanent seal of safety.
The Data Says
AI red teaming is the empirical discipline of discovering what your safety training missed — by trying to break the system before someone else does. The attack surface is probabilistic, effectively unbounded, and expanding into agentic territory. The frameworks and tooling exist. The harder question is whether your testing cadence keeps pace with the field’s own mutation rate.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors