RAG Evaluation Explained: Faithfulness, Relevance, Context Metrics
Table of Contents
ELI5
RAG evaluation measures a Retrieval-Augmented Generation pipeline as two separable subsystems — the retriever that fetches documents and the generator that writes the answer — using LLM-as-a-judge metrics like Faithfulness, Answer Relevancy, Context Precision, and Context Recall.
A team puts a Retrieval-Augmented Generation chatbot into production. The answers read beautifully. Confidence is high. Then a domain expert asks an uncomfortable question — are these numbers actually in the source documents, or did the model invent them? — and nobody on the team can produce a defensible answer. The pipeline returns text. It does not return evidence about whether that text is grounded, on-topic, or sourced from the right material at all. RAG evaluation is the discipline that turns those three opaque questions into numbers.
The hidden assumption that fluency equals correctness
Most teams audit their RAG pipeline by reading outputs and nodding. The assumption underneath that habit is that an answer which sounds coherent must be drawing on the retrieved context, and that the retrieved context must be the right context. Both halves of that belief can fail independently — and a coherent-sounding answer is exactly the kind of failure that survives review.
Not intuition. Decomposition.
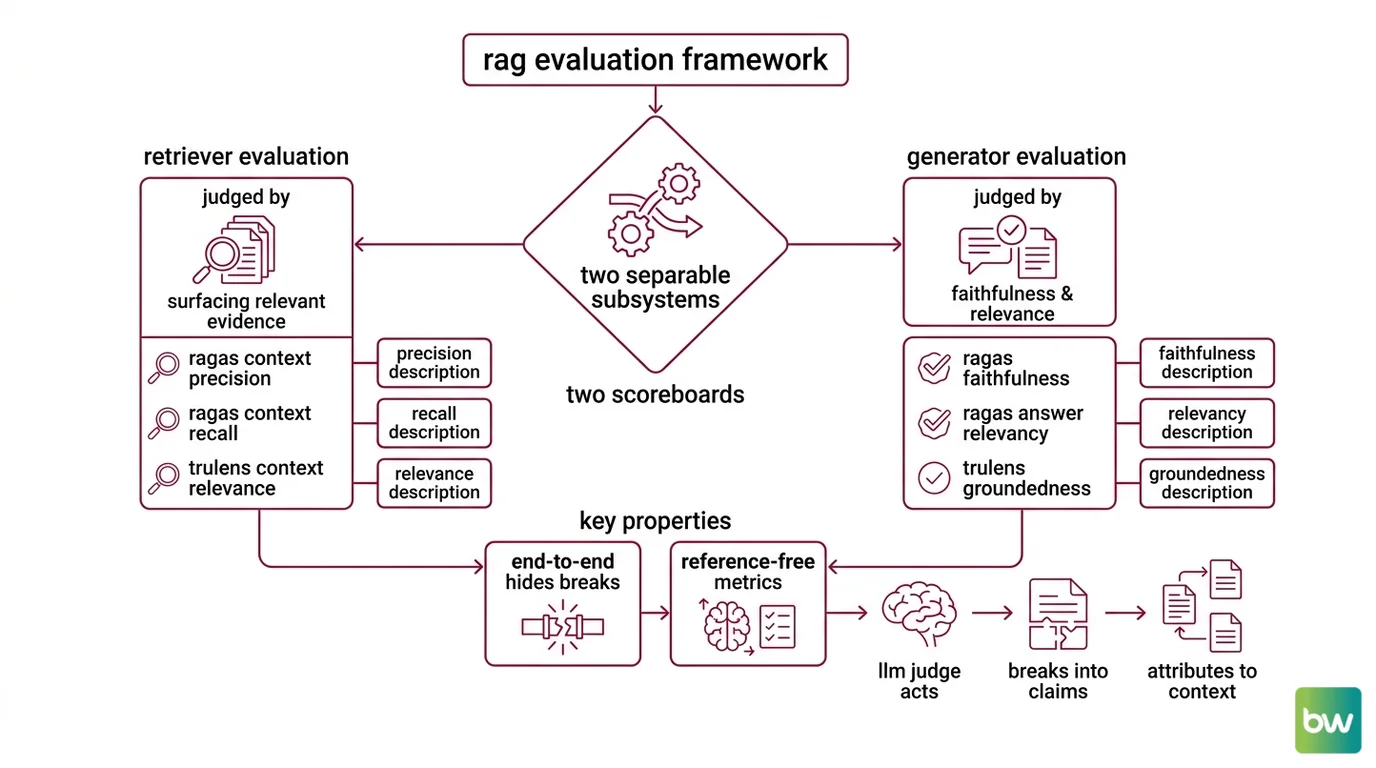
The Ragas paper (Es et al., 2023), which crystallised the modern vocabulary, makes the move explicit: stop scoring the pipeline as one black box, and start scoring it as two subsystems wired in series. The retriever is judged on what it pulls out of the index. The generator is judged on what it does with what the retriever handed it. A failure in one looks nothing like a failure in the other, and a single quality score that mixes them tells you neither where to look nor what to fix.
Two subsystems, two scoreboards
The first conceptual move in any serious RAG evaluation framework is to refuse to evaluate the system end-to-end as a single artifact. Retrieval and generation have different failure modes; they need different metrics. Once that split is in place, the metric vocabulary becomes legible.
What is RAG evaluation?
RAG evaluation is the practice of measuring a Retrieval-Augmented Generation pipeline as two separable subsystems — a retriever judged by how well it surfaces relevant evidence, and a generator judged by how faithfully and relevantly it answers using that evidence. The vocabulary is anchored in the Ragas paper (Es et al., 2024) and the parallel TruLens “RAG Triad” framework, both of which converged on the same insight: end-to-end accuracy hides where the pipeline is breaking.
The Ragas formulation, which has become the de facto reference set, uses four core metrics — Faithfulness, Answer Relevancy, Context Precision, and Context Recall (Ragas Docs). Two evaluate the retriever. Two evaluate the generator. A pipeline can score 0.95 on one pair and 0.42 on the other, and that asymmetry is the whole point — it tells you which subsystem to invest in.
What makes this measurable in practice is a property the Ragas paper introduced and called reference-free: most of these metrics can be computed from the question, the retrieved context, and the response alone, without a hand-labelled ground-truth answer (Ragas Docs). An LLM acts as the judge, breaking the response into atomic claims, attributing each one back to the context, and counting matches. The scoring is not free of subjectivity — but the subjectivity is moved out of the human reviewer’s head and into a procedure you can run on a thousand questions before lunch.
The TruLens project arrived at a near-identical decomposition under different names: Context Relevance for the retriever’s output, Groundedness for whether the answer is supported by that context, and Answer Relevance for whether the answer addresses the question (TruLens Docs). The mapping is close enough that teams routinely move between the two vocabularies — Context Relevance maps to Context Precision, Groundedness maps to Faithfulness, Answer Relevance maps to Answer Relevancy — but the names are not identical, and conflating them silently produces noisy comparisons.
The mechanics of measurement
Every one of these metrics resolves, eventually, to a fraction. Once you see that, the framework stops feeling like vibes-as-a-service and starts feeling like a small library of well-defined estimators.
How does RAG evaluation work across retrieval and generation stages?
The pipeline produces three artifacts for every query: the question, the retrieved context (a list of chunks), and the response. RAG evaluation runs different probes against different combinations of those three.
On the retrieval side, the question is what evidence got pulled out of the index. Context Precision asks: of the chunks the retriever returned in the top-K, were the relevant ones ranked early? The Ragas formula is Context Precision@K = Σ (Precision@k × vₖ) / total relevant items in top-K, where vₖ ∈ {0,1} flags whether chunk k is relevant (Ragas Docs). The shape of that formula matters — it punishes a retriever that buries the right answer at rank 9 even if it surfaces it at all.
Context Precision captures signal-to-noise at the top of the ranked list, not just whether relevant material is anywhere in the result set.
Context Recall asks the complementary question: did the retriever pull back enough of the right evidence to support the ideal answer? The DeepEval formulation has an LLM judge attribute each statement of the ground-truth answer back to the retrieved chunks, and scores the fraction that can be sourced (DeepEval Docs (Contextual Recall)). Context Recall is the one Ragas metric that genuinely needs a reference answer — recall is undefined without something to recall against. Treat any pipeline that claims to measure recall without ground truth with suspicion.
On the generation side, the probes pivot. Faithfulness asks: do the claims in the response actually appear in the retrieved context? The Ragas formula is (# claims supported by retrieved context) / (total # claims in response), scored between 0 and 1, with higher meaning more grounded (Ragas Docs (Faithfulness)). DeepEval implements the same idea — # truthful claims / total claims — and ships a default pass threshold of 0.5 with an optional strict mode that forces a binary 0/1 verdict (DeepEval Docs).
Answer Relevancy reverses the arrow. The Ragas implementation generates N synthetic questions (default 3) from the response and computes the mean cosine similarity between embeddings of those reverse-engineered questions and the original query (Ragas Docs (Response Relevancy)). The intuition is mechanical: if the response is on-topic, you should be able to reconstruct something close to the original question by reading only the answer. If the answer drifts, the reconstructed questions drift with it, and similarity collapses.
The score range here has a quiet wrinkle worth flagging — cosine similarity is theoretically bounded between −1 and 1, even though sensible RAG outputs almost always land between 0 and 1. A 0.3 here is not the same as a 0.3 on a clamped scale.
What are the core components of a RAG evaluation framework?
A working RAG evaluation framework, as it has standardised across Ragas, DeepEval, and TruLens, has five moving parts.
| Component | What it does | Examples |
|---|---|---|
| Metric library | Defines the scoring functions for retriever and generator | Ragas (4 metrics), DeepEval (5 RAG metrics), TruLens (3-metric Triad) |
| LLM-as-a-judge | The scoring engine that decomposes claims, judges relevance, attributes evidence | GPT-class models by default; calibrate against human labels |
| Eval dataset | A set of questions, optionally with ground-truth answers, used to drive the metrics | Reference-free for Faithfulness/Answer Relevancy/LLM-Context-Precision; reference-needed for Context Recall |
| Test runner | Executes the pipeline against the dataset, captures traces, computes metrics | DeepEval (“Pytest for LLMs”), Ragas evaluate(), LangSmith eval runs |
| Observability layer | Stores traces, metric scores, and embeddings over time so regressions are visible | LangSmith (native LangChain integration), Arize Phoenix (OpenTelemetry-native, framework-agnostic) |
The metric library and the LLM judge together produce a number; the dataset and runner make those numbers comparable across runs; the observability layer makes them comparable across time. A team that has the first two but skips the second two is doing one-shot evaluation, not continuous evaluation, and a RAG pipeline that drifts silently after a corpus update is exactly the kind of system continuous evaluation exists to catch.
Phoenix’s distinguishing move at the observability layer is to project the embedding space of retrieved chunks into 2D or 3D so that retrieval drift becomes literally visible — a cluster that used to overlap with the query embeddings starts pulling away. Numbers tell you something is wrong; geometry sometimes tells you what.
What the scores predict about your failures
Once the four metrics are in place, the cross-table of high and low scores becomes a diagnostic chart. The mechanism is the math; the value is the failure mode each pattern points at.
- If Faithfulness is low but Answer Relevancy is high, the model is fluently fabricating — generating on-topic statements the retrieved context does not support. Tighten generation: lower temperature, add explicit instructions to refuse when context is insufficient.
- If Context Precision is high but Context Recall is low, the retriever is conservative — what it returns is on-topic, but it is missing chunks the answer needs. Increase top-K, revisit chunking strategy, or upgrade the embedding model.
- If Context Recall is high but Context Precision is low, the retriever is dragging in noise. The generator either gets confused or wastes context window. Add a reranker or tighten the relevance threshold.
- If Faithfulness and Answer Relevancy are both high but users still complain, suspect Context Recall — the retrieved evidence may be self-consistent but incomplete, and the model is faithfully answering from a partial picture.
A common practical heuristic, surfaced in the Redis on Ragas guide, is that scores at or above 0.8 on the four core metrics typically signal production-ready quality, though the exact threshold drifts by domain (Redis on Ragas).
Rule of thumb: Always read the four scores as a vector, not as an average. Averaging Faithfulness with Context Recall throws away the diagnostic signal that justified the framework in the first place.
When it breaks: Faithfulness measures contradiction between the response and the retrieved context — not against the world. If the retrieved context itself is wrong, a “faithful” answer can still be factually false; the metric will quietly score the pipeline well while the user gets a confident, well-cited lie.
Compatibility notes:
- Ragas v0.1.x metric APIs: Pre-v0.2 instantiation patterns were restructured around v0.2 (Ragas Docs). Legacy code still runs in v0.4.x, but newer tutorials assume the class-based API. Action: prefer the v0.2+ class-based instantiation when starting a new project.
- LangChain legacy chains:
LLMChainand other legacy chains used in older RAG eval tutorials moved tolangchain-classicin LangChain 1.0 (released Oct/Nov 2025). LangSmith eval examples have been rewritten aroundcreate_agentand LCEL. Action: avoid copy-pastingLLMChain-based eval scripts from pre-2026 blog posts.
The judge needs its own audit
There is a deeper consequence baked into the framework: the LLM acting as a judge is itself a model with biases, and the metric is only as reliable as the judge’s calibration. Snowflake’s own benchmarking of the RAG Triad shows that judge prompts often need calibration against human labels before their agreement with human raters reaches usable levels (Snowflake Engineering Blog). Treat any RAG metric score as a measurement, not as a truth — a number with an error bar that depends on which model you used to compute it and how its prompt was tuned.
This is not a flaw of the framework. It is the unavoidable cost of automating quality judgement. The reason RAG evaluation works at all — that an LLM can tear a paragraph into claims and check them — is the same reason its scores require their own validation pass.
The Data Says
RAG evaluation works because retrieval and generation fail in different ways and demand different probes. The Ragas four — Faithfulness, Answer Relevancy, Context Precision, Context Recall — read together as a diagnostic vector that points at the broken subsystem. Read them as an average and you reintroduce the black box you were trying to open.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors