How HyDE, Multi-Query, and Step-Back Improve RAG Retrieval Recall
ELI5
Query transformation rewrites the user’s question before retrieval — turning it into something that looks like the answer, several alternative phrasings, or a broader concept — so the index returns documents the original prompt would have missed.
A user types: “How does softmax handle negative values?” The document with the answer says: “The softmax function exponentiates each input element, ensuring all outputs are positive regardless of input sign, before normalizing them across the output distribution.” Both sentences agree. They contain the same information. Embed them, compute cosine similarity, and they often don’t sit close enough for retrieval to surface the correct passage.
The blame usually lands on the embedding model. The blame is misplaced.
The Question-Answer Geometry Gap
Dense retrieval rests on a quietly unverified assumption — that a query and the document containing its answer occupy the same neighborhood in the embedding space. They don’t, reliably. Questions are short, interrogative, and lexically sparse. The passages they retrieve from are long, declarative, and written in a different register. The encoder learned its geometry from passages, not from question-passage pairs, unless it was trained specifically for that asymmetry.
Not a flaw in the model. A mismatch in distribution.
This is the structural problem that Retrieval Augmented Generation pipelines inherit. You can swap encoders, tune chunk sizes, reweight similarity scores — and recall still leaks at the seam between asking and answering. Pre-retrieval query transformation is one of the standard enhancement axes alongside indexing and post-retrieval reranking, per the RAG Survey (Gao et al.).
What is query transformation in RAG?
Query transformation is any technique that rewrites the user’s input before it reaches the retriever. The rewrite can be substitutive (replace the query entirely) or additive (retrieve over the original and the variants and merge). The shared premise is that the literal user query is rarely the optimal probe for the corpus you are searching.
There are three rewrite strategies that the field has converged on, each operating on a different axis of the geometry gap:
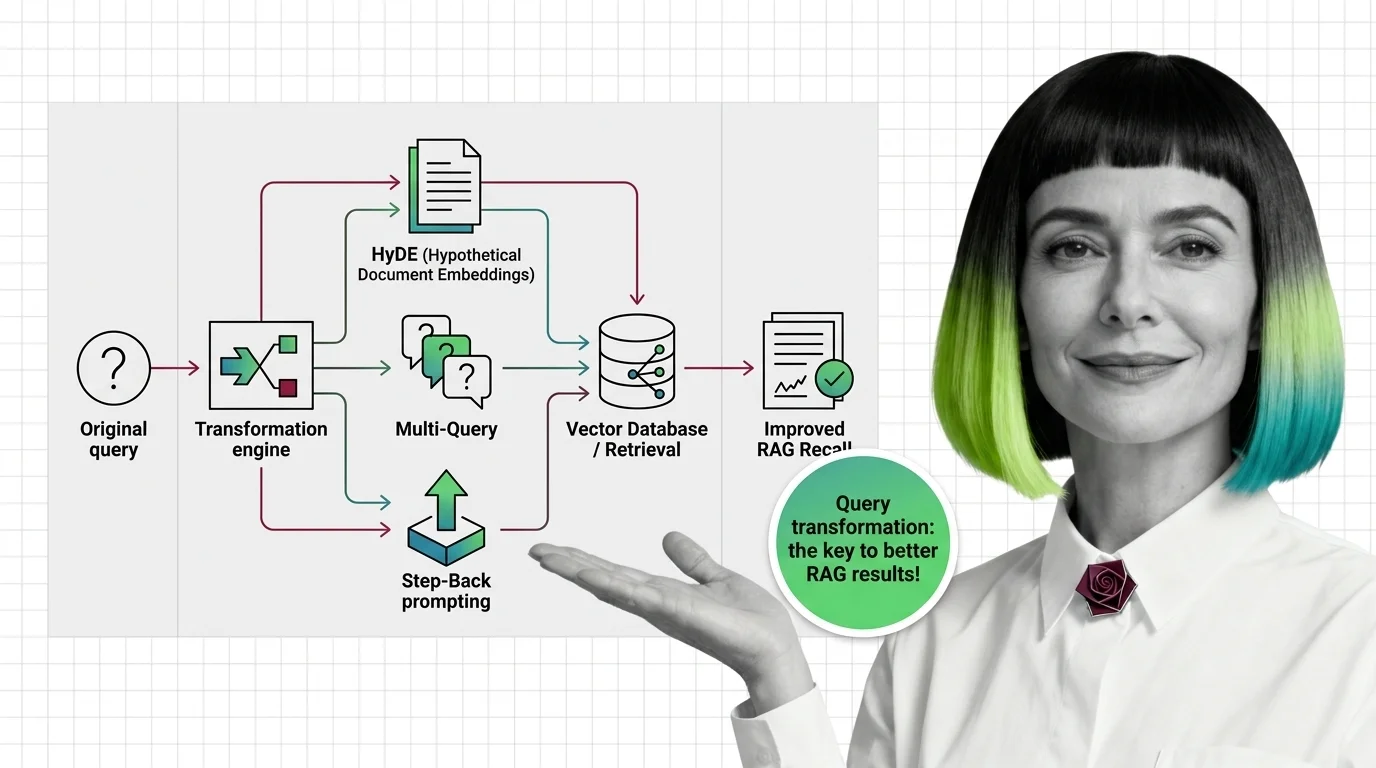
- Synthesize an answer-shaped probe — generate a hypothetical answer first, embed that, retrieve real documents close to the synthetic one. This is HyDE.
- Broaden the query surface — generate several phrasings of the same question, retrieve per phrasing, take the union. This is Multi-Query.
- Zoom out one level — derive a more general concept from the specific question and retrieve on the abstraction. This is Step-Back Prompting.
A fourth, RAG-Fusion, is essentially Multi-Query with a smarter merge: ranked-list fusion via Reciprocal Rank Fusion instead of a simple union (Rackauckas, 2024).
How does query transformation work to improve retrieval recall?
The mechanism is the same in every case: an LLM call sits in front of the retriever and produces text whose embedding is closer to the relevant documents than the original query’s embedding would have been. The geometry of the probe changes; the index does not.
Think of the embedding space as a city. The user query lands at an intersection in the question district. The answers live across the river in the document district. A single direct similarity search throws a short rope across the gap and grabs whatever it can reach. Query transformation either moves the search origin into the document district before throwing the rope (HyDE), throws several ropes from slightly different intersections (Multi-Query), or throws the rope from a higher floor where the view covers more ground (Step-Back).
None of these techniques teach the retriever anything new. They reshape the probe so that nearest-neighbor search points at a different — and usually more useful — neighborhood.
Three Families of Transformation
Each family addresses a different failure mode of literal similarity search. Understanding which failure mode you have determines which technique helps. The papers introducing them came from different research lineages — HyDE from zero-shot retrieval, Step-Back from reasoning, Multi-Query from production RAG tooling — and that origin shapes their strengths.
What are the main types of query transformation techniques?
HyDE — Hypothetical Document Embeddings
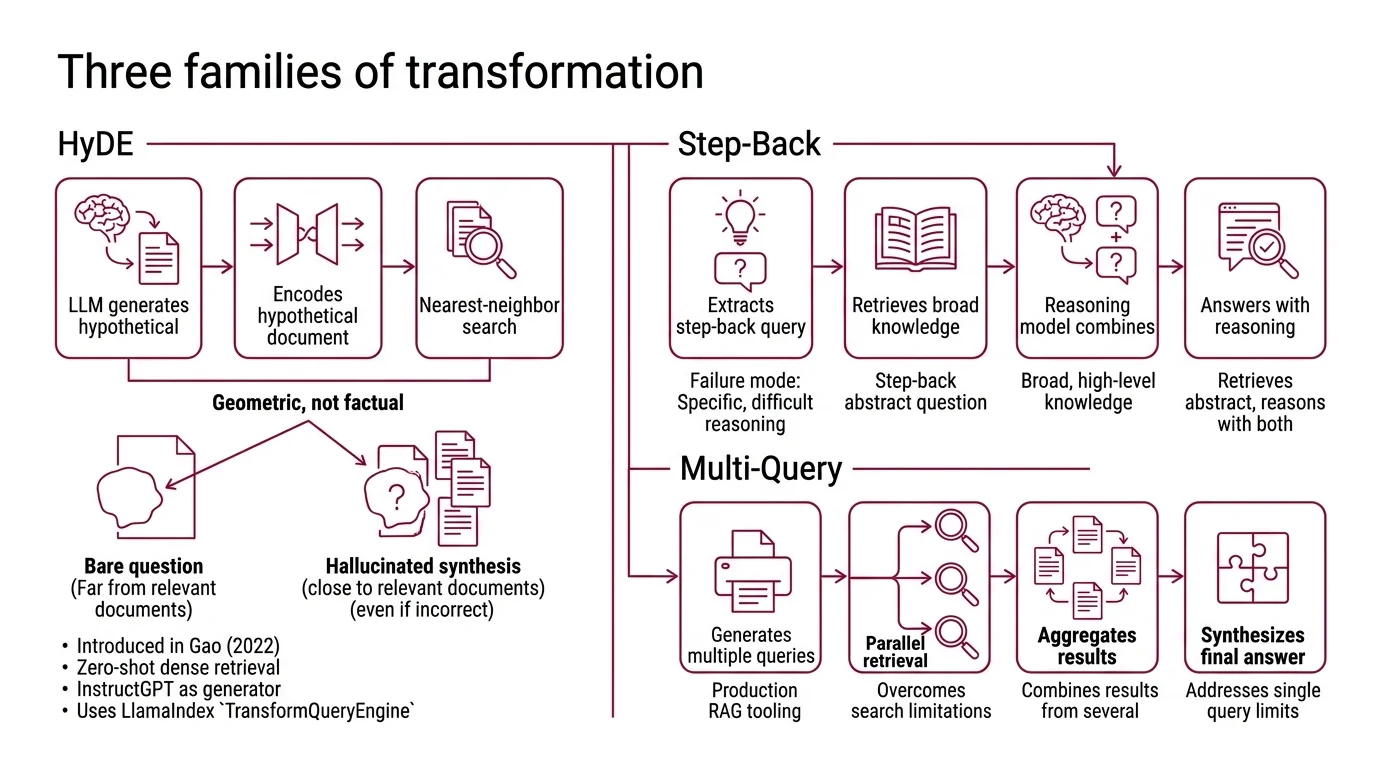
Introduced in Precise Zero-Shot Dense Retrieval without Relevance Labels by Gao et al. (2022), HyDE runs in two stages. An instruction-tuned LLM generates a hypothetical document that would answer the user’s query. An unsupervised contrastive encoder — Contriever, in the original paper — embeds the hypothetical document. Nearest-neighbor search returns real documents close to the synthetic one. The original work used InstructGPT as the generator, but the pattern is generator-model-agnostic; any current instruction-tuned LLM works as a drop-in replacement. LlamaIndex exposes this as HyDEQueryTransform wrapped in TransformQueryEngine, with an include_original=True option that retrieves on both the hypothetical document and the raw query and merges (LlamaIndex Docs).
The mechanism is geometric, not factual. The hypothetical document does not need to be correct. It needs to be answer-shaped — written in the register of the corpus. Even a hallucinated synthesis lands closer to real documents than a bare question does, because it shares the lexical and syntactic distribution of passages.
A subtlety the original paper makes explicit but most explainer posts elide: HyDE was published before “RAG” was the dominant framing for retrieval-augmented systems. Its contribution was zero-shot dense retrieval — getting useful retrieval without labeled query-document pairs. Calling it a RAG technique is retroactive. The community adopted it; the paper did not aim there.
Multi-Query Generation
LangChain’s MultiQueryRetriever uses an LLM to generate multiple alternative phrasings of the user query, retrieves documents per query, and returns the unique union of results (LangChain Docs). The default prompt template asks for three different versions of the user question, though that number is a prompt-template default rather than a researched optimum — production systems often use four or five.
Where HyDE moves the probe toward the answer’s geometry, Multi-Query spreads the probe across multiple plausible phrasings of the same question. The premise is that single-query distance-based similarity search is brittle: subtle wording choices change which neighborhoods you reach. Three or five different phrasings cast a wider net, and documents that were one synonym away from being retrieved get pulled in.
Step-Back Prompting
Introduced in Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models by Zheng et al. (2023), Step-Back operates in two phases. An abstraction step asks the LLM to derive a higher-level concept or first-principle question from the specific query. A reasoning step then answers the original query grounded in retrieved facts about the abstracted concept. On PaLM-2L, the original authors reported gains of +27% on TimeQA, +7% on MuSiQue, +7% on MMLU Physics, and +11% on MMLU Chemistry (Zheng et al., 2023) — figures that are PaLM-2L-specific and should not be generalized to “Step-Back improves retrieval by 27%.”
There is a second caveat worth naming: Step-Back was originally formulated as a reasoning technique, not a retrieval one. The application to RAG — retrieving on the abstracted question rather than the literal one — is a community adaptation popularized by the LangChain and LlamaIndex ecosystems, not the original paper’s contribution.
RAG-Fusion
Rackauckas (2024) generates multiple query variants, retrieves per query, and fuses the ranked lists with Reciprocal Rank Fusion. Documents that appear in multiple ranked lists float to the top. It is best understood as Multi-Query plus a smarter merge.
What the Geometry Predicts
If the mechanism is real — that transformations reshape the probe rather than the index — then which transformation helps depends on which axis the gap lies along. A few if/then predictions follow directly:
- If the user’s wording differs lexically from the corpus (laypeople asking domain-specific questions, customers using product slang the docs don’t), Multi-Query helps most. The variants paper over the vocabulary mismatch.
- If the corpus is dense and answer-shaped and the queries are short and interrogative (technical documentation, scientific papers, FAQs without question text), HyDE helps most. The synthesized document lands in the corpus’s register.
- If the question is too narrow to retrieve anything useful (“Did Albert Einstein attend school in 1905?”), Step-Back helps most. Retrieving on “Albert Einstein’s education history” returns a useful passage; retrieving on the literal question returns nothing.
- If the topic is unfamiliar to the generator LLM, HyDE hurts. The hypothetical document hallucinates and pulls retrieval toward irrelevant neighborhoods (Gao et al., 2022).
These behaviors compose with rather than replace post-retrieval steps. Reranking a larger candidate pool — and Multi-Query gives you a larger candidate pool by construction. Hybrid Search (sparse plus dense) addresses lexical mismatch through a different mechanism, and stacking it with Multi-Query is sometimes redundant. Agentic RAG systems often perform their own query rewriting as part of tool-use planning, in which case adding HyDE on top can double-transform the query into incoherence.
Rule of thumb: Pick the transformation whose mechanism matches your geometry gap — register mismatch → HyDE; vocabulary mismatch → Multi-Query; specificity mismatch → Step-Back. Stacking transformations rarely helps and often hurts.
When it breaks: Every transformation adds a generator-LLM call before retrieval, which inflates latency by roughly 1-2 seconds per query (Adaptive HyDE, 2025). For interactive applications, that single transformation step often costs more than the retriever and the answering LLM combined. HyDE specifically degrades on conceptual queries that need clarification rather than synthesizable answers — the Adaptive HyDE study found that on roughly a quarter of developer-support cases, plain zero-shot retrieval beat HyDE outright.
Compatibility notes:
- LangChain v1 import path:
MultiQueryRetrievermoved out oflangchaincore; import fromlangchain_classic.retrievers.multi_query(LangChain v1 Migration).- Retriever API:
get_relevant_documents()is deprecated since langchain-core 0.1.46 — use.invoke()(Runnable interface) on new code.
The Data Says
Query transformation does not improve embeddings; it changes what you embed. HyDE, Multi-Query, and Step-Back each address a different geometric mismatch between question and answer, and the mechanism that makes each one work is also what predicts where it fails. No peer-reviewed benchmark directly compares the three on the same corpus, so claims of one being categorically “better” should be hedged. The right transformation is the one whose mechanism matches your specific gap.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors