What Is Quantization and How FP32-to-INT4 Compression Makes LLMs Run on Consumer Hardware
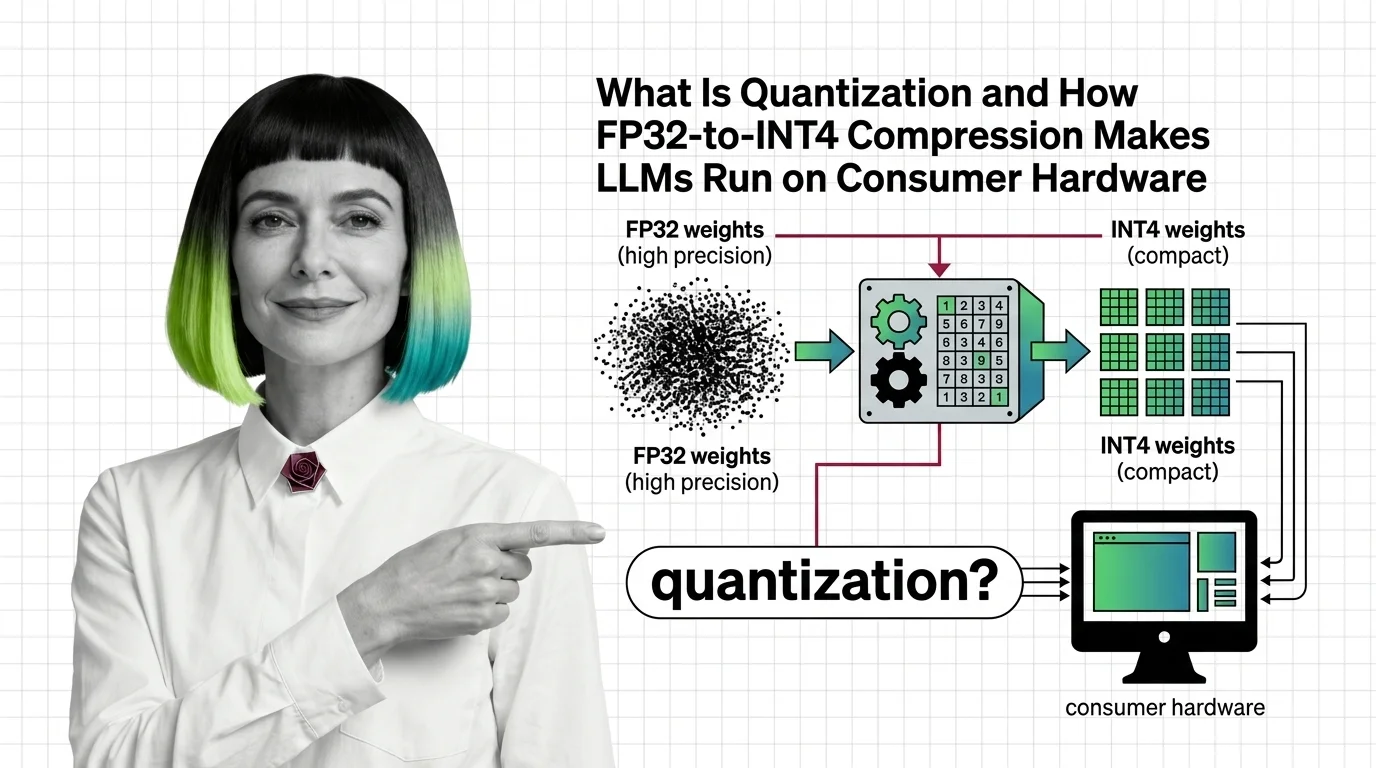
Table of Contents
ELI5
Quantization shrinks each number in a neural network from high-precision (32-bit) to low-precision (4-bit or 8-bit), slashing memory by up to 8x so large models fit on smaller hardware.
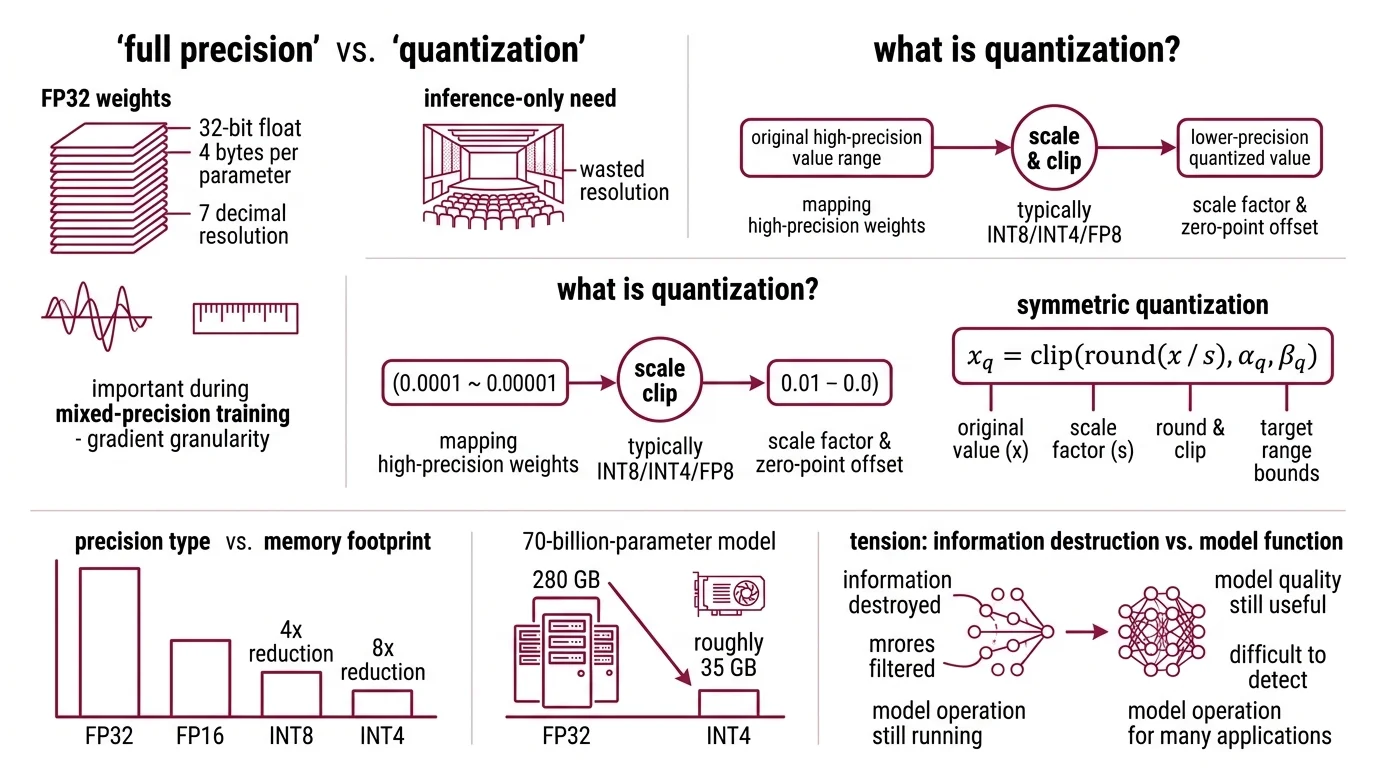
A 70-billion-parameter model stored in FP32 occupies roughly 280 GB of memory. That is more than most data-center nodes carry in a single GPU. Yet people run that same model on a gaming laptop with 24 GB of VRAM — and the outputs are coherent. The gap between those two numbers is not a miracle of hardware. It is a deliberate act of mathematical forgetting, and the fact that it works at all tells us something unsettling about how much precision neural networks actually need.
The Geometry of Throwing Numbers Away
Every parameter in a neural network is a number. In full precision — FP32, or 32-bit floating point — each one occupies four bytes and can represent values across a staggering dynamic range: roughly ±3.4 × 10³⁸, with about seven decimal digits of resolution. That resolution is essential during Mixed Precision Training, where gradients need fine granularity to converge. But during Inference — when the model is generating tokens, not learning — most of that resolution sits idle, like a concert hall built for an audience that never arrives.
Quantization exploits that idle resolution.
What is quantization in large language models?
Quantization is the process of mapping high-precision floating-point weights to lower-precision representations — typically INT8, INT4, or
Fp8 — using a scale factor and an optional zero-point offset. The core formula for symmetric quantization is deceptively compact: x_q = clip(round(x / s), α_q, β_q), where s is the scale factor that maps the original value range into the target integer range (NVIDIA Blog).
The idea is borrowed. Signal processing has used quantization for decades — it is how analog audio becomes a digital file. What changed is the target: instead of compressing sound waves, we are compressing the weight matrices of transformer models with billions of parameters, and the tolerances are different in ways that matter.
Moving from FP32 to FP16 halves memory. FP32 to INT8 cuts it by 4x. And FP32 to INT4 delivers an 8x reduction — that 70-billion-parameter model drops from 280 GB to roughly 35 GB (LocalLLM.in). The difference between needing a cluster and needing a single consumer GPU.
But here is the tension that makes quantization genuinely interesting: you are destroying information, and the model still works. Not perfectly. Not for every task. But well enough that the quality loss is, for many applications, difficult to detect without a benchmark suite.
The question is why.
Where Precision Actually Hides
The naive assumption is that every weight matters equally — that reducing the precision of any individual parameter degrades the output proportionally. If that were true, quantization would be useless. The accumulated rounding errors across billions of parameters would produce noise, not language.
That assumption is wrong. And the reason it is wrong reveals something fundamental about how neural networks store knowledge.
How does quantization reduce model precision from FP32 to INT4 without destroying accuracy?
The weight distributions in a trained transformer are not uniform. They cluster. Most weights sit near zero, forming a tight bell curve, with long tails stretching in both directions. A small fraction of weights carry disproportionate influence on the output — and those weights tend to have larger magnitudes or sit in channels that see high activation values during forward passes.
Post Training Quantization takes a trained model and compresses it after the fact, without retraining. The simplest version — round-to-nearest with a fixed scale factor — works surprisingly well for 8-bit precision. For 4-bit, the rounding errors accumulate enough to matter.
That is where calibration enters. By passing a small set of representative inputs (roughly 200 samples) through the model and observing which weights produce the largest errors when rounded, calibration methods identify where precision matters most and where it can be safely discarded. This requires no gradient updates — only observation and arithmetic (PyTorch Blog).
The alternative, quantization-aware training (QAT), inserts simulated quantization noise into the training loop itself, letting the model learn to compensate for reduced precision during optimization. QAT can recover up to 96% of the accuracy gap that basic PTQ leaves behind (PyTorch Blog) — but it requires access to training infrastructure, training data, and compute that most practitioners do not have.
For most users running open-weight models, the practical path is PTQ with a calibration method that knows where to cut. The question becomes: what does “knowing where to cut” actually mean?
The Asymmetry That Calibration Exploits
Not all compression strategies are equal. The difference between a quantized model that produces fluent text and one that hallucinates mid-sentence often comes down to a single decision: how the calibration method identifies which weights to protect and which to round aggressively.
Two methods dominate the current ecosystem, and they solve the same problem from opposite directions.
How do calibration methods like GPTQ and AWQ decide which weights to compress?
GPTQ (Frantar et al., 2022; presented at ICLR 2023) treats quantization as a layer-wise optimization problem. For each layer, it uses approximate second-order information — the Hessian matrix, which captures how sensitive the loss function is to changes in each weight — to determine which parameters can tolerate rounding and which cannot. Weights sitting in steep regions of the loss surface get quantized carefully; weights in flat regions get rounded aggressively, because a small perturbation there barely moves the output. The result: a 175-billion-parameter model quantized to 3-4 bits in approximately four GPU hours, with negligible accuracy loss. On an A100, GPTQ-quantized models run roughly 3.25x faster than their FP16 counterparts (arXiv, Frantar et al.).
AWQ (Lin et al., 2023; MLSys 2024 Best Paper Award) approaches the problem from the activation side instead of the weight side. Rather than asking which weights are sensitive to rounding, AWQ asks which weight channels carry the most signal when real data flows through the model. It discovers that protecting just 1% of salient weight channels — identified by activation magnitude, not weight magnitude — dramatically reduces quantization error (arXiv, Lin et al.). Instead of keeping those channels at higher precision (which would complicate hardware execution paths), AWQ applies per-channel scaling that amplifies salient weights before quantization and compensates afterward. The result is a 70-billion-parameter Llama-2 model running on mobile hardware, achieving over 3x speedup compared to FP16.
The distinction matters for intuition: GPTQ looks at the loss landscape and finds the flat spots. AWQ looks at the data flow and finds the loud channels. Both reach similar destinations through different geometry — and in practice, the choice between them often depends on your hardware target and serving framework more than on raw accuracy.
What the Compression Tells You About Your Hardware
The tooling ecosystem around quantization has split along a fault line that maps directly to two different deployment realities: server-side throughput and local-first privacy.
For server-side inference, FP8 is becoming the default precision on NVIDIA Ada Lovelace and Hopper GPUs (compute capability 8.9 or higher), delivering up to 2x latency reduction compared to FP16 with minimal accuracy degradation (vLLM Docs). Serving engines like vLLM support FP8, AWQ, GPTQ, and Bitsandbytes quantization natively, often combined with Continuous Batching for throughput optimization. One caveat: FP8 on consumer GPUs (the RTX 40-series) operates as weight-only W8A16 — weights stored in 8-bit, computation in 16-bit. Full W8A8 compute requires data-center hardware.
For local inference, the GGUF format and Llama Cpp dominate. GGUF is a binary format storing tensors alongside metadata, supporting quantization levels from 1.5-bit to 8-bit. The recommended minimum for coding and reasoning models is Q4_K_M or Q5_K_M — below 4-bit, quality drops off a cliff. On the Python side, bitsandbytes (version 0.49.2 as of February 2026) provides 8-bit quantization via LLM.int8() and 4-bit via QLoRA’s NF4 data type — a format optimized for normally-distributed weights, which transformer parameters tend to be.
The interaction between quantization and Temperature And Sampling settings is worth noting: higher temperature amplifies the noise that rounding introduces into the probability distribution, making quantized models less predictable at creative sampling settings than their full-precision counterparts.
Rule of thumb: If you are running a model locally and need to choose a quantization level, start at Q5_K_M and decrease only if VRAM forces it. Each step down trades quality for memory — and below Q4, the trade becomes steep.
When it breaks: Quantization degrades gracefully until it doesn’t. Tasks requiring precise numerical reasoning, long-chain logical deduction, or code generation with exact syntax are the first to suffer at aggressive compression levels. A model that writes fluent prose at Q4 may produce subtly wrong arithmetic at the same precision — and the errors will not announce themselves.
Compatibility note:
- AutoGPTQ: Development has stopped; replaced by GPTQModel, which is integrated into HuggingFace Transformers. Migrate existing AutoGPTQ workflows to GPTQModel.
The Data Says
Quantization is not an approximation you tolerate. It is a lens that reveals which parts of a neural network actually carry signal and which parts were always noise dressed up as precision. The 8x memory reduction from FP32 to INT4 is not the interesting finding — the interesting finding is that discarding most of each number’s bit-level resolution barely changes the output. That asymmetry tells us something about where knowledge lives inside these models, and we are still learning what it means.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors