Prompt Engineering for Image Generation: How Diffusion Models Read Text
ELI5
Prompt engineering for image generation is the practice of designing text inputs that steer a diffusion model’s denoising trajectory toward a specific visual output — without retraining the weights. You are shaping a probability distribution, not painting pixels.
A myth refuses to die: that image prompts are spells. Add the right tags — ((masterpiece)), 8k, award-winning, trending on artstation — and the model will produce something beautiful. The longer the incantation, the better the result. Most “prompt engineering” tutorials for image models still teach this as if it were 2022.
The actual mechanism is less mystical, and far more interesting.
How a Sentence Becomes Geometry
Before pixels exist, a prompt becomes vectors. A text encoder reads your sentence and produces a high-dimensional embedding — a numeric description of meaning. The image model never sees your words. It sees coordinates in a latent space.
What is prompt engineering for image generation?
Prompt engineering for image generation is the systematic practice of structuring text inputs so that the conditioning signal sent to a Diffusion Models pipeline biases its sampling trajectory toward a specific visual outcome. You are not describing an image. You are constraining a probability distribution.
The discipline now has a vocabulary. The Prompt Report — a systematic survey of prompting research — catalogs 33 prompting terms, 58 LLM techniques, and 40 techniques specific to non-text modalities including text-to-image (arXiv: The Prompt Report). The taxonomy matters because the field is now formal enough to need one.
It is not poetry. It is conditioning a stochastic process.
How do diffusion models turn text prompts into images?
A diffusion model starts from pure noise — a random tensor with the dimensions of an image — and denoises it across a sequence of timesteps until structure emerges. At every step, the model predicts the noise to subtract. Your prompt influences that prediction.
The link between text and pixel is a layer called cross-attention. It allows each spatial region of the latent image to “look at” relevant tokens of the prompt. Cross-attention layers are essential for controlling the relation between the spatial layout of the image and each word in the prompt; injecting modified cross-attention maps lets text edits map to specific pixel regions (arXiv: Hertz et al. 2022, Prompt-to-Prompt). The same machinery powers modern AI Image Editing pipelines that let you change one object in a scene without regenerating the rest.
Different models use different encoders, and the choice changes everything about how prompts behave. Stable Diffusion 3 and 3.5 run three encoders in parallel — CLIP-L, CLIP-G, and T5-XXL with roughly 4.7 billion parameters (Hugging Face Diffusers). FLUX.1 pairs CLIP with a larger T5-XXL of roughly 11 billion parameters and reads prompts as natural-language sentences rather than keyword bags (Black Forest Labs: FLUX.2 Prompt Guide). FLUX.2, released in November 2025, replaces both encoders entirely with Mistral Small 3.2 — a vision-language model of roughly 24 billion parameters (Apatero: Flux 2 Prompting Guide).
CLIP encoders treat prompts more like tagged keyword bags. T5 and Mistral parse them as sentences with grammar and clause structure. Same final image type. Completely different prompting style.
The Steering Mechanism Behind Every Generation
The encoder produces an embedding. But how does that embedding actually push the denoiser toward your prompt instead of toward random noise? That is the job of Classifier-Free Guidance — and the reason every image-generation parameter you have ever tuned exists.
What are the core components of an image generation prompt?
Open any 2026 prompting guide and you will find a near-canonical skeleton:
Subject + Action + Environment + Composition + Lighting + Style + Camera + Quality + Negatives (letsenhance.io: AI Prompt Guide 2026).
This is not prescriptive doctrine. It is a checklist that maps to the things diffusion pipelines actually attend to. Subject and action drive the cross-attention maps that decide what is in the image. Environment and composition shape the latent’s spatial layout. Lighting, style, and camera condition the model’s stylistic priors. Negatives — a Stable Diffusion-family convention, not a universal one — push the denoiser away from features you don’t want.
Inside Classifier-Free Guidance, every denoising step makes two predictions: a conditional one (what the model would generate given your prompt) and an unconditional one (what it would generate without text guidance at all). The final velocity that moves the latent toward the next step is computed as unconditional + cfg_scale × (conditional − unconditional) (SoftwareMill: Classifier-Free Guidance). The cfg_scale parameter is the dial. Typical values land between 5 and 9, with 7.5 a common default. Higher values pull harder toward your prompt — and produce oversaturated, brittle artifacts when pushed too far.
A negative prompt rewires this equation. Instead of using a null embedding for the unconditional prediction, the pipeline substitutes embeddings of “what you don’t want.” The denoiser is now repelled from those features, not just attracted to the positive ones. The effect is delayed across timesteps — negative tokens cannot influence a region until the corresponding positive content has started to emerge (arXiv: Negative Prompts Timing 2406.02965). You cannot suppress a feature that hasn’t started forming yet.
For CLIP-based pipelines, weighted-token syntax compounds this. AUTOMATIC1111 uses (token:1.3) to multiply attention by a factor of 1.3 and [token] to decrease it; nesting (((token))) works up to four levels, with a practical range of about 0.5 to 1.6 (getimg.ai: Prompt Weights Guide). Outside that range, the conditioning becomes adversarial — the model fights itself.
Midjourney works differently. Its v7 style-reference system uses --sref <code> to apply a saved style and --sw 0–1000 to control strength, with a default of 100; the current style-reference version --sv 6 has been live since June 2025 (Midjourney Docs: Style Reference). No bracket weights. No negative-prompt field. Different model, different grammar.
What do you need to know before writing image generation prompts?
Three things, in this order.
First, identify the model family. SD 3.x and SDXL respond to weighted keywords and negative prompts. FLUX prefers full natural-language sentences and ignores most CLIP-era syntax. GPT Image 2 wants paragraphs and conversational refinements (OpenAI Cookbook: GPT Image Prompting Guide). Midjourney v7 wants short high-signal phrases plus parameters. Using SD syntax on FLUX is like writing assembly for a high-level interpreter — the model will try, but you are working against the encoder.
Second, know your token budget. FLUX.1 [dev] caps at 512 tokens; FLUX.1 [schnell] caps at 256 (Apatero: Flux 2 Prompting Guide). Beyond that, the encoder truncates silently. A long lyrical prompt on a 256-token model loses the second half of your description without warning.
Third, decide whether prompting is the right tool at all. If you need a consistent character across many images, no prompt will reliably do it — you want a LoRA for Image Generation. If you need to clean a final output, prompts cannot replace Image Upscaling or AI Background Removal as discrete post-process steps. Prompt engineering is one layer of the pipeline. It is not the whole pipeline.
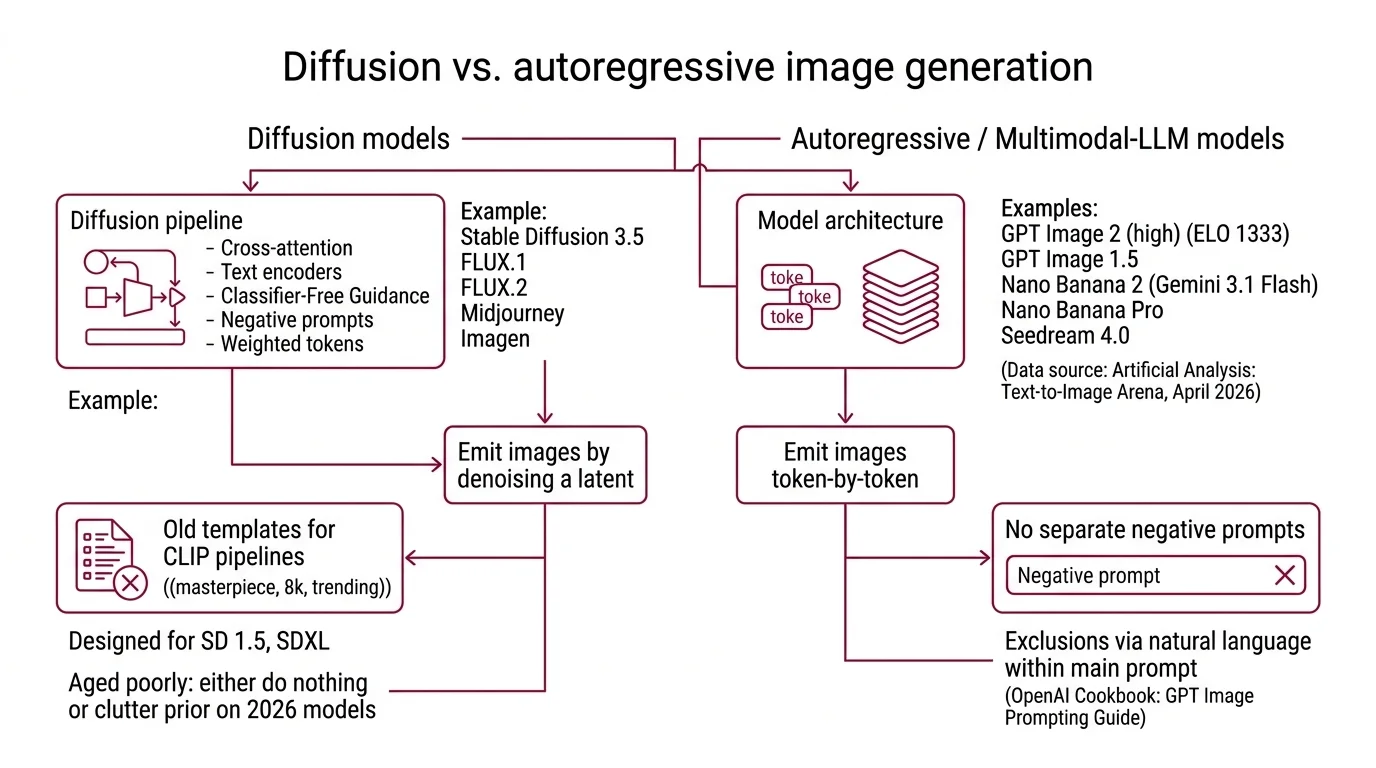
A Note on the Diffusion vs. Autoregressive Divide
Most of what we just described — cross-attention to text encoders, Classifier-Free Guidance, negative prompts, weighted tokens — is diffusion-pipeline machinery. It applies to Stable Diffusion 3.5, FLUX.1 and FLUX.2, Midjourney, and Imagen. It does not fully apply to the current top of the leaderboard.
As of April 2026, the Artificial Analysis Text-to-Image Arena is led by GPT Image 2 (high) at ELO 1333, followed by GPT Image 1.5, Nano Banana 2 (Gemini 3.1 Flash), Nano Banana Pro, and Seedream 4.0 (Artificial Analysis: Text-to-Image Arena, fetched April 2026). The first four are autoregressive or multimodal-LLM-based, not pure diffusion. They emit images token-by-token rather than denoising a latent. They do not expose a separate negative-prompt field — exclusions must be phrased in natural language inside the same prompt (OpenAI Cookbook: GPT Image Prompting Guide).
This is why old ((masterpiece, 8k, trending)) templates have aged poorly. They were designed for CLIP-tokenizer pipelines on SD 1.5 and SDXL. On 2026 models with stronger encoders, those tags either do nothing or build a cluttered prior that fights your actual prompt.
What the Mechanism Predicts
If text becomes vectors before it becomes pixels, then the encoder you target is the most important architectural choice you make — more than any individual prompt. A few testable consequences:
- If you switch from SD 3.5 to FLUX.2 with the same prompt, expect different adherence to long descriptions. FLUX.2’s Mistral encoder reads grammar; SD 3.5’s CLIP-L weights early tokens harder.
- If your prompt’s first 10–15 tokens describe lighting instead of the subject, a CLIP-style encoder will likely amplify lighting at the cost of subject fidelity. Position weight is well-documented for CLIP tokenizers (letsenhance.io: AI Prompt Guide 2026); for T5 and Mistral pipelines the effect is weaker because those encoders model full-sentence semantics.
- If you wrap exact text in quotation marks on FLUX and write it in ALL CAPS, the model will render that text in the image with matching capitalization (Black Forest Labs: FLUX.2 Prompt Guide). Other models won’t honor that convention.
- If you push CFG above roughly 12, expect oversaturation and color bleeding before you expect “stronger adherence.”
Rule of thumb: Read the encoder’s training description before you write the prompt. The grammar that wins is the grammar that encoder was trained on.
When it breaks: Multi-object prompts, in-image text, and explicit pose or location constraints remain weak across all SOTA models — measured systematically across 2025 evaluation frameworks (arXiv: Prompt Robustness 2507.08039). No prompt syntax fully solves “two cats fighting over a precisely-shaped object on the left side of the frame.” The probabilistic backbone has limits no skeleton can hide.
Compatibility notes:
- PromptPerfect EOL: Jina AI’s PromptPerfect closes new signups in June 2026 and goes offline permanently on September 1, 2026 following Elastic’s October 2025 acquisition; user data is deleted 30 days after EOL. Migrate to OpenAI Prompt Optimizer (launched August 2025) or Prompt Builder.
- Negative prompts on GPT Image / Nano Banana: These models do not expose a separate negative-prompt field. Phrase exclusions inside the natural-language prompt instead.
Why “Prompt Magic” Stopped Working
A subtler shift hides inside the encoder change. CLIP-era prompts succeeded by exploiting how a tagged keyword bag biased a small text-image alignment model. The “magic words” worked because the encoder treated them as discrete tokens with strong learned associations to image regions of training data tagged with those exact words.
T5, Mistral, and the multimodal encoders that power GPT Image read sentences. They model dependencies between clauses. “A red car parked on a wet street at dusk, photographed with a 35mm lens” is parsed as a structured description, not as a list of nine tags to be weighted independently. Adding ((masterpiece)) to that prompt does not amplify quality. It introduces an out-of-distribution token that the encoder cannot meaningfully embed — and the model spends some of its sampling capacity trying to render whatever pattern in its training data was tagged with literal parentheses.
The skill being rewarded has changed. The old skill was vocabulary discovery — finding the magic word that unlocked a particular look. The new skill is description — writing the sentence that an attention layer can route cleanly to spatial regions.
Not magic. Geometry.
The Data Says
Image prompting is not a vocabulary game. It is the act of conditioning a stochastic process — and the conditioning signal is shaped by which text encoder the model uses, how cross-attention routes that signal to spatial regions, and how Classifier-Free Guidance scales the push toward your intent. Match your prompt grammar to the encoder, and most of what people call “prompt magic” turns into engineering.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors