What Is Pre-Training and How LLMs Learn Language from Raw Text at Scale
Table of Contents
ELI5
Pre-training is how an AI model reads massive amounts of text and learns language patterns by repeatedly guessing the next word, building a statistical map of how language works — before anyone teaches it a specific task.
Here is something that should bother you: GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, Llama 4 — every frontier model that generates fluent paragraphs, writes working code, and reasons about physics — learned language the same way. By guessing. One token at a time, trillions of times over, from raw text that nobody labeled or organized. The strange part isn’t that it works. The strange part is that prediction, at sufficient scale, starts to look like comprehension.
The Statistical Engine Beneath Every LLM
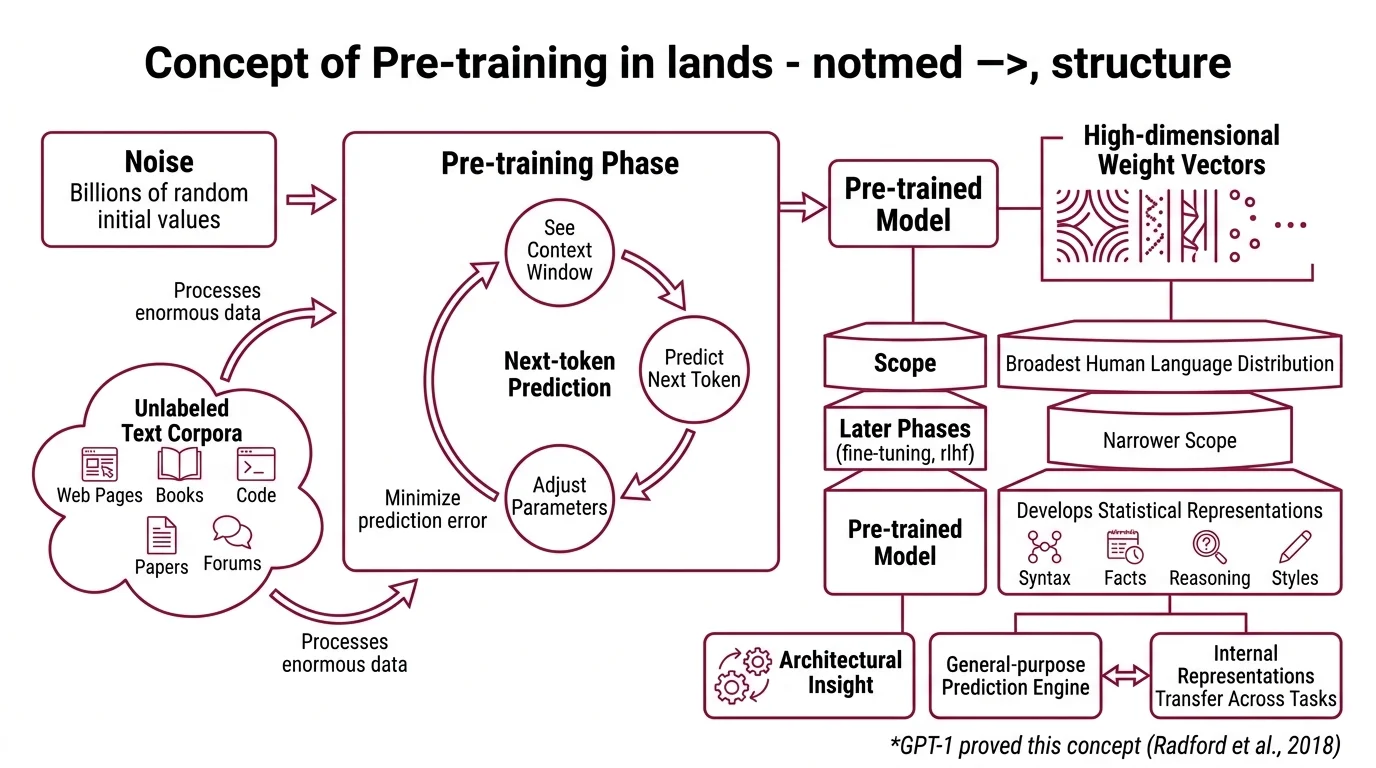
Before pre-training, a language model is noise — billions of parameters initialized to random values, producing nothing more coherent than static. Pre-training is the process that converts that noise into structure. The mechanism is deceptively simple; the consequences are not.
What is pre-training in large language models?
Pre-training is the first and most expensive phase of building a large language model. The model processes enormous corpora of unlabeled text — web pages, books, code repositories, scientific papers, forum threads — and adjusts its parameters to predict missing or upcoming tokens. No human annotator sits in the loop. No one labels each sentence with its meaning or tags it with a category. The model extracts structure from repetition alone.
What makes this phase distinct from Fine Tuning or RLHF is scope. Pre-training covers the broadest possible distribution of human language; later phases narrow it. A model pre-trained on trillions of tokens develops statistical representations that span syntax, factual associations, reasoning patterns, and stylistic registers — all encoded as high-dimensional weight vectors distributed across the network. GPT-1 proved the point in 2018: a single pre-trained model could be fine-tuned to outperform task-specific architectures that had been hand-engineered for years (Radford et al.).
The insight was architectural. A general-purpose prediction engine, given enough data and parameters, builds internal representations that transfer across tasks — not because anyone designed them to, but because transferable representations are the ones that minimize prediction error across diverse text.
How does next-token prediction teach an LLM to understand language during pre-training?
Here is where the mechanism gets interesting — and where the word “understand” deserves its scare quotes.
During autoregressive pre-training, the model sees a sequence of tokens and must predict what comes next. Consider a sentence fragment: “The capital of France is”. To consistently predict “Paris,” the model cannot rely on a simple lookup table. It must develop internal representations that capture geographic relationships, syntactic patterns governing factual statements, and the statistical regularities of how encyclopedic knowledge appears in text.
This is the uncomfortable truth about next-token prediction: the task is shallow but the representations it builds are deep. To predict the next word accurately across a trillion-token corpus, the model must implicitly encode grammar, co-reference chains, causal relationships, and domain knowledge — not because anyone asked it to, but because those structures reduce prediction error.
Think of it like learning music by transcription. Nobody teaches the transcriber harmony theory. But after copying ten thousand scores note by note, the transcriber develops an internal model of harmonic progressions — not because they studied the rules, but because the rules are the shortest description of the patterns they’ve been replicating.
The loss function — cross-entropy between the predicted token distribution and the actual next token — is the only training signal. Scaling Laws describe how this signal compounds: pre-training loss decreases as a smooth power law across seven or more orders of magnitude of compute, data, and model size (Kaplan et al.). Double the compute, and the loss drops predictably. That empirical regularity held across architectures and tasks — though whether the trend extrapolates indefinitely remains an open question, and the observed relationship describes a trend, not a guarantee.
Two Objectives, Two Geometries
Not every model learns language from left to right. The autoregressive objective that powers GPT-family models is one approach; masked language modeling — the engine behind BERT — is a fundamentally different bet on what “learning language” means. Both start from raw text. They produce different kinds of internal geometry.
What is the difference between autoregressive and masked language modeling pre-training objectives?
The autoregressive objective predicts the next token given all preceding tokens — strictly left-to-right (Hugging Face Docs). The model sees “The cat sat on the” and predicts “mat.” This unidirectional constraint means each token’s representation is built exclusively from its leftward context. It is a natural fit for generation: the model produces text one token at a time, each conditioned on everything that came before it.
Masked language modeling, introduced by Devlin et al. in BERT, takes a different approach. Roughly 15% of tokens in each input sequence are randomly replaced with a [MASK] token, and the model predicts the originals from bidirectional context — both left and right simultaneously. The model sees “The [MASK] sat on the mat” and must infer “cat” from the full surrounding sentence.
The architectural consequence matters more than the training trick. Autoregressive models build representations that are generative by construction — they produce text. Masked models build representations that are discriminative — they encode relationships between tokens in both directions, which makes them stronger for classification, named entity recognition, and semantic similarity tasks where the entire input is available at once.
As of March 2026, every frontier generative model — GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, Llama 4 — uses the autoregressive objective. The decoder-only architecture won the generation race. But BERT-family models still dominate embedding and retrieval pipelines, where bidirectional context produces more informative token representations.
The choice of pre-training objective doesn’t just change what the model can do. It changes the shape of the latent space itself — the geometry of what the model knows.
What the Loss Curve Predicts — and Where It Stops
If pre-training loss follows a power law with compute, the obvious move is to throw more hardware at the problem. For years, that strategy worked — until a 2022 result revealed it was systematically wasteful. Compute-optimal training requires scaling model size and training tokens roughly in proportion (Hoffmann et al.); prior practice had been inflating parameters while under-investing in data. Though exact scaling exponents vary across replication studies — a 2025 ACL paper found greater curvature at very large token counts — the directional insight reshaped how frontier labs allocate training budgets.
Pre-training at this scale demands infrastructure that didn’t exist a decade ago. Deepspeed (v0.18.8 as of March 2026) provides ZeRO memory optimization across stages 0 through 3, while Megatron-Core 0.16.1 combines five parallelism types — tensor, pipeline, data, expert, and context — to achieve 47% Model FLOP Utilization on H100 clusters (NVIDIA GitHub). Data Deduplication matters just as much as parallelism: MinHash LSH remains the dominant deduplication technique at scale, preventing the model from memorizing repeated passages rather than generalizing from diverse ones.
The practical predictions follow directly from the mechanism:
- If you increase compute without proportionally increasing unique training data, pre-training loss will plateau earlier than the scaling curve suggests.
- If your training corpus contains significant duplication, the model overfits to repeated patterns — memorizing rather than generalizing.
- If you pre-train a model with insufficient parameter capacity on reasoning-heavy evaluations, additional data yields diminishing returns; the model lacks the representational depth to encode the structures that reduce error on those tasks.
Rule of thumb: Pre-training builds the foundation; its quality determines the ceiling that fine-tuning and RLHF can reach. A poorly pre-trained model cannot be rescued by alignment alone.
When it breaks: Pre-training fails silently. A model trained on biased, duplicated, or insufficiently diverse data will produce fluent, confident outputs that embed systematic errors — and no amount of downstream fine-tuning fully corrects what the base distribution got wrong. The failure mode is not incoherence; it is confidently wrong coherence.
Security & compatibility notes:
- Megatron-LM Code Injection (CVSS 7.8): Two vulnerabilities (CVE-2025-23357, CVE-2026-24149) enabling code injection in earlier versions. Fix: upgrade to Megatron-Core v0.14.0 or later.
The Data Says
Pre-training is prediction at scale — a model guessing the next token across trillions of examples until the statistical residue of that process contains syntax, semantics, and something that resembles reasoning. Not understanding. Compression. And the difference between a mediocre model and a frontier one is not architecture alone; it is how much of the world’s written structure was compressed into those weights, how cleanly, and whether anyone bothered to deduplicate the corpus before the meter started running.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors