What Is Multimodal RAG and How It Retrieves Across Images, Tables, and Text
Table of Contents
ELI5
Multimodal RAG (MRAG) extends retrieval-augmented generation beyond text. It pulls relevant evidence from images, tables, charts, and prose, then hands the bundle to a vision-capable LLM for synthesis. Same idea as text RAG; harder geometry.
Picture a financial analyst asking a chatbot, “What did revenue do in Q3?” The answer lives in a bar chart. The surrounding paragraphs describe macro trends. The footnote names the exception that explains both. A text-only RAG system reads the prose, ignores the chart, and produces a confident sentence that contradicts the figure on page seven. This is the gap multimodal RAG was built to close — and the gap is wider, and geometrically stranger, than most early architectures assumed.
What Multimodal RAG Actually Is — and What It Isn’t
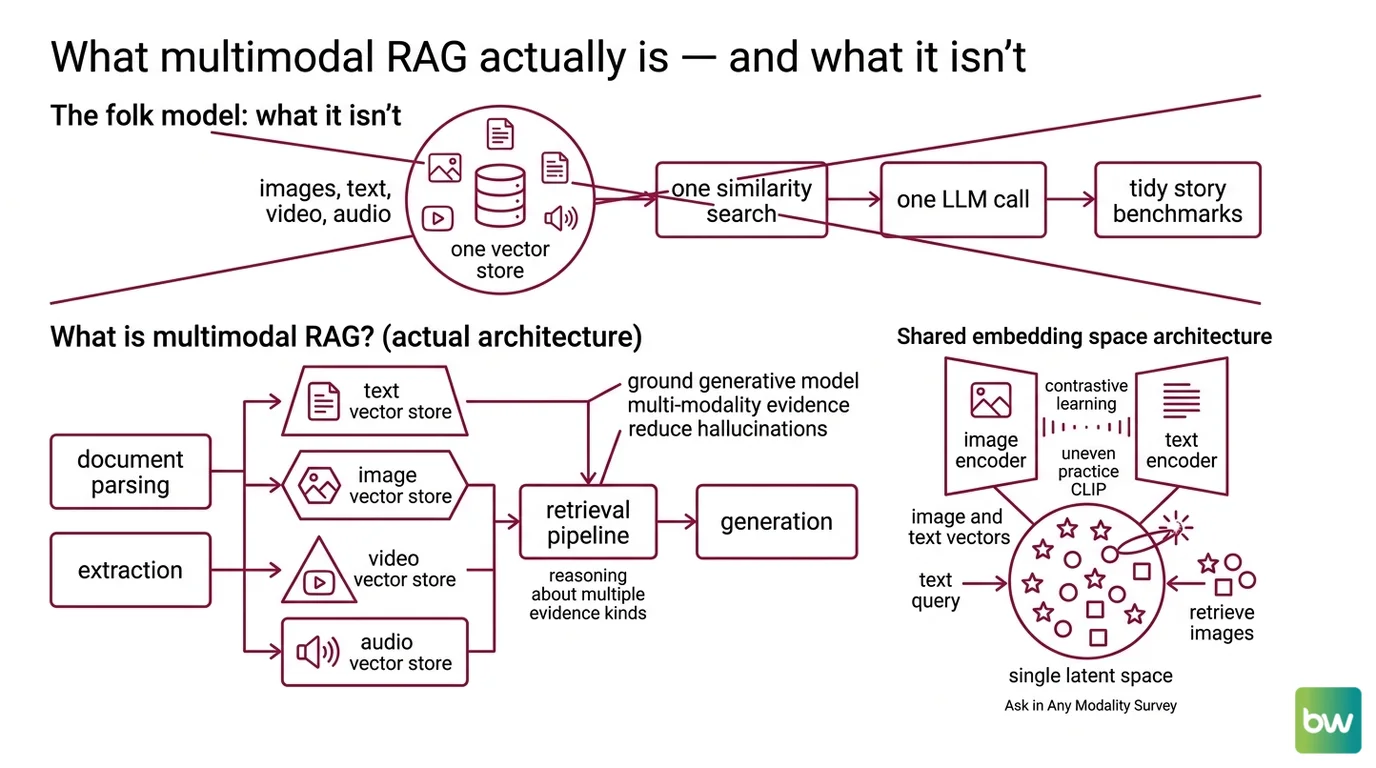
The folk model goes: take RAG, plug in CLIP, done. One embedding model for everything, one vector store, one similarity search, one LLM call. Clean. The benchmarks tell a less tidy story.
What is multimodal RAG?
Multimodal RAG, or MRAG, is the practice of grounding a generative model in evidence that spans more than one modality — text, images, video, audio, and structured tables — rather than text alone. The goal is identical to text RAG: reduce hallucinations by injecting verified context into the prompt. The complication is that “context” no longer fits into a single vector geometry. The MRAG survey by Mei et al. organizes the architecture around three stages — retrieval, embedding, and generation — but each stage now has to reason about what kind of evidence it is handling, not just what it says (Mei et al., MRAG Survey).
Not a chatbot with eyes. A retrieval pipeline whose probability landscape includes pixel grids and cell positions.
The Document Parsing And Extraction step matters more here than in text RAG. If your chart is locked inside a PDF and your parser flattens it to “Figure 3,” the retriever has nothing to retrieve. The architecture is downstream of parsing.
How Retrieval Crosses Modal Boundaries
Three architectures dominate the practical literature, and they make different bets about where to spend complexity. The choice determines whether your system trips on tables, on infographics, or on the seam between them.
How does multimodal RAG work across images, tables, and text?
The first approach uses shared-embedding-space models like CLIP and BLIP, which encode both images and text into a single latent space using contrastive learning with dual-tower encoders (“Ask in Any Modality” Survey). A query in text can directly retrieve images whose vectors sit nearby. The geometry is elegant; the practice is uneven. CLIP was trained on web-scale image-caption pairs, which means it understands cats and book covers far better than it understands a column of pivot-table figures or a sankey diagram. The cosine similarity is real. The relevance is not always.
The second approach inverts the problem. Rather than force every modality into one embedding space, a multimodal LLM produces text summaries of images and tables; those summaries are embedded with a normal text encoder; and retrieval happens entirely in text space. Retrieval moves into text geometry. On a hit, the system fetches the raw image or table and passes it to the synthesis LLM. LangChain documents this as the multi-vector retriever pattern, with three concrete strategies: joint multimodal embeddings, summary-driven retrieval, and a hybrid where summaries drive retrieval but raw images flow to synthesis (LangChain Blog). A counterintuitive finding the MRAG survey echoes: text summaries from images often outperform raw multimodal embeddings in practice (Mei et al., MRAG Survey).
The third approach skips parsing entirely. ColPali, published in July 2024 by Faysse et al., uses a vision language model (PaliGemma-3B) to embed each PDF page image as a grid of patches, then matches queries with ColBERT-style late interaction (ColPali Paper). No OCR. No layout reconstruction. No chunking. The page is the unit of retrieval, and the retriever sees it the way a human glancing at the document would. On the ViDoRe benchmark, ColPali outperformed every evaluated system, with the largest gains on visually complex tasks — InfographicVQA, ArxivQA, TabFQuAD (ColPali Paper). The family later expanded to ColQwen2 and ColSmol, riding different VLM backbones.
Three architectures, three different bets:
| Approach | Retrieval space | What it handles well | Where it struggles |
|---|---|---|---|
| Shared embeddings (CLIP / BLIP) | Joint vision-text vectors | Natural images, captions | Dense tables, technical charts |
| Summarize-then-embed | Pure text vectors | Tables, mixed content | Cost of summary generation |
| Vision-first (ColPali / ColQwen2) | Page-image patch vectors | Charts, infographics, PDFs | Compute and storage at scale |
The trade-off is not which is best. It is which failure mode you can tolerate.
The Anatomy of a Multimodal RAG System
Strip away the architectural choice and a multimodal RAG system still resolves to the same three stages. They look like text RAG. They behave differently.
What are the components of a multimodal RAG system?
Stage one: retrieval. A document parser — Unstructured, LlamaParse, IBM Docling — extracts text blocks, tables, and embedded images from source files (IBM Tutorial). Each element is stored with metadata that the retriever can filter on later. Metadata Filtering is what keeps retrieval honest when modalities mix; without it, an image and a paragraph with similar vector distance compete for the same slot regardless of whether either is relevant to the query.
Stage two: embedding. This is where the architectural bet is placed. LlamaIndex’s MultiModalVectorIndex, for example, indexes text and images into separate vector store collections — text via a text embedding model, images via an image embedding model and stored as base64 or path references (LlamaIndex Docs). The two collections are queried in parallel and results are merged. LangChain’s multi-vector retriever, by contrast, supports the three strategies described above — joint multimodal embeddings, text-summary embeddings with raw retrieval, and the hybrid that decouples retrieval reference from synthesis content.
Stage three: generation. A multimodal LLM — GPT-4V class, Gemini multimodal, Claude with vision, LLaVA, or Qwen2-VL — consumes the retrieved bundle and produces an answer (LangChain Blog). The handoff is the subtle part. Tables, in particular, are typically summarized for retrieval but passed raw to the synthesis model, decoupling what the retriever sees from what the generator reads. The retriever needs a low-dimensional handle. The generator needs the full structure.
For richly interconnected domains, MRAG can also be combined with Knowledge Graphs For RAG, where retrieved entities link back to graph nodes that anchor the multimodal evidence in a structured ontology. That layering is optional. The three stages above are not.
What the Geometry Predicts
Once the three stages are in place, the system’s failures stop being random. They become geometrically predictable.
- If your queries are conceptual but your documents are visual (infographics, scanned reports, technical schematics), expect shared-embedding-space retrievers to underperform. CLIP-class models were not trained on dense document layouts, and the cosine similarities reflect that gap.
- If your documents are mostly text with embedded tables, the summarize-then-embed pattern usually beats joint embeddings. The retriever benefits from operating in well-trained text geometry, and the table itself is preserved for synthesis.
- If your domain is visually dense PDFs — research papers, financial reports, technical diagrams — vision-first retrievers like ColPali shift the cost from preprocessing to inference, and the trade is usually worth it.
- If your retriever and your synthesizer disagree about evidence, the seam will surface as confidently wrong answers grounded in irrelevant context. That is the worst failure mode, because the user has no signal that anything is off.
Rule of thumb: match the retrieval space to the modality where your evidence actually lives — not the modality your query is written in.
When it breaks: Multimodal RAG can outperform single-modality RAG, but the gain is not monotonic. Text summaries derived from images frequently beat raw multimodal embeddings on retrieval quality (Mei et al., MRAG Survey). The naive “more modalities is better” intuition collapses when summary fidelity, embedding alignment, and per-modality evaluation are not separately controlled.
Compatibility notes:
- LangChain → LangGraph: Production code has shifted toward LangGraph, and v0.2 introduced breaking renames (
thread_ts → checkpoint_id,parent_ts → parent_checkpoint_id) plus changed import paths. Older multi-vector retriever tutorials may need updating before they run.- LlamaIndex docs: Canonical URL moved from
docs.llamaindex.aitodevelopers.llamaindex.ai. Old links 301-redirect, but bookmarks and code comments should point to the new domain.- OCR-first pipelines: Older “extract → chunk → embed” tutorials remain valid for plain prose but are no longer state-of-the-art for visually rich documents — vision-first retrievers like ColPali and ColQwen2 lead on charts, infographics, and dense layouts.
Why the Surface Looks Settled and the Mechanism Doesn’t
Multimodal RAG papers describe pipelines as if the architecture has converged. The benchmarks suggest otherwise. ColPali’s success comes from refusing the very preprocessing that the LangChain summarize-then-embed pattern depends on. Both approaches outperform CLIP on visually rich documents. Neither resembles the other. The “settled” architecture exists at the API surface — retrieve(), generate() — and only there. Underneath, the field is still arguing about where, exactly, modality should be flattened into a vector.
That argument has consequences for system design. For visually dense documents, vision-first retrievers appear to be winning. For mixed text-and-table workflows, the text-summary detour is hard to beat. For everything in between, it remains an empirical question — one that depends on your documents more than on your model.
The Data Says
Multimodal RAG is not text RAG with image embeddings bolted on; it is a routing problem across distinct vector geometries, and the architectural choice determines which failure modes you inherit. Vision-first retrievers like ColPali outperform OCR-then-chunk pipelines on visually complex tasks (ColPali Paper), while text summaries of images can still beat raw multimodal embeddings on retrieval quality (Mei et al., MRAG Survey). The technology is converging on three stages — retrieval, embedding, generation — but the embedding stage is where every meaningful bet still gets placed.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors