Multimodal Architecture: How Models Fuse Text, Images, Audio & Video
ELI5
Multimodal architecture is the design pattern that lets one neural network accept signals from multiple senses — text, pixels, waveforms, video frames — and process them in the same internal space. The trick: everything gets translated into token-like vectors before the model actually reasons.
A naive mental model says Gemini 3.1 Pro “looks at” an image the way a retina does — photons in, understanding out. The reality is stranger. Inside the network, that image never stays an image for long. It gets compressed into a small set of vectors that sit beside the word embeddings and behave, for all downstream purposes, like text tokens with a foreign accent. The decoder is still an autoregressive text generator. It just learned to listen to aliens.
The trick inside every natively multimodal model
Ask a model architect what makes GPT-5 or Gemini 3.1 Pro “multimodal” and the answer is not one architecture — it is a convention about where modalities meet. The meeting place is the token stream.
What is multimodal architecture in AI?
Multimodal architecture refers to any neural network design that ingests more than one type of signal and maps those signals into a shared representation where reasoning can happen. Baltrušaitis and colleagues catalogued the five core problems this creates — representation, translation, alignment, fusion, and co-learning — in a taxonomy that still frames the field (Baltrušaitis et al.).
The abstract goal is stable: get a text encoder, a vision encoder, and an audio encoder to produce vectors that live in the same geometric neighbourhood when they describe the same thing. If the vector for the word “violin” ends up near the vector for a photograph of a violin and near the vector for a clip of violin audio, a downstream decoder can treat all three as interchangeable inputs to the same reasoning process.
What changed in the LLM era is that this shared space is no longer a generic joint embedding. It is the embedding space of a pre-trained language model. Everything else has to pay tribute to it.
What does it mean for a model like GPT-5 or Gemini 3.1 Pro to be multimodal?
“Natively multimodal” is a marketing phrase with a specific technical implication: the model was pre-trained on interleaved multimodal sequences, not text-first-then-image-bolted-on. The accepted token stream itself can contain text, image patches, audio frames, and video frames in any order.
The practical profiles diverge by vendor as of April 2026. Gemini 3.1 Pro, released 2026-02-19, accepts text, images, audio, and video in a 1M-token input window (Gemini 3.1 Pro Model Card). GPT-5, launched 2025-08-08, handles text, images, audio, and video as native inputs (OpenAI GPT-5 Announcement). Claude Opus 4.7, released 2026-04-16, accepts text and images only — no native audio or video ingestion at the time of writing (Anthropic Claude Opus 4.7 News). “Native multimodal” means different things at different labs; it is a spectrum, not a binary.
Not a feature. A pre-training decision.
The three-stage pipeline hiding behind “one model”
The closed-weight flagships do not publish their connector architectures. What the field knows about the general shape comes from open-source analogues — LLaVA, BLIP-2, Flamingo, OmniVinci — where the full graph is visible. The pattern those systems share is now the pedagogical canon.
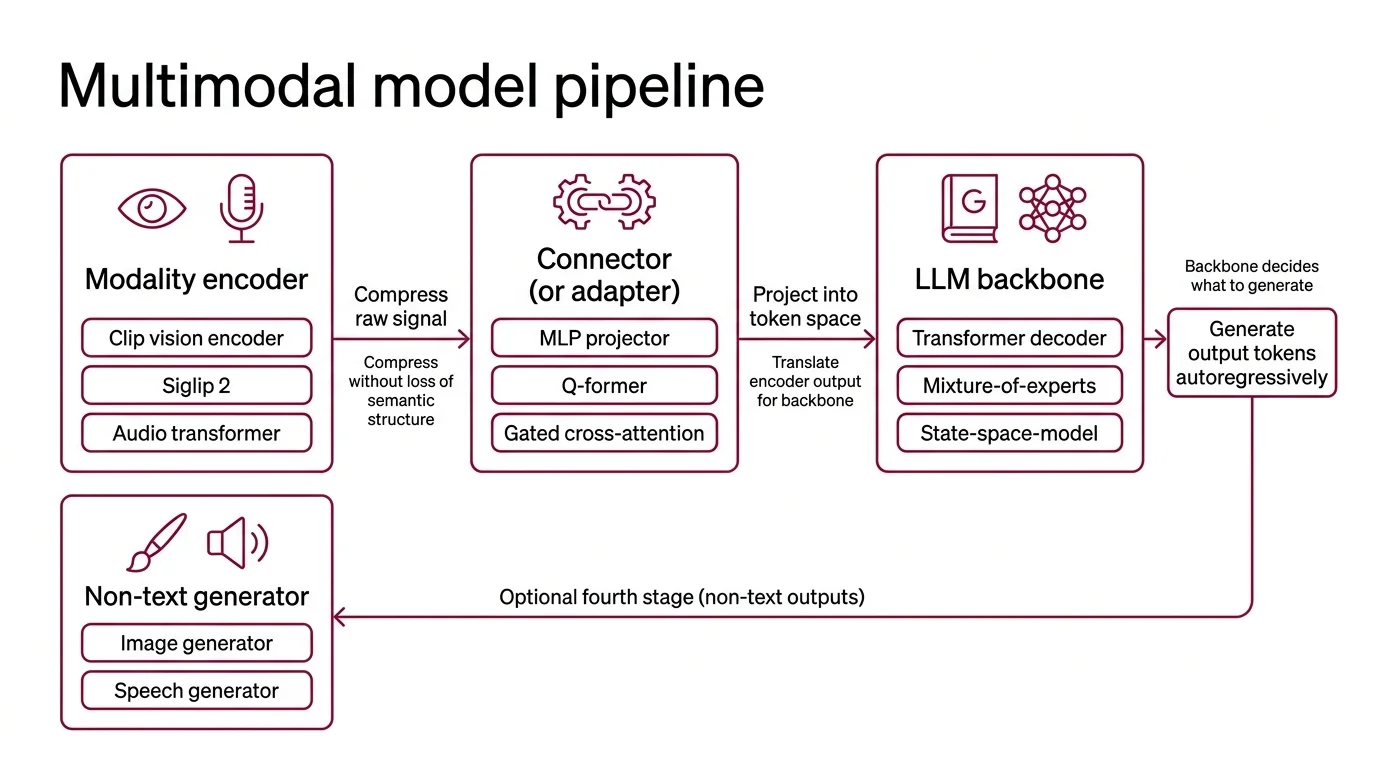
What is a modality encoder, connector, and LLM backbone in a multimodal architecture?
Every modern multimodal system can be read as three sequential components (Zhang et al., MM-LLMs survey):
| Component | Job | Typical Example |
|---|---|---|
| Modality encoder | Compress a raw signal (pixels, waveform) into feature vectors | CLIP vision encoder, SigLIP 2, audio spectrogram transformer |
| Connector (or adapter) | Project those feature vectors into the LLM’s token space | MLP projector, Q-Former, gated cross-attention |
| LLM backbone | Generate output tokens autoregressively, conditioned on the projected features plus any text tokens | A transformer decoder, often a Mixture Of Experts variant |
An optional fourth stage appears when the model needs to produce non-text outputs: a generator for images or speech.
The encoder’s job is compression without loss of semantic structure. The canonical modern vision encoder is a Vision Transformer trained on paired image-caption data, with CLIP still serving as the reference recipe for contrastive alignment between images and text. It is not the only option anymore — SigLIP 2 has taken the lead on several zero-shot and dense-prediction benchmarks — but CLIP remains the pedagogical starting point.
The backbone is almost always an existing text LLM. Whether that backbone is a standard transformer, a mixture-of-experts transformer, or a newer State Space Model hybrid, the connector logic is the same: translate the encoder’s output into something the backbone was already trained to consume. The backbone decides what “intelligent output” looks like. The connector is the translator between two foreign languages.
How do multimodal models process text, images, audio, and video in a single network?
This is where the architectural variants actually diverge. Three connector families dominate current systems (Connector-S Survey):
Projection-based connectors are the simplest. LLaVA pioneered the pattern: take the vision-encoder features, pass them through a shallow MLP, and concatenate the resulting vectors into the LLM’s input sequence. The entire connector adds a tiny fraction to the parameter count, yet it is where the cross-modal alignment gets learned. This pattern now dominates the open-source multimodal stack.
Query-based connectors compress variable-length modality features into a fixed number of output tokens. BLIP-2’s Q-Former and Flamingo’s Perceiver Resampler are the canonical examples: a small transformer carrying a handful of learnable query vectors that extract a fixed-length summary from the raw encoder output. Query-based connectors shine when you want strict control over sequence length — useful for long videos, where naïvely concatenating thousands of frame tokens would blow the context window.
Fusion-based connectors interleave cross-attention layers directly into the LLM backbone. Flamingo introduced gated cross-attention — inserted between frozen LLM blocks, with a learnable gate that initialises to zero — so visual context could seep into text generation without destabilising the backbone at training start. The gate starts closed and opens as cross-modal signal becomes useful.
Audio introduces its own encoder (usually a spectrogram transformer or Whisper-style encoder) but feeds into the same connector pattern. Video is commonly handled as a temporal stack of image tokens with positional encodings that include time. NVIDIA’s OmniVinci research pushes further, training a shared contrastive objective across vision and audio embeddings so both land in a single omni-modal latent space before they ever reach the connector.
The frontier commercial systems — GPT-5, Gemini 3.1 Pro, Claude Opus 4.7 — do not confirm which connector family they use. Public descriptions are consistent with hybrids: likely projection for short-context image input, query-based compression for video, and some form of cross-attention for joint reasoning. Treat any specific claim about their internals as speculation.
Fusion: when the modalities actually meet
Even before “multimodal LLM” was a category, machine-learning researchers argued about the timing of modality fusion. That taxonomy still explains why 2026 architectures look the way they do.
How does early fusion differ from late fusion in multimodal AI systems?
The classical taxonomy from Baltrušaitis and colleagues distinguishes three fusion regimes (Baltrušaitis et al.):
- Early fusion combines modalities at the input or low-level feature stage. Raw signals or shallow features are concatenated before any modality-specific deep processing; the downstream network cannot tell where its input features came from. Strong when modalities carry tightly correlated information at the signal level; fragile when one modality is missing or noisy.
- Late fusion (decision-level fusion) runs each modality through its own end-to-end model and combines only the final predictions — by averaging, voting, or a learned aggregator. Robust to missing modalities and easy to debug. But the modalities never actually influence each other’s internal reasoning, which limits integration depth.
- Intermediate fusion has modality streams meet in hidden layers, inside a shared latent space. Neither raw nor final — somewhere in the middle.
The encoder-connector-backbone pattern used by every MLLM you will touch is intermediate fusion wearing modern clothes. Each modality gets its own specialist encoder (like late fusion), but the outputs are projected into the LLM’s token space and then reasoned over jointly (unlike late fusion). The fusion point is the LLM’s attention layers. From there on, a sequence token for an image patch and a sequence token for a word are processed by the same transformer blocks using the same attention mechanism.
It is why these models can answer “what is the person in the image holding?” — the image tokens and the text tokens genuinely attend to each other. And it is why they still hallucinate details the image does not contain. Cross-modal attention is no more “grounded in truth” than text-only attention; it is probabilistic, all the way down.
What the pipeline predicts when things go wrong
Understanding the pipeline turns passive usage into active debugging. A few predictions fall out of it:
- If you feed a high-resolution image into a model using a fixed-length query connector, expect spatial detail loss. The connector is compressing features into a small fixed budget regardless of input size. Fine print at the corners of a document will not survive that bottleneck.
- If a model claims to “see” a video, check whether it samples frames sparsely or processes dense temporal tokens. Sparse sampling produces confident-sounding answers about events that happened between the sampled frames — hallucinated by interpolation.
- If cross-modal grounding feels weaker than text-only reasoning, that is expected. The LLM backbone was pre-trained on far more text than on aligned multimodal data. The connector is doing serious work on a thin budget.
Rule of thumb: the connector is the quietest component by parameter count and the loudest by influence on output quality. It is where most of the cross-modal intelligence actually lives.
When it breaks: the dominant failure mode is modality collapse under the LLM prior — the text backbone’s prior knowledge outweighs fresh visual evidence, producing confident text that contradicts what the image actually shows. It is the multimodal version of a hallucination, and it gets worse as the prompt becomes more suggestive. Projection-based connectors are especially exposed because they pass features through without explicit alignment supervision, leaving the backbone free to ignore them under pressure.
A surprising consequence: your interface is already a token stream
The encoder-connector-backbone pattern has a subtle implication for how you prompt these models. Because images become tokens, they compete with text tokens for the same attention budget. Long conversations with a photo attached behave exactly like long conversations with an extra paragraph of cryptic text attached — the “photo” decays in attention the further back in the context window it sits. If your multi-turn visual dialog starts giving wrong answers in turn seven, the image did not get “forgotten” in any biological sense. It got out-attended.
The analogue in audio is more vivid. A minute of speech becomes a long sequence of audio tokens; a short sentence of text becomes a short sequence of text tokens. The audio will dominate attention simply by volume — unless the connector applied compression first. Which is exactly why query-based connectors exist.
The Data Says
Multimodal architecture in 2026 is converging on a single pattern: specialist encoders, a lightweight connector, and a shared LLM backbone where attention does the actual fusion. The variety is at the connector — projection, query-based, or cross-attention — not at the backbone. The bottleneck on cross-modal intelligence is not the backbone’s reasoning; it is the bandwidth of the bridge between the encoder’s world and the backbone’s token stream.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors