What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
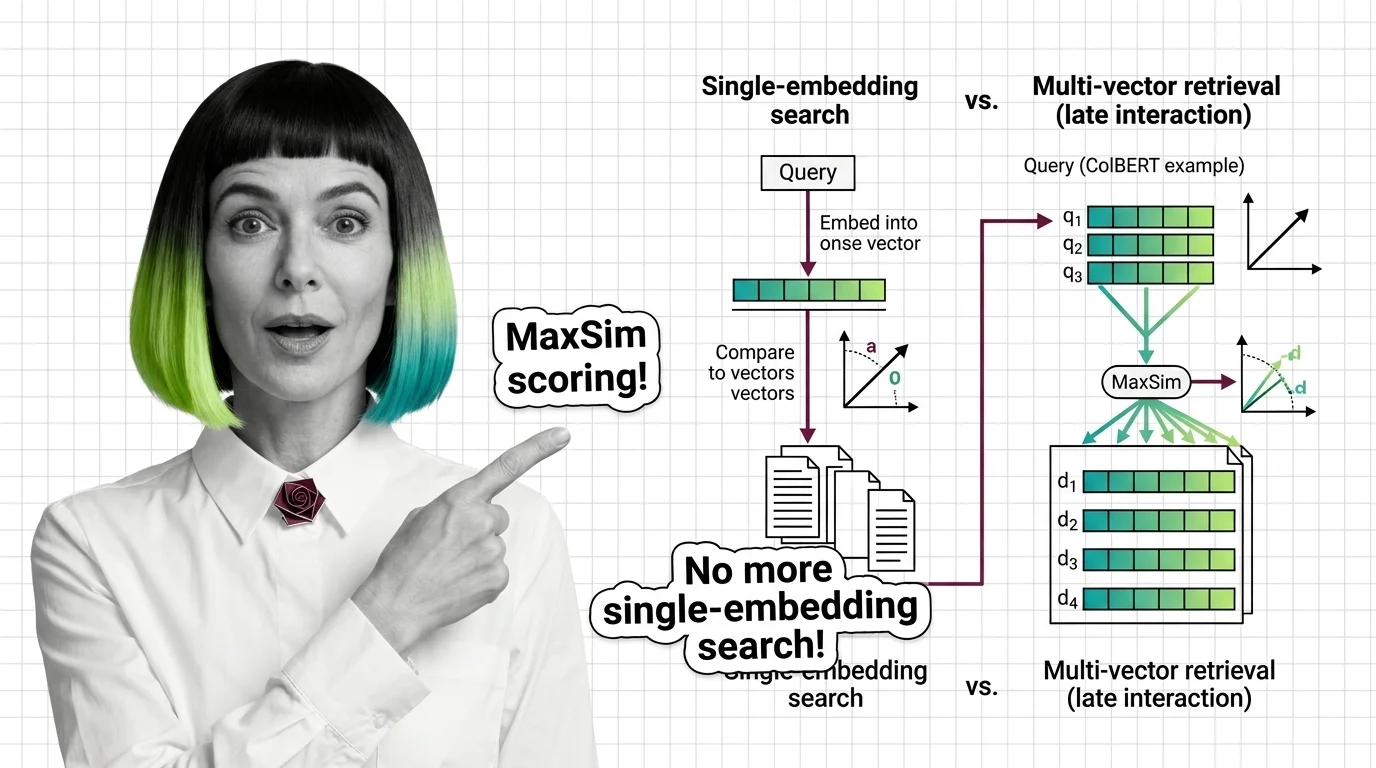
Table of Contents
ELI5
Multi-vector retrieval stores a separate embedding for every token in a document, then scores relevance by matching each query token to its best counterpart — preserving word-level nuance that single-vector search destroys.
Search a million documents for “jaguar speed record” and a Dense Retrieval pipeline will return confident results — some about cars, some about cats, a few about an Atari console nobody remembers. The system compressed each passage into one point in vector space, and somewhere in that compression, “jaguar” stopped meaning anything specific. Multi-vector retrieval was built to prevent this exact collapse, and the geometry behind it is simpler than most engineers expect.
What Happens When You Keep Every Token
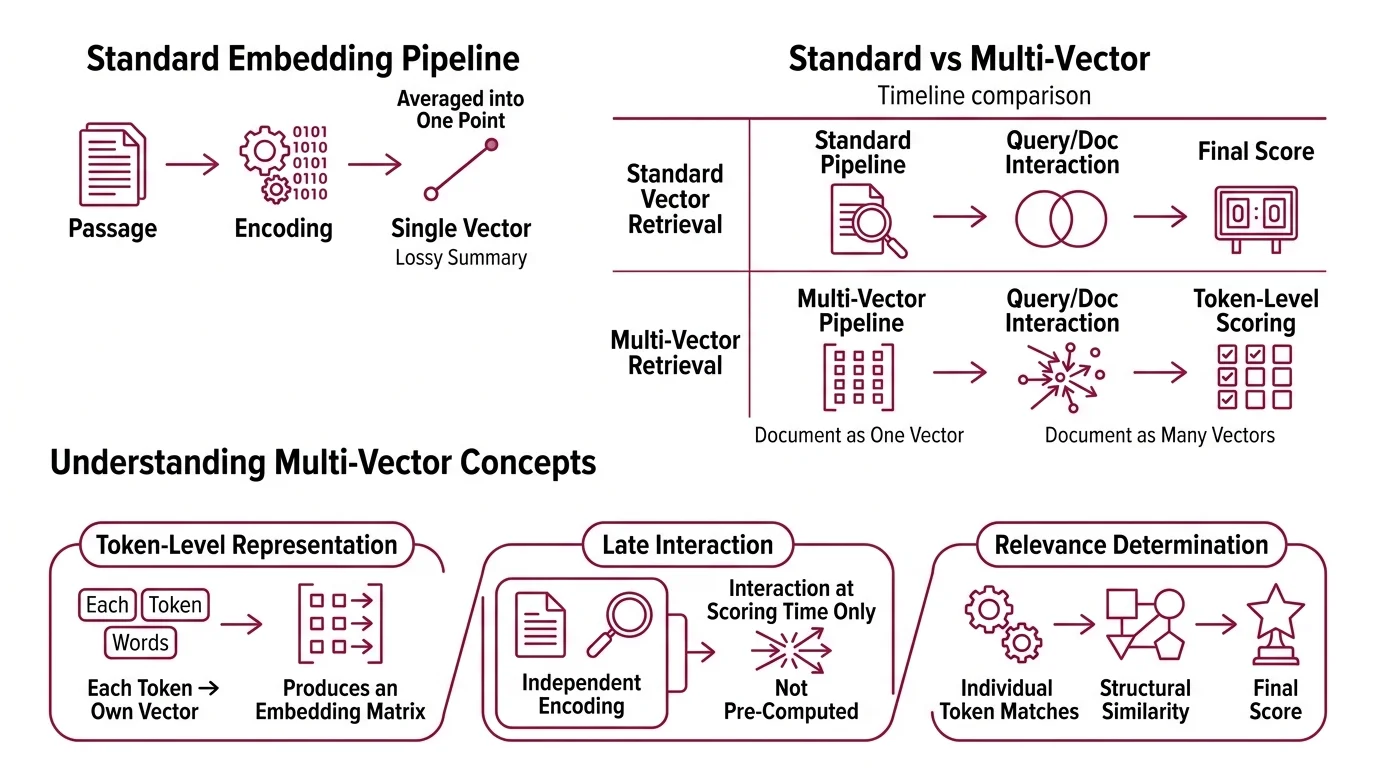
Standard Embedding pipelines encode a passage — fifty words, two hundred, a full paragraph — into a single vector. That vector is a lossy summary: every token’s contribution averaged into one point in high-dimensional space. The summary works most of the time. The question is what it quietly discards.
What is multi-vector retrieval in information retrieval?
Multi-vector retrieval replaces the single-vector paradigm with a token-level representation. Instead of mapping a document to one point, the system maps each token to its own vector — producing a matrix of embeddings rather than a single row.
A passage with 80 tokens becomes 80 vectors, each occupying 128 dimensions (the standard ColBERT dimension, as documented by Jina AI). The query undergoes the same treatment: each query token becomes its own vector. Relevance is no longer a single dot product between two compressed summaries. It is a structured form of Similarity Search Algorithms applied at the token level, where the geometry of individual matches determines the final score.
The critical property: query and document are encoded independently, and their representations only interact at scoring time. That independence gives the approach its name — late interaction.
Not more computation. Computation at the right moment.
From Exact Words to Token Geometry
Retrieval methods sit along a spectrum defined by where they combine meaning — and what gets discarded at each stage. The differences determine which queries your system answers well and which ones it silently mishandles.
How does multi-vector retrieval differ from single-vector dense retrieval and BM25?
BM25 operates on exact lexical overlap. It counts term frequencies, adjusts for document length, and scores based on how often query words appear in the passage. It knows nothing about semantics; “automobile” and “car” are strangers. But BM25 is fast, interpretable, and surprisingly hard to beat when the user’s vocabulary matches the document’s.
Single-vector dense retrieval fixes the vocabulary gap by encoding query and document into a shared semantic space. “Automobile” and “car” land near each other. The cost: every token’s meaning gets compressed into one vector. A passage about “bank erosion along the river” and one about “bank fraud in the financial sector” can end up at similar coordinates — because the averaged representation discards the distinguishing context.
Multi-vector retrieval keeps the semantic understanding but defers the aggregation. Each token retains its own position in the space. The word “bank” in a passage about rivers sits in a different region than “bank” in a passage about finance, because the contextual encoding — via BERT’s attention layers — produces different vectors for each occurrence. The match happens token by token; only then does the system sum into a final score.
The tradeoff is storage. A single-vector system stores one vector per document. A multi-vector system stores one per token. For a corpus of a million passages at 80 tokens each, that is 80 million vectors — a factor of 80x in Vector Indexing requirements. Whether that cost is justified depends entirely on how much nuance your queries demand.
The MaxSim Trick and ColBERT’s Architecture
ColBERT — Contextualized Late Interaction over BERT — was introduced by Khattab and Zaharia at SIGIR 2020 and formalized the late interaction paradigm with a specific scoring operator and a practical architecture. The model runs on a BERT-base backbone with approximately 110 million parameters (Weaviate Blog): small enough that encoding is fast, large enough that the contextual embeddings carry real semantic weight.
Documents get encoded offline. Each token’s hidden state is projected to 128 dimensions and stored as a matrix. Only the query needs encoding at search time — and a short query encodes in milliseconds.
How does ColBERT late interaction use per-token vectors and MaxSim to score documents?
MaxSim — maximum similarity — is the operator that converts two token matrices into a single relevance score.
For each query token, compute the cosine similarity against every token in the document. Take the maximum. Then sum those maxima across all query tokens.
That is the entire scoring function.
The elegance is in what it captures. Each query token finds its single best match in the document, regardless of position. The word “speed” in the query matches wherever the most relevant mention of speed appears in the passage. The word “jaguar” matches the contextually appropriate occurrence — the one near “engine” and “horsepower,” not the one near “habitat” and “prey.” A document that matches most query tokens well, even if imperfectly, outscores one that matches a single token perfectly and ignores the rest.
Decomposability is what makes precomputation possible — because document-side encoding happens before any query arrives, the computational cost at query time scales with query length (short) rather than document length (long). The original ColBERT paper reported 180x fewer FLOPs than a full BERT cross-encoder at k=10 retrieved passages (Jina AI) — though these benchmarks date to 2020 and may not reflect current hardware optimizations.
What are per-token embeddings, MaxSim operator, and residual compression in ColBERT?
The three components form a tight system, each solving a different part of the multi-vector problem.
Per-token embeddings are the representation layer. Each token passes through BERT’s attention mechanism — gaining context from surrounding tokens — then gets projected to a 128-dimensional vector. Unlike bag-of-words representations, these embeddings are contextual: the vector for “bank” depends on whether surrounding tokens discuss rivers or finance. The context lives inside each vector, not in a separate lookup table.
The MaxSim operator is the scoring layer. For a query with q tokens and a document with d tokens, MaxSim computes a q-by-d similarity matrix, takes the row-wise maximum for each query token, and sums the result. The operation is differentiable, which means the entire system — encoding and scoring — trains end-to-end with standard gradient descent. No hand-tuned weighting between components; the model learns what constitutes a good match from relevance labels alone.
Residual compression is the storage layer, introduced in ColBERTv2 (Santhanam et al., NAACL 2022). Storing 128-dimensional float vectors for every token in a large corpus gets expensive fast. ColBERTv2 clusters the token vectors, stores each as a centroid ID plus a quantized residual — the difference from the cluster center, encoded at 1-bit precision — and achieves a 6-10x storage reduction, roughly 20-36 bytes per vector depending on centroid count and residual bit-width (Santhanam et al.). The compression is lossy, but it preserves enough geometric structure to keep MaxSim scoring accurate.
What Token-Level Geometry Predicts
The implications of keeping every token follow directly from the geometry.
If your queries are short and unambiguous — “ColBERT MaxSim scoring” — single-vector dense retrieval will likely perform comparably, because the query is specific enough that a compressed vector captures its intent. Multi-vector retrieval shows its advantage on ambiguous queries where different tokens pull toward different meanings.
If your documents are long and heterogeneous — technical manuals, legal contracts, research papers with methodology and results interleaved — the token-level representation captures internal structure that a single vector cannot. A section discussing both experimental setup and findings produces vectors in two distinct regions of the embedding space; a single vector would land somewhere between them, matching neither query type particularly well.
The late interaction paradigm has extended beyond text. ColPali (Faysse et al., ICLR 2025) applies MaxSim scoring to document images, treating visual patch embeddings as the token analogue via a PaliGemma-3B backbone. The ecosystem now includes ColQwen2 — Apache 2.0 licensed, approximately 2 billion parameters — and ColQwen3, with colpali-engine reaching version 0.3.14 as of February 2026 (ColPali GitHub).
For Python-based RAG integration, RAGatouille (version 0.0.9) wraps ColBERTv2 — though its maintenance is transitioning to a pylate backend, and LangChain integration has reported breakage. Verify compatibility before depending on it for production workflows.
Rule of thumb: If your retrieval failures trace to polysemy or query ambiguity, token-level scoring will likely help. If they trace to missing documents or vocabulary coverage, the problem sits upstream of any scoring function.
When it breaks: Multi-vector retrieval struggles when storage or latency budgets are tight — the per-token index is an order of magnitude larger than single-vector alternatives, and MaxSim scoring across millions of documents requires careful engineering (PLAID indexing, pre-filtering) to remain fast. On short, unambiguous queries, the extra granularity adds cost without measurably improving relevance.
The Data Says
Multi-vector retrieval answers a specific failure of dense search: the loss of token-level nuance during encoding. ColBERT’s MaxSim operator recovers that nuance by deferring interaction to scoring time, and residual compression makes the storage tradeoff manageable — though never free. The mechanism is geometric, the tradeoff is storage, and the decision to adopt it should follow from whether your retrieval failures trace back to meaning that one vector could not hold.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors