What Is Model Inference and How LLMs Generate Text Through Autoregressive Decoding
Table of Contents
ELI5
Model inference is a trained neural network producing output from new input. For LLMs, that means generating text one token at a time — each new token conditioned on every token before it.
You type a question. Two seconds later, text streams back — smooth, coherent, suspiciously fluent. The experience suggests the model composed a complete thought and is now reading it aloud.
It didn’t. It produced one token, looked at everything generated so far, produced the next, and repeated the loop several hundred times. The fluency is a surface effect. Underneath is a strictly sequential process where each step waits for the previous one to finish — and that sequential dependency shapes every optimization decision in modern LLM serving.
Five Hundred Forward Passes for One Response
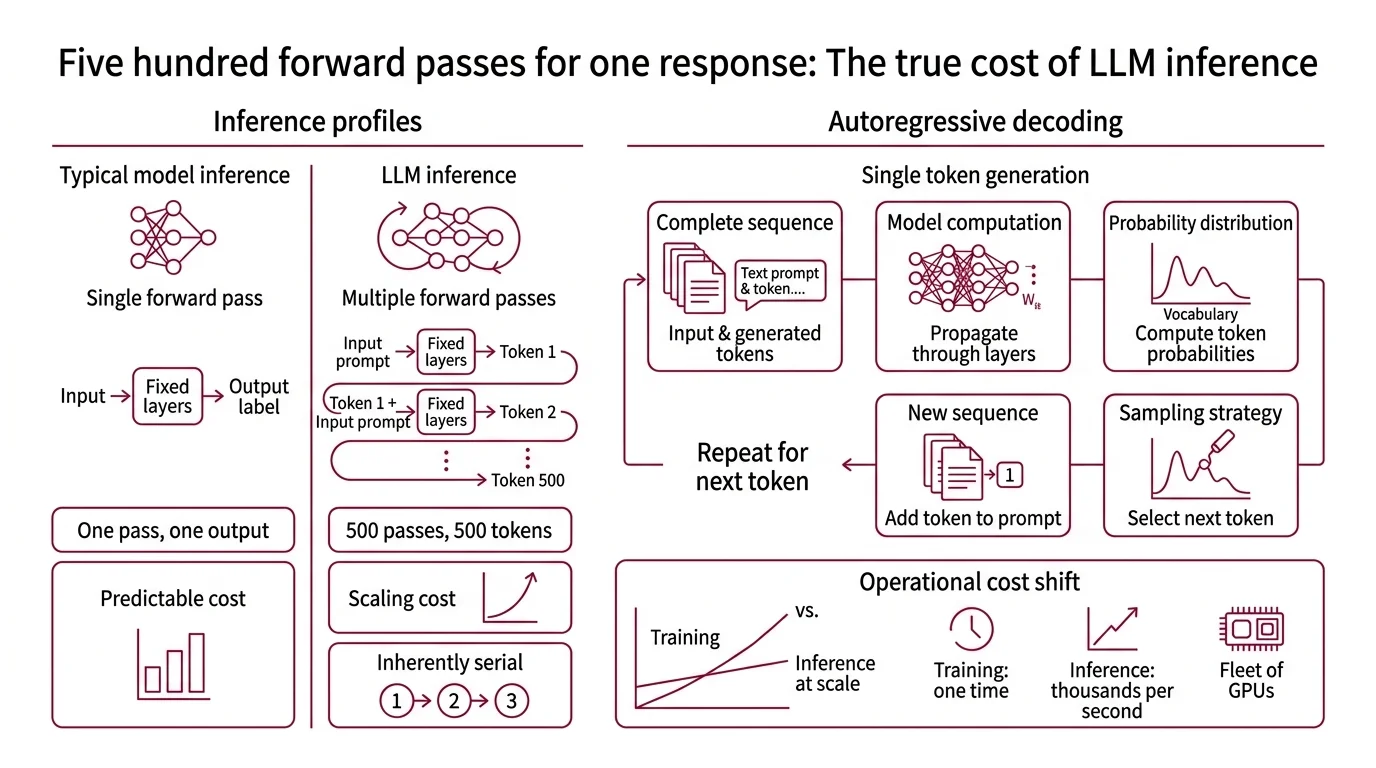
Training and inference occupy two different phases of a model’s existence, and they carry fundamentally different computational profiles. Training adjusts billions of parameters over thousands of iterations, processing massive batches of data in parallel across clusters of GPUs. Inference holds those parameters fixed and produces output from new input. In most neural network architectures — image classifiers, speech recognizers, recommendation engines — inference is the cheap phase. A single forward pass, a bounded cost.
Autoregressive language models reverse that assumption.
What is inference in machine learning?
Inference is the forward pass: input data propagated through layers of learned weights to produce an output. In an image classifier, one pass yields one label. In a speech-to-text system, a fixed-length audio window produces a transcript segment. The computational cost is predictable and proportional to input size.
LLMs break that predictability. A model generating a 500-token response doesn’t run one forward pass — it runs 500. Each pass produces a single token, conditioned on the full sequence of tokens generated before it. The cost scales with output length, and the steps are inherently serial: token 237 cannot begin until token 236 exists.
This is why inference, not training, dominates the operational cost of serving language models at scale. Training happens once per model version. Inference happens on every single request, thousands of times per second across a fleet of GPUs.
How does a large language model generate text token by token during inference?
The mechanism is autoregressive decoding. At each time step, the model takes the complete token sequence — the original prompt concatenated with all previously generated tokens — and computes a probability distribution over the entire vocabulary for the next position. A sampling strategy selects one token from that distribution: greedy decoding picks the most probable, top-k limits the candidate pool, nucleus sampling truncates at a cumulative probability threshold. The selected token is appended to the sequence. The loop restarts.
Each forward pass computes attention over the growing context. Without optimization, every step would re-read every prior token — a quadratic relationship between sequence length and compute. In practice, a mechanism called the KV cache stores the key-value attention pairs from previous positions, so each new step only computes the attention of the latest token against the cached history.
The KV cache converts a quadratic problem into a linear one. But it introduces a different pressure: memory. For a large model processing a batch of concurrent requests with multi-thousand-token contexts, the KV cache alone can consume tens of gigabytes of GPU RAM. The arithmetic logic units finish fast; they spend most of their time waiting for memory operations to deliver the cached data.
Not a compute bottleneck. A memory bandwidth bottleneck.
Filling the Dead Cycles
A single autoregressive sequence occupies a fraction of the GPU’s arithmetic capacity. While memory controllers shuttle KV cache entries between HBM and the compute cores, thousands of CUDA cores sit idle. The question that drives most inference optimization is deceptively simple: how do you fill those dead cycles without breaking the sequential dependency that each token needs the one before it?
How do batching and continuous batching improve LLM inference throughput?
Static batching groups multiple requests into a single operation. While one sequence’s forward pass waits on memory, another can proceed — the GPU’s parallel architecture means processing eight sequences costs only marginally more wall-clock time than processing one, because the bottleneck is memory transfer latency, not arithmetic throughput.
The problem with static batching is padding waste. Batch eight requests: the first completes in 50 tokens, the last needs 500. The first seven slots sit padded with zeros for hundreds of steps, occupying memory and compute lanes but producing nothing. Continuous Batching eliminates this: no slot waits for the slowest sequence. Each request exits independently, and a waiting query fills its place immediately. Under specific benchmark conditions, this architectural change achieved up to 23x throughput improvement over static batching (Anyscale Blog). Real-world gains depend on traffic patterns and sequence length distributions, but the principle is consistent: no GPU cycle goes unoccupied because one sequence finished early.
Memory management is the other half of the throughput equation. Standard KV cache implementations pre-allocate a contiguous memory block for each sequence’s maximum possible context length. A 4K-token window means every request reserves 4K tokens of GPU memory — even if it only generates 30. Prior serving systems wasted 60-80% of their KV cache memory on these unused pre-allocated blocks (PagedAttention paper).
Paged Attention, introduced by Kwon et al. at SOSP 2023, borrowed the operating system’s solution to exactly this kind of fragmentation. It stores KV cache in non-contiguous memory pages, allocated on demand as tokens are generated. A page table maps virtual cache positions to physical GPU addresses — the same mechanism an OS uses for virtual memory management. The result: under 4% memory waste and 2-4x throughput improvement over systems like FasterTransformer and Orca (PagedAttention paper).
vLLM, the open-source inference engine that implements PagedAttention as its default memory strategy, reached v0.18.0 as of March 2026 (vLLM GitHub). SGLang, following a similar architectural path, runs on over 400,000 GPUs and processes trillions of tokens daily at v0.5.9 (SGLang GitHub).
The Parallel Gambit and the Hardware Divergence
Batching and memory paging solve the throughput problem — moving more total tokens per second across many concurrent users. But the latency problem is a different beast. Time To First Token — the interval between request arrival and the first output token — is what the user actually feels, and it depends on how quickly the model can complete the initial prefill computation and begin generating.
Speculative Decoding attacks this by breaking the sequential constraint through parallel verification. A smaller, faster draft model proposes K candidate tokens in rapid succession. The full target model then verifies all K tokens in a single forward pass — the same cost as generating one token, but potentially accepting several at once. Under favorable conditions, this produces a 2-3x speedup while remaining mathematically lossless; the output distribution is identical to standard autoregressive sampling (BentoML Handbook). The limitation is structural: when the draft model’s token predictions diverge from the target’s distribution — common in code generation, formal proofs, and highly specialized domains — most candidates get rejected and the overhead of running two models exceeds the savings.
Quantization takes a different approach: reducing the precision of model weights from 16-bit floating point to 8-bit or 4-bit integers. Methods like GPTQ and AWQ achieve this with minimal perplexity degradation — smaller weights mean faster memory transfers and more room in GPU memory for larger batches or longer contexts. TensorRT-LLM, NVIDIA’s inference library at v1.2 stable as of March 2026, integrates quantization directly into its compilation pipeline.
Then there is the hardware divergence. Groq built the LPU (Language Processing Unit) on an entirely different premise: eliminate the memory bandwidth bottleneck by keeping the entire model in on-chip SRAM — 500 MB at 150 TB/s bandwidth, compared to the tens of TB/s typical of HBM-based GPU architectures (Groq Blog). The architecture is deterministic; inference latency does not vary between runs. Groq 3, announced at GTC in March 2026, is expected to ship late 2026 and is not yet commercially available.
Compatibility notes:
- vLLM V0 engine: Deprecated; scheduled for removal by end of June 2026. V1 has been the default since v0.8.0. Migrate before the removal deadline.
- TensorRT-LLM v1.0+: PyTorch is now the default backend, with several API renames (
cuda_graph_config,mixed_sampler, and others). Review migration notes before upgrading.
Where the Milliseconds Accumulate
The architecture of autoregressive inference creates predictable pressure points. Increase sequence length, and KV cache memory grows linearly while per-step attention cost rises — expect latency to climb and batch capacity to shrink. Scale batch size without continuous batching, and tail latency spikes because every request waits for the longest sequence in the group. Push quantization aggressively below 4-bit, and the perplexity envelope that holds at higher precision begins to tear — particularly for low-resource languages and domain-specific terminology at the margins of the training distribution.
The pattern across all of these: every inference optimization trades one resource for another. Memory for compute. Latency for throughput. Precision for capacity. The question is never which optimization is best; it is which trade-off matches the workload in front of you.
Rule of thumb: Profile memory bandwidth utilization before compute utilization — the former is almost always the binding constraint in autoregressive serving.
When it breaks: Speculative decoding degrades when draft and target models have low token-level agreement. In code generation and domain-specific workflows, rejection rates climb until the technique performs worse than standard decoding. PagedAttention’s memory advantage narrows when average sequence lengths approach the maximum context window — at that point, pages are nearly fully allocated regardless, and the paging overhead provides diminishing returns.
The Data Says
Inference is the phase that determines whether a trained model becomes a usable product or an expensive artifact gathering dust on a cluster. The core constraint — one token at a time, each waiting for the last — cannot be removed; it can only be disguised through batching, memory engineering, and speculative parallelism. Understanding which trade-off binds your specific workload is the difference between an inference stack that scales and one that stalls under its first real traffic spike.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors