What Is Model Evaluation and How Benchmarks, Metrics, and Human Judgment Measure LLM Quality

Table of Contents
ELI5
Model evaluation tests how well a large language model performs by running it through standardized benchmarks, computing automated metrics, and comparing outputs against human judgment. No single score captures the full picture.
A model scores 99% on a coding benchmark. Another hits 93% on a knowledge test spanning 57 academic subjects. Both numbers sound decisive — the kind of results that end arguments. Then you hand the first model a real codebase with dependency conflicts and watch it hallucinate an import that doesn’t exist. The score didn’t lie. It answered a narrower question than the one you thought you were asking.
The Wrong Mental Model for Quality
Most people treat model evaluation like a final exam. The model either knows the material or it doesn’t; a high score means competence, a low score means failure. This framing is comfortable and almost entirely misleading.
Model evaluation is closer to medical diagnostics than final exams. A blood panel doesn’t tell you whether a patient is “healthy” — it measures specific biomarkers under specific conditions. Change the conditions, and the readings shift. The patient hasn’t changed. The measurement instrument has.
The same model can appear brilliant under one evaluation framework and mediocre under another — not because the model transformed between tests, but because each benchmark measures a different slice of capability. Confusing a single slice with the whole is the foundational error that leads to bad model selection, wasted compute, and misplaced confidence.
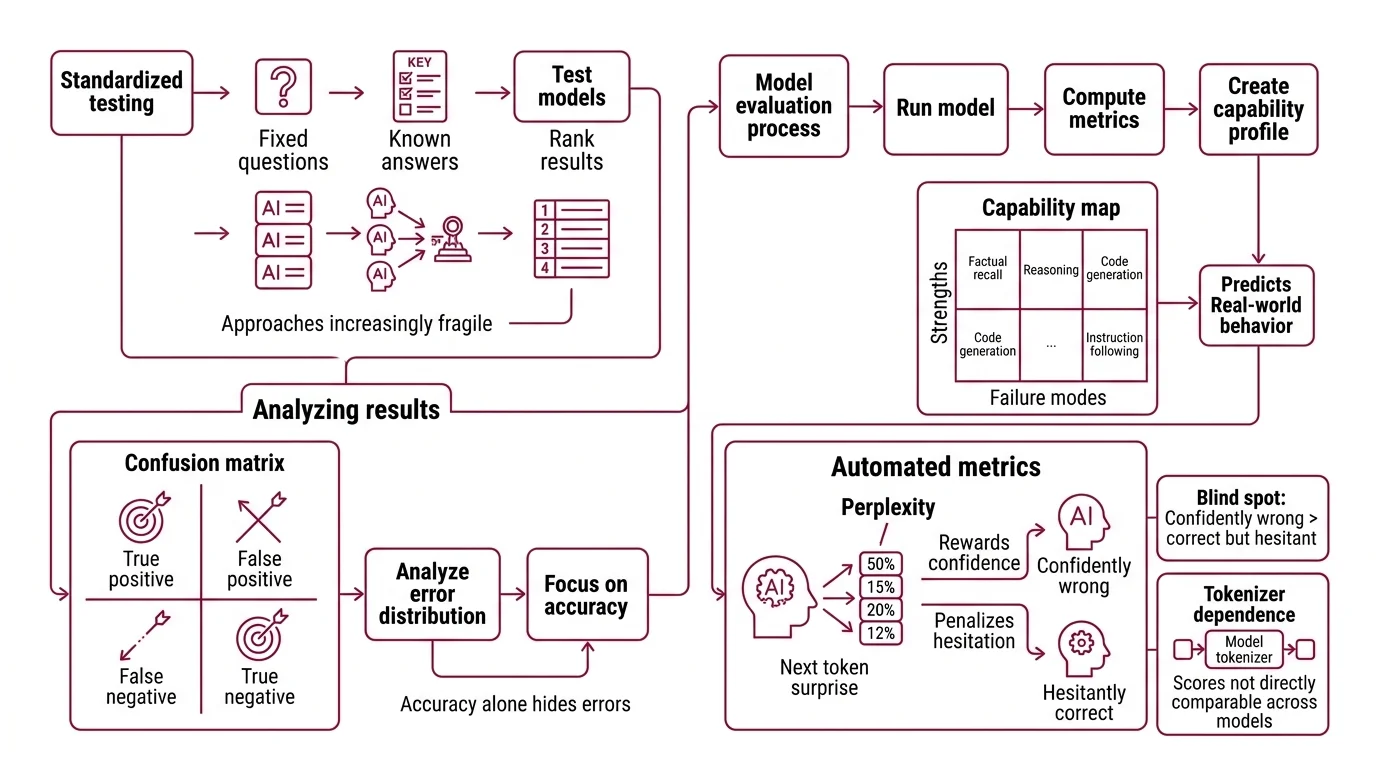
What Standardized Testing Looks Like for Neural Networks
The first generation of LLM benchmarks borrowed an idea from psychometrics: create a fixed set of questions with known answers, run every model through the same gauntlet, and rank the results. The approach is simple, reproducible, and increasingly fragile.
What is model evaluation for large language models
Model evaluation is the systematic process of measuring an LLM’s capabilities across defined tasks — factual recall, reasoning, code generation, instruction following — using a combination of static benchmarks, automated metrics, and human preference signals. The goal is not a single “intelligence score” but a capability profile: a map of strengths and failure modes that predicts real-world behavior.
In practice, this means running a model through hundreds or thousands of test cases where the expected output is known, then computing how often the model’s responses match. The Confusion Matrix captures the geometry of those hits and misses — true positives, false positives, true negatives, false negatives arranged in a grid that reveals not just whether the model failed, but how it failed. Accuracy is the ratio most people fixate on. But accuracy alone hides the distribution of errors; a model that scores 90% but fails systematically on one category of questions is a fundamentally different kind of 90% than one that fails at random.
Automated metrics like perplexity offer a complementary lens. Perplexity measures a model’s average surprise at the next token — lower values mean the model assigns higher probability to what actually comes next (Hugging Face Docs). But perplexity carries a blind spot: it rewards confident predictions and penalizes hesitant ones, regardless of correctness. A model that is confidently wrong may score better than a model that hedges toward the right answer. And because perplexity depends on the tokenizer, scores are not directly comparable across models that split text differently.
How do LLM benchmarks like MMLU and HumanEval measure model performance
Two benchmarks dominated LLM evaluation for years. Both are now showing their age.
MMLU — Massive Multitask Language Understanding — presents 15,908 multiple-choice questions across 57 subjects, from abstract algebra to professional medicine (Wikipedia). Created by Hendrycks et al. in 2020, it was designed to be hard. For a while, it was. Then frontier models crossed 88%, and the benchmark entered saturation territory. As of March 2026, GPT-5.3 Codex scores 93%. Artificial Analysis removed MMLU from their Intelligence Index in 2026, replacing it with MMLU-Pro for frontier comparisons. The original benchmark hasn’t disappeared, but for the models that matter most to practitioners, it no longer discriminates between them.
There’s an uglier problem beneath the saturation. An analysis found that approximately 6.5% of MMLU questions contain errors — wrong answer keys, ambiguous phrasing, questions where the designated “correct” answer is disputed (Wikipedia). When your measurement instrument has a 6.5% error floor, a model scoring above 93% is partly measuring its ability to agree with a flawed key. And because MMLU scores vary depending on which evaluation harness runs them — different implementations can produce different numbers for the same model — the third decimal place that separates two frontier models on a leaderboard may be noise rather than signal.
HumanEval takes a different approach entirely. OpenAI’s Codex team created 164 hand-crafted Python programming problems where the model must generate code that passes unit tests (DeepEval Docs). The metric — pass@k — asks whether at least one of k generated samples passes all test cases. It is elegant, concrete, and almost completely saturated. Frontier models score above 90%, with Kimi K2.5 Reasoning reaching 99% — though at that altitude, the distinction between genuine capability and Benchmark Contamination grows impossible to draw with certainty (llm-stats.com). BigCodeBench, presented at ICLR 2025 with 1,140 tasks across 139 libraries, is emerging as a successor designed for a world where 164 Python problems are no longer enough.
SWE Bench pushes further, testing models against real-world GitHub issues that require understanding full codebases. The gap between SWE-bench Verified and its contamination-resistant variant, SWE-bench Pro, is telling: top Verified scores reach around 81% while comparable Pro scores drop to the mid-40s, a spread that suggests the easier benchmark may have been compromised by data leakage (llm-stats.com). AntiLeak-Bench, published at ACL 2025, attempts to auto-construct tasks that resist contamination altogether — a sign the field has acknowledged the problem, even if it hasn’t solved it.
The Crowd, the Algorithm, and the Conflict of Interest
Static benchmarks test knowledge and capability against fixed answers. But language models increasingly do things where “correct” is a matter of judgment — summarizing, advising, explaining, persuading. For those tasks, the evaluator can’t be a lookup table. It has to be something that has preferences.
How does LLM-as-judge evaluation work compared to human evaluation
Chatbot Arena — originally LMSYS Chatbot Arena, rebranded as Arena under OpenLM.ai in January 2026 — took the radical step of making evaluation a popularity contest, and then making that contest rigorous. Users submit prompts to two anonymous models, then vote for the better response. Over six million votes later, the platform ranks models using a Bradley-Terry model that produces ELO Rating scores (Arena (OpenLM)). The rankings correlate surprisingly well with practitioner intuitions about model quality, which is either a validation of crowd wisdom or a reminder that intuition is also a bias.
The appeal is obvious: human preferences capture dimensions no static benchmark can — coherence, helpfulness, tone, the feeling that a response actually addresses what was asked. The vulnerabilities are equally specific. Preferences reflect the population that votes, and that population skews toward English-speaking technical users submitting the kinds of prompts that interest them. Researchers have also raised gaming and manipulation concerns — the possibility that model providers could influence rankings through strategic prompt submission. Whether Arena’s signal generalizes to a medical researcher in Nairobi or a legal analyst in Tokyo is an empirical question the platform hasn’t answered.
LLM As Judge evaluation sidesteps the crowd entirely by using one language model to evaluate another. The foundational work by Zheng et al. (NeurIPS 2023) demonstrated that GPT-4 as a judge achieved over 80% agreement with human preferences — matching the rate at which humans agree with each other (Zheng et al.). That number is simultaneously impressive and unsettling. Impressive because it means automated evaluation can scale beyond what human annotation budgets allow. Unsettling because matching human disagreement is not the same as matching truth.
The documented biases are specific and measurable: position bias (the judge prefers whichever response appears first), verbosity bias (longer responses score higher regardless of quality), and self-enhancement bias (a model rates its own outputs more favorably). Li et al. catalogued these in a 2024 survey spanning five evaluation perspectives — functionality, methodology, applications, meta-evaluation, and limitations. The biases don’t invalidate the method. They constrain where it can be trusted. An LLM judge evaluating factual accuracy operates under different failure modes than one evaluating creative writing — and conflating those contexts is how automated evaluation becomes automated self-deception.
What Evaluation Reveals and What It Conceals
The practical question isn’t whether benchmarks work. They do, within their scope. The question is whether you know the boundaries of that scope before you stake a decision on a number.
If a model scores highly on MMLU-Pro but your use case involves multi-step reasoning over domain-specific documents, the benchmark tells you the model has strong factual recall under controlled conditions. It tells you nothing about retrieval integration, context window management, or failure behavior under ambiguous instructions. The gap between benchmark performance and task performance is not noise — it is the distance between a controlled experiment and the field.
If you rely on Arena rankings to select a model, you are selecting for the preferences of Arena’s voting population. For general-purpose conversational quality, that signal is strong. For specialized domains — radiology, contract law, firmware debugging — the signal may be weak or misleading, because those domains are underrepresented in the prompt distribution.
Rule of thumb: Treat benchmark scores as filters, not as verdicts. A model that scores poorly on a relevant benchmark is probably weak in that area. A model that scores well might be strong — or might have memorized the test.
When it breaks: Evaluation fails most dangerously when the gap between benchmark conditions and deployment conditions is large and unexamined. A model optimized for benchmark performance can overfit to test formats, produce confidently wrong outputs on novel inputs, and present a capability profile that doesn’t transfer. The most dangerous evaluation failure isn’t a low score. It’s a high score that doesn’t generalize.
The Data Says
Model evaluation is a measurement problem, not a ranking problem. Benchmarks like MMLU and HumanEval provided early scaffolding for comparing models but are saturating under frontier performance. Human preference platforms like Arena capture dimensions that static tests miss but inherit the biases of the population that votes. LLM-as-judge scales evaluation but introduces systematic distortions that mirror — and sometimes amplify — human blind spots. The field is converging on multi-dimensional assessment, combining contamination-resistant tasks, calibrated human signals, and domain-specific harnesses, because no single number captures what “good” means for a model you’ll trust with real work.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors