What Is LLM-as-a-Judge and How One Model Scores Another's Outputs

Table of Contents
ELI5
LLM-as-a-judge uses one language model to score another model’s output — rating answers, comparing two responses, or grading against a rubric. It replaces slow human evaluation with fast, repeatable judgments that mostly agree with people.
Take two answers to the same question. Show them to a capable model, ask which is better, then swap their order and ask again. A meaningful share of the time, the verdict flips — same answers, different winner. Only the position in the sequence changed. The intuition that the model “reads both and decides” is wrong, and the way it is wrong tells you exactly how these graders work.
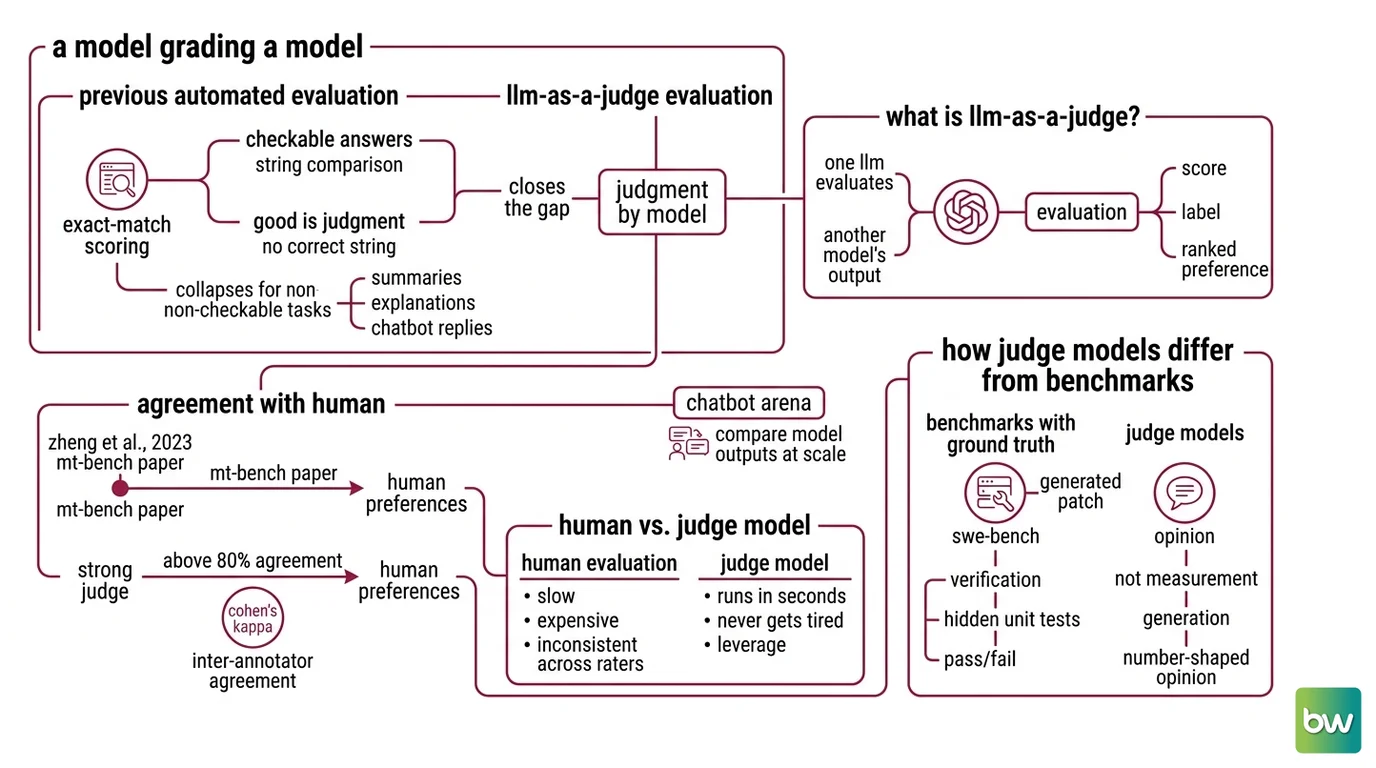
A Model Grading a Model
Automated evaluation used to mean exact-match scoring: does the output equal the gold answer, character for character? That works when a task has a checkable answer and collapses the moment “good” becomes a judgment rather than a string comparison. Summaries, explanations, chatbot replies, rewritten code with the same behavior — there is no single correct string to match against. LLM-as-a-judge closes that gap by handing the judgment itself to a model.
What is LLM-as-a-judge?
LLM-as-a-judge is the practice of using one LLM to evaluate the output of another model, producing a score, a label, or a ranked preference. The method was formalized in Zheng et al., 2023, in a paper whose title is its own joke: “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.”
The result that made people take it seriously was an agreement figure. In the original 2023 MT-Bench evaluation, a strong judge reached above 80% agreement with human preferences (Zheng et al.) — roughly the rate at which two human annotators agree with each other, a quantity measured with statistics like Cohen’s kappa and discussed under Inter Annotator Agreement. That figure is specific to that judge and that setup, not a constant you can assume for any model; a weaker judge agrees with humans far less often. The same lineage of work produced Chatbot Arena, where model outputs are compared at scale.
The appeal is leverage. Human evaluation is slow, expensive, and inconsistent across raters. A judge model runs in seconds and never gets tired. The catch is that it is not measuring anything the way a benchmark with Ground Truth does. On a task like SWE Bench, a generated patch either passes the hidden unit tests or it does not — that is verification. A judge offers an opinion shaped like a number.
Not measurement. Generation.
How does LLM-as-a-judge work to score another model’s output?
Mechanically, the candidate output is placed inside the judge’s prompt, alongside the original question and, optionally, a rubric describing what “good” means or a reference answer to compare against. The judge then does the only thing a language model ever does: it predicts the next tokens. Those tokens happen to spell a verdict — a score such as “4”, a label such as “Answer A is better”, or a structured form filled with sub-scores.
This is the part the intuition misses. The verdict is the continuation of a sequence, so it generates a verdict, not a measurement. Every token the judge emits is conditioned on the entire context: the question, the rubric, the candidate text, and crucially the order and length of what came before. Because generation is probabilistic, practitioners run judges at low Temperature And Sampling settings to make verdicts more reproducible, though never fully deterministic.
If this sounds familiar, it should. A judge model is a close relative of the Reward Model Architecture used in RLHF — both take an output and return a quality signal. The difference is that a reward model is trained on preference data to output a scalar, while an LLM judge is prompted to express its preference in words.
Three Ways to Ask “Which One Is Better?”
The seminal paper named three distinct scoring modes, and the choice between them changes what biases you inherit and what you can compute downstream. They are not interchangeable. Pick the mode that matches the question you are actually asking.
What are the components of an LLM-as-a-judge setup, like pointwise vs pairwise scoring and rubrics?
The three modes from Zheng et al. map cleanly onto three different questions:
| Mode | The question it answers | Output | Main weakness |
|---|---|---|---|
| Pointwise (single-answer grading) | How good is this one answer? | An absolute score, often 1–5 | Scores drift; the judge has no calibrated scale |
| Pairwise comparison | Which of these two answers is better? | A relative preference (A, B, or tie) | Sensitive to answer order |
| Reference-guided grading | How close is this answer to a known-good one? | A score anchored to a reference | Only works when a gold answer exists |
The component that does the real work in all three is the rubric: the written criteria that define quality for the task. A vague rubric (“rate the helpfulness”) produces a vague, drifting judge. A precise rubric — what counts, what disqualifies, how to weigh tradeoffs — is the actual specification the judge executes. Rubric design is where most of the engineering effort lives.
One method made rubrics rigorous. G-Eval, introduced by Liu et al. in 2023, prompts the judge to reason step by step using Chain-of-Thought, then fill in a score on a defined form. On summarization quality, G-Eval’s scores correlated with human ratings at a Spearman coefficient around 0.514 (G-Eval paper) — better than the older automatic metrics it replaced, and still far from a human-level correlation.
Pairwise comparison has a second use beyond picking a winner. Run enough head-to-head matches and the wins and losses can be aggregated into a ranking using the Bradley Terry Model or an ELO Rating, the same math that ranks chess players. That is how leaderboards turn thousands of individual A-versus-B verdicts — whether collected from human raters in tools like Label Studio or from a judge model — into a single ordered list.
Why Swapping Two Answers Flips the Verdict
So why does the opening anomaly happen at all? Because if a verdict is generated rather than measured, then anything in the context that shifts the probability distribution shifts the verdict — even when answer quality is held constant. The documented biases are not bugs bolted onto an otherwise objective process. They are the process, observed from the side.
Position bias is the clearest case. A systematic study across 15 judge models and more than 150,000 comparisons found that position bias is not random noise: the verdict tilts toward whichever answer occupies a particular slot, and the choice of judge model is the single largest factor in how strongly the effect shows up (arXiv 2406.07791). Verbosity bias is the next: longer, more elaborate answers tend to score higher even when the extra length adds nothing correct. And self-preference bias closes the loop — models tend to assign higher scores to outputs that resemble their own style, an effect documented at NeurIPS 2024 and found to grow stronger in larger models (arXiv 2410.21819).
Read those three together and the lesson is structural: a verdict is a sampled token, not an objective score. A judge can also be gamed the way any proxy metric can — pad the answer, mimic the judge’s preferred format, and the score rises without the quality rising, the evaluation-time cousin of Reward Hacking.
What This Predicts for Your Evaluation Setup
Once you treat the judge as a probability distribution rather than a referee, its failures become predictable — which means you can design around them.
- If you always present one answer first, expect position bias to inflate that slot’s win rate. Run each pair in both orders and average, or randomize order across the dataset.
- If your judge belongs to the same model family as one of the candidates, expect self-preference to tilt the result toward it. Use a judge from a different family, or compare both candidates against a neutral third.
- If your rubric rewards thoroughness without capping length, expect verbosity bias to reward padding. State a length expectation explicitly.
- If the task has a checkable answer — passing tests, exact match, a numeric result — a judge is the wrong instrument. Verify it instead.
Open-source frameworks like Deepeval, which ships a built-in G-Eval metric and has drawn more than 13,000 GitHub stars (DeepEval Docs), and TruLens package these patterns so you are not reinventing the prompt scaffolding each time.
Rule of thumb: Use an LLM judge for open-ended quality where no ground truth exists; for anything verifiable, verify it directly.
When it breaks: When the judge shares failure modes with the model it grades — the same blind spots, the same confident hallucinations — it rubber-stamps plausible errors instead of catching them, and agreement with humans collapses on exactly the hard cases you most needed checked.
The Judge Is Also a Contestant
There is a quieter consequence worth sitting with. Judge models increasingly feed their verdicts back into training, through reinforcement learning from AI feedback, where a model’s preferences shape the models trained after it. When the evaluator and the evaluated are drawn from the same distribution, their shared biases become inherited traits rather than averaging out. Self-preference, measured to intensify with scale, is precisely the kind of bias that compounds quietly across such a loop.
The Data Says
LLM-as-a-judge works because a strong judge’s preferences track human preferences closely enough to be useful, and it scales the way human evaluation never could. But it is generation wearing the costume of measurement: every verdict is a token conditioned on order, length, and style, not a reading off a fixed scale. Trust it where there is no ground truth to check against, design explicitly against its known biases, and never let it grade the cases it cannot see.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors