What Is Hybrid Search and How BM25 Plus Dense Vectors Beat Either Alone in RAG
ELI5
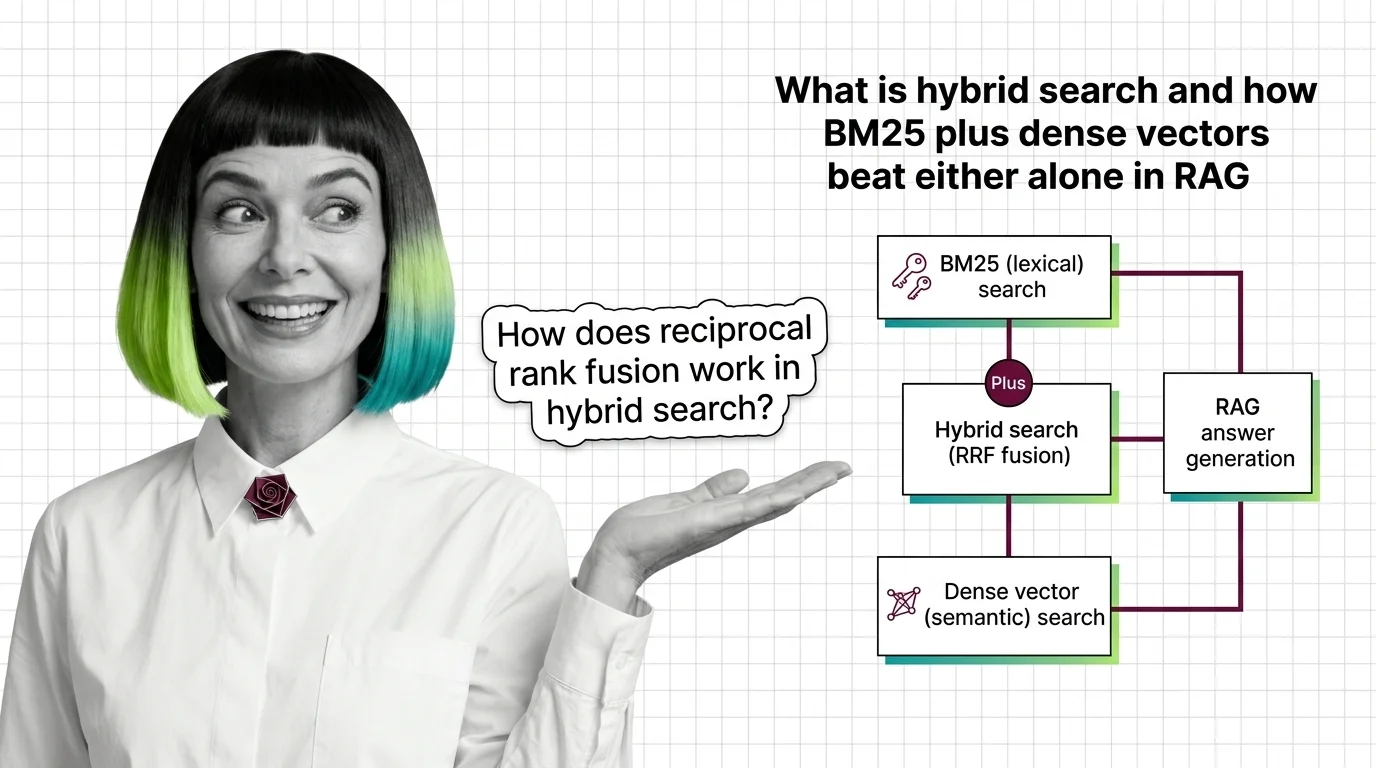
Hybrid search runs two retrievers in parallel: BM25 keyword search and dense vector search, then fuses the ranked results — usually with reciprocal rank fusion. It catches both exact tokens and meaning in a single pass, beating either retriever alone in RAG pipelines.
Type CVE-2025-12345 into a pure semantic search and watch the dense retriever return five tutorials about vulnerability management — none containing that exact string. Flip it: ask “how do attention heads route information?” against a pure keyword index, and you get every page containing the words “attention” and “route” regardless of meaning. The two retrievers fail in opposite directions — and that opposition is the structural reason hybrid search works at all.
Why Two Retrievers Fail in Opposite Directions
A Retrieval Augmented Generation pipeline is only as good as the documents it surfaces before generation begins. Get the wrong passages, and the model produces a fluent answer to a question you did not ask. The choice between BM25 and dense vector retrieval is not a matter of preference — it is a matter of which failure mode you are willing to tolerate.
What is hybrid search in RAG?
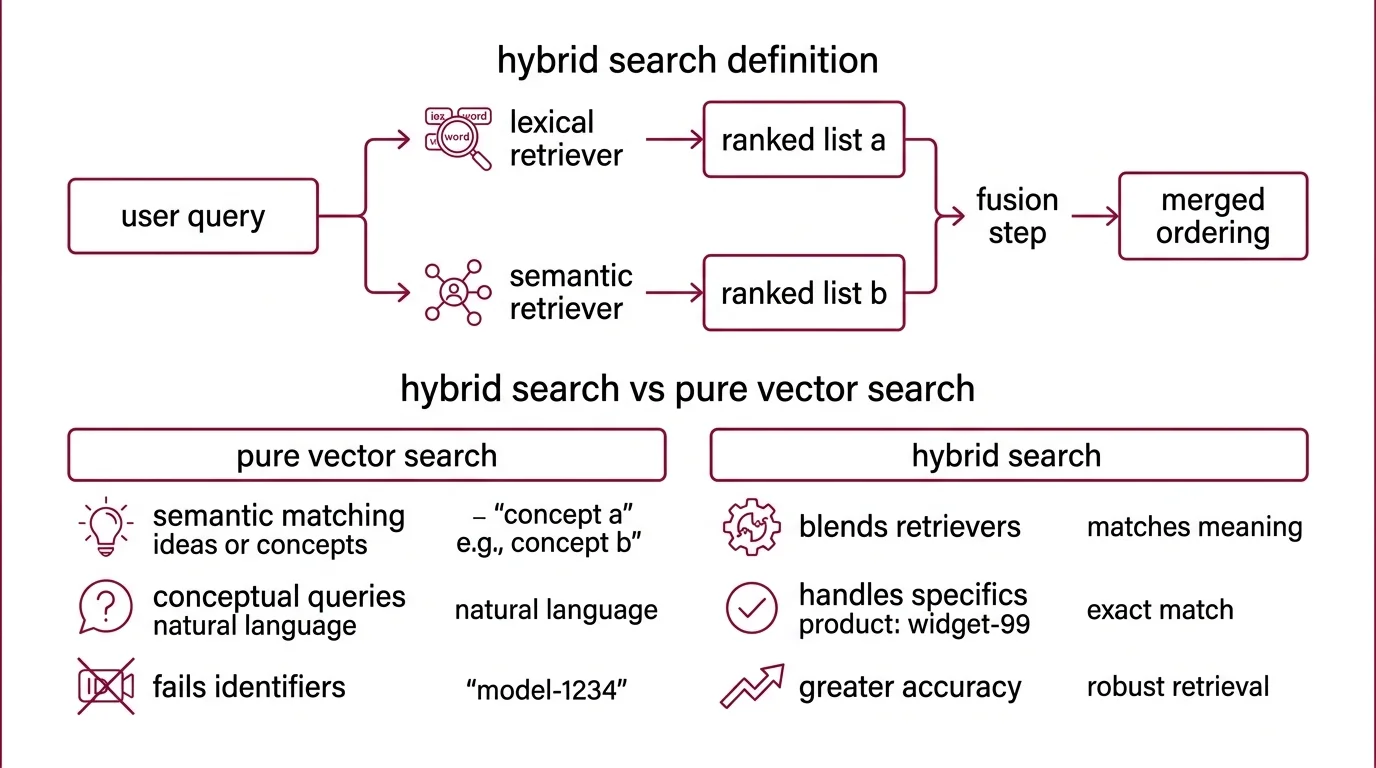
Hybrid search is a retrieval pattern, not a product. It runs a sparse lexical retriever — typically BM25, the probabilistic ranking function formalized at City University London by Robertson, Spärck Jones, and Walker as part of the Okapi system (Robertson & Zaragoza, 2009) — alongside a dense semantic retriever that embeds queries and documents into the same vector space. Each retriever produces its own ranked list. A fusion step then merges the two lists into a single ordering that gets passed to the LLM.
The implementations look different.
Vector Databases like Weaviate expose hybrid retrieval as a native query type with an alpha parameter that blends results across the two retrievers. Qdrant exposes it through a Universal Query API with server-side fusion.
Pinecone stores sparse and dense vectors together in a single index. Elasticsearch combines BM25 with a dense retriever through its RRF retriever construct (Elasticsearch RRF Reference). The pattern is the same in every case: two ranked lists, one fusion step, one final ordering.
What is the difference between hybrid search and pure vector search?
Pure vector search relies entirely on the embedding model. The query is encoded into a high-dimensional vector — typically 768 to 3072 dimensions — and the index returns documents whose vectors are closest by cosine similarity or dot product. This works beautifully for paraphrases, conceptual matches, and queries phrased in natural language. It fails on identifiers.
Try retrieving a document by its SKU, error code, function name, or legal citation. The embedding model compresses these tokens into a representation shaped by their context in training data, not by their literal characters. The query CVE-2025-12345 lands somewhere in the neighborhood of “security advisory” and “vulnerability” — and the actual page that contains the exact CVE may sit fifty positions down the ranked list because its embedding does not stand out from neighboring pages about similar CVEs.
BM25 has the inverse problem. It scores documents based on term frequency, document length, and inverse document frequency — a rigorously studied formula that emerged from decades of refinement to the Probabilistic Relevance Framework (Robertson & Zaragoza, 2009). It will find your CVE on the first try. But ask BM25 about “methods for retrieval-augmented generation” when the relevant document uses the phrase “grounding LLM responses in external knowledge,” and BM25 returns nothing useful — there is no token overlap.
Not redundancy. Complementarity.
The two retrievers are best at exactly the queries the other one is worst at, which is the structural fact every fusion strategy is trying to exploit.
How Ranks Become Scores Without Tuning Either
The naive approach to combining two retrievers is to add their scores. This is also the wrong approach. BM25 produces unbounded scores that depend on the corpus, while cosine similarity produces values bounded by [-1, 1] that depend on the embedding model. Adding them is like averaging Fahrenheit and Celsius and calling the result temperature.
The better approach treats ranks, not scores, as the primitive. Rank-based fusion ignores the magnitude of each retriever’s score and uses only the ordinal position of each document in its list. The most widely used instance of this idea is Reciprocal Rank Fusion.
How does hybrid search combine BM25 with dense vector retrieval?
The combination happens in two stages: parallel retrieval, then fusion. In the first stage, the query is sent to both retrievers simultaneously. BM25 scans an inverted index and returns the top-k documents by lexical match. The dense retriever encodes the query, runs an approximate nearest-neighbor search against the vector index, and returns the top-k documents by vector similarity. The two operations run in parallel, so the latency cost over a single retriever is small — measured in single-digit milliseconds against the half-second to multi-second cost of LLM inference downstream (supermemory.ai, Apr 2026).
The two ranked lists overlap by design but not by structure. A passage that mentions CVE-2025-12345 and discusses vulnerability management ranks high in both lists — that is the easy case. The interesting case is the document that ranks third in BM25 and forty-seventh in the dense retriever, or vice versa. These are the documents the fusion step has to decide about.
Each platform exposes this combination differently, but the operation is the same. Weaviate’s hybrid query takes an alpha parameter where alpha=1 is pure vector and alpha=0 is pure BM25 (Weaviate Docs). Pinecone uses sparse and dense vectors in a single index but requires the dotproduct similarity metric and offers no built-in alpha-style weighting — users must pre-weight the query vectors themselves before submission (Pinecone Docs). Milvus 2.5 and later support native BM25 through a sparse inverted index over an analyzed text field. The mechanism is identical. Only the API surface differs.
How does reciprocal rank fusion work in hybrid search?
Reciprocal Rank Fusion was introduced by Cormack, Clarke, and Buettcher in a 2009 SIGIR paper that evaluated fusion strategies on TREC retrieval datasets (Cormack et al., 2009). The formula is conspicuously simple:
score(d) = Σ 1 / (k + rank_i(d))
For each document d, sum across all retrievers i, take the reciprocal of (k plus the rank of d in retriever i), and add them up. The constant k is typically set to 60 — the value Cormack et al. recommended and the default adopted by Weaviate, Elasticsearch, and Qdrant (Elasticsearch RRF Reference). Documents that appear high in both lists accumulate the most reciprocal-rank score; documents that appear in only one list still contribute, but at a discount proportional to their position.
The elegance is in what RRF does not require. There is no score normalization, no temperature parameter, no cross-retriever calibration. The retrievers can produce wildly different score scales — BM25 returning unbounded floats, the dense retriever returning bounded similarities — and RRF treats them identically because it never looks at the scores. Rank is the only signal RRF trusts.
What RRF does require is parameter discipline at a different layer. The constant k acts as a smoothing parameter: small k aggressively rewards top-ranked documents and penalizes everything below; large k flattens the contribution across positions. Per-retriever top-k — how deep into each ranked list the fusion looks — also has to be chosen. The recommendation in vendor benchmarks is to leave k at 60 and tune the per-retriever top-k cutoff first, starting around 20 and raising it to 30 or 50 only when the corpus is large enough that important documents may sit deep in either list (supermemory.ai, Apr 2026).
What the Geometry of the Two Lists Predicts
Once you understand that BM25 and dense retrieval fail in opposite directions, the practical consequences fall out cleanly.
If your domain is rich in identifiers — SKUs, error codes, drug names, legal citations, function signatures — expect hybrid search to deliver the largest recall gains over either retriever alone. Vendor-reported benchmarks in 2026 measure recall@10 around 65% for BM25-only, 78% for dense-only, and 91% for hybrid (RRF) on standard RAG corpora (supermemory.ai, Apr 2026), though these are illustrative practitioner numbers, not peer-reviewed results.
If your corpus is dominated by paraphrase-heavy natural language — medical Q&A, customer support transcripts, conceptual documentation — the marginal lift from adding BM25 is smaller. The dense retriever already captures most of the signal, and BM25 contributes mainly a backstop for the rare query that pivots on a specific token.
If you index long documents, plan the Chunking Strategy around the index, not against it — sparse-dense indexes typically cap the number of non-zero values per sparse vector, which forces chunking or top-k pruning of sparse representations.
If you assume sparse retrieval means BM25, you will miss SPLADE. SPLADE is a learned sparse model — a BERT-derived neural network that produces sparse term-weighted representations rather than counting tokens. It is a sparse alternative to BM25 that competes on the same fusion terms but learns its weights end-to-end. Elasticsearch’s ELSER is a similar learned sparse encoder optimized for out-of-domain queries. The fusion mechanism does not care which sparse method produced the rank list — the contract is the rank, not how the rank was earned.
Compatibility notes:
- Weaviate BM25: BlockMax WAND is now the default keyword algorithm (GA in v1.30; experimental in v1.28). Score distributions can differ from the legacy WAND implementation, so old benchmarks may not reproduce on a current install.
- Pinecone sparse vectors: Hard limit of 1000 non-zero values per sparse vector. Long documents need chunking or SPLADE-style top-k pruning before indexing (Pinecone Docs).
- Elasticsearch RRF: Production RRF retriever requires an Elastic Enterprise license; the trial license enables full functionality. Commercial use without the license must fall back to client-side fusion or another retriever construct (Elasticsearch RRF Reference).
- Milvus full-text: Native BM25 only available from Milvus 2.5+. Older installations must use external sparse encoders or upgrade.
Rule of thumb: Run BM25 and dense retrieval in parallel, fuse with RRF at k=60, and tune per-retriever top-k before adding a reranker.
When it breaks: Hybrid search amplifies whichever retriever has the better signal for a given query — but it cannot rescue a fundamentally bad embedding model or a fundamentally noisy corpus. If both retrievers return mostly irrelevant passages, RRF produces a confident ordering of irrelevant results. The fusion step assumes at least one of the input lists is informative; when neither is, hybrid search fails silently rather than catastrophically, which is harder to debug than a clean miss.
The Data Says
Hybrid search is the consensus 2026 retrieval pattern for Agentic RAG and production RAG pipelines because the failure modes of BM25 and dense retrieval are structurally complementary, and Reciprocal Rank Fusion exploits that complementarity without requiring score normalization or cross-retriever calibration. The recall gain over either retriever alone depends on the corpus — domains rich in identifiers gain the most, paraphrase-heavy domains gain the least — but the latency cost of running both retrievers in parallel is small enough against LLM inference time that there is rarely a principled reason to choose one over both.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors