Human-in-the-Loop for AI Agents: How Approval Gates Work

Table of Contents
ELI5
Human-in-the-loop for agents is a control pattern: the autonomous AI pauses before risky actions and waits for a human to approve, edit, reject, or answer. The agent runs fast; humans gate the moves that would be costly to undo.
An agent built to triage support tickets cleared a long backlog in minutes, then closed a paying customer’s account because the email body matched a refund template. The autonomy worked exactly as designed; the consequences did not. Recovery took longer than the autonomy had saved. The fix was not a smarter model — it was a pause.
The Geometry of a Paused Agent
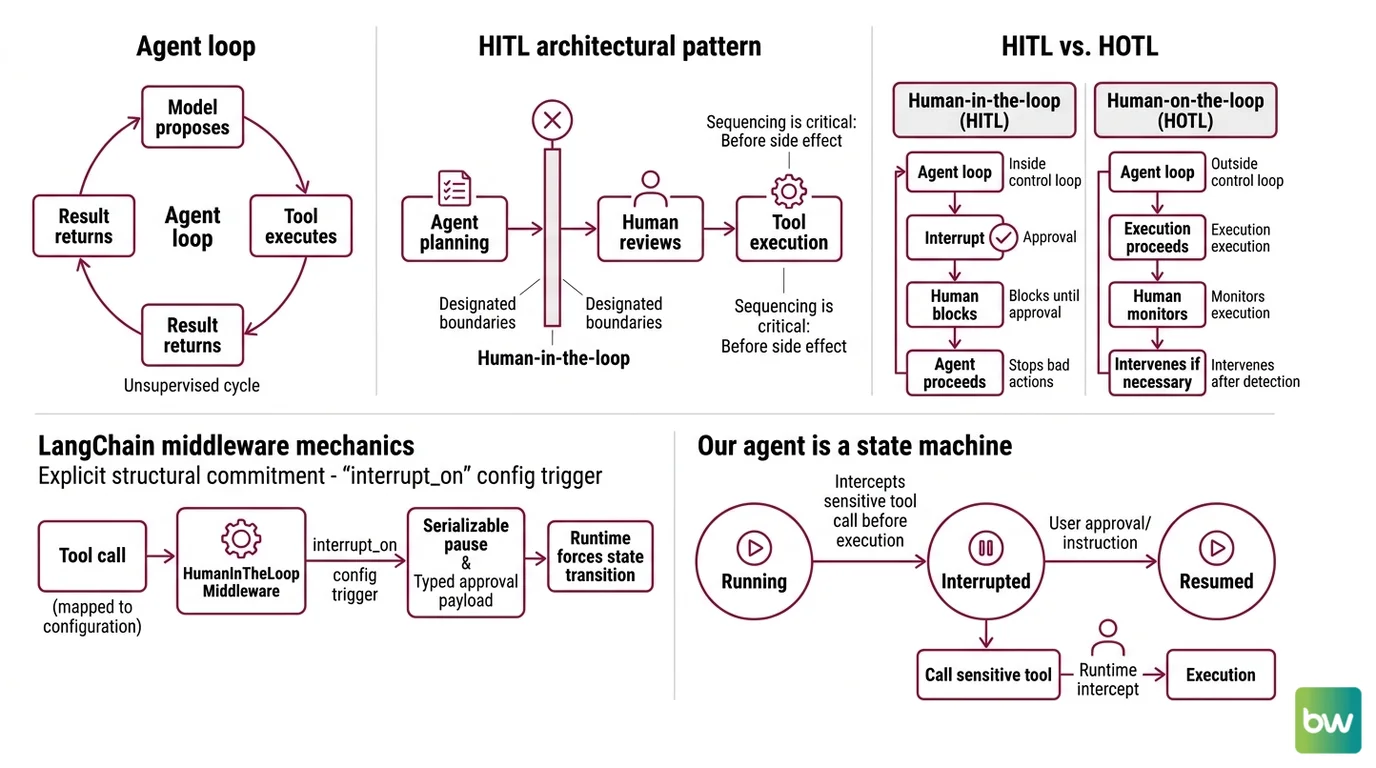
An agent loop is a feedback cycle. The model proposes, a tool executes, the result returns, the model proposes the next step. That loop runs without supervision — and that is the engineering choice that creates both the speed and the failure surface. Human-in-the-loop is not an extra check bolted onto the loop; it is a controlled discontinuity inside it.
What is human-in-the-loop for AI agents?
Human-in-the-loop for AI agents is the architectural pattern that interrupts the agent’s planning–acting cycle at designated boundaries and hands control to a person. The interrupt happens before the side effect, not after. That sequencing is the entire point: if the human reviews after the agent has written the file, sent the message, or executed the SQL, the system is no longer human-in-the-loop. It is human-after-the-fact.
The terminology is precise. Anthropic distinguishes HITL — where the human is inside the control loop and the agent blocks until approval — from HOTL, human-on-the-loop, where the human monitors execution and intervenes only when something looks wrong (Anthropic Research). Both are forms of oversight; only one stops bad actions before they happen.
LangChain’s HumanInTheLoopMiddleware makes the structural commitment explicit: any tool call mapped to the middleware’s interrupt_on configuration triggers a serializable pause and a typed approval payload (LangChain Docs). The agent isn’t asking nicely. The runtime is forcing a state transition.
Not paranoia. Architecture.
How does human-in-the-loop work in agent workflows?
The mechanics are easier to see if you stop thinking of the agent as a chatbot and start thinking of it as a state machine.
The state machine has three positions: running, interrupted, resumed. While running, the agent calls tools, reads outputs, and plans the next step. When it tries to call a tool that has been marked sensitive, the runtime intercepts the call before execution and emits a structured interrupt object. The agent is now suspended — its memory, its plan, and the pending tool call all serialized to durable storage.
A human reviewer looks at the interrupt and chooses one of four canonical responses, codified in LangChain’s primitives (LangChain Docs):
approve— execute the call exactly as proposed.edit— execute the call with modified arguments.reject— skip the call and inject an explanation back into the agent context, so the model can re-plan.respond— answer the agent directly; the human’s reply is treated as if it were the tool’s response.
The shape of these four decisions matters. approve and edit are accept paths with different fidelity. reject hands control back to the model with a reason. respond short-circuits the tool and lets a human substitute domain knowledge that no API can return. Each one is a different correction signal, and an agent system that exposes only “approve / deny” is missing two-thirds of the design space.
OpenAI’s Agents SDK takes the same pattern and adds an important property: durability. Tools declare needsApproval, the run pauses when one is encountered, and the runtime returns a RunState that can be serialized to a string and rehydrated later (OpenAI Agents SDK Docs). The server can shut down between the agent asking and the human answering. The state survives. That detail is what makes HITL practical in real workflows where humans don’t always reply within seconds.
The end of an interrupt is a resumption: the runtime injects the human’s decision into the agent context and the loop continues from exactly where it stopped. No reset. No replay. Same conversation, same plan, with one tool call’s worth of human signal added.
What Sits Inside the Gate
A pause without infrastructure is just a wait. The components that turn an interrupt into an approval gate that actually gates are well-mapped, both in production frameworks and in the engineering literature on agent oversight. Every working system needs a way to detect hazardous actions before execution, a way to route human signal back into the loop, and a way to constrain the action set in the first place.
What are the core components of a human-in-the-loop agent system?
Five interacting pieces compose a working gate. Strip any one and the gate either fails to trigger, fails to wait, fails to read the human’s intent, fails to give the human enough information to decide, or fails to translate the decision back into action.
A risk classifier on the action surface. Not every tool call deserves a human. Reading a public document doesn’t. Sending an email to a customer does. The classifier — sometimes a hard-coded allowlist, sometimes a model-based judgment — decides which actions trigger an interrupt. Anthropic’s Claude Code uses an action classifier as the second of two defenses, after a server-side prompt-injection probe filters tool outputs before they enter the agent context (Anthropic Engineering). Layer one decides what the agent is allowed to read; layer two decides what it is allowed to do.
A serializable suspension primitive. The runtime needs to freeze the agent’s reasoning state and survive a process restart. LangGraph ships interrupts as a first-class API; OpenAI’s RunState.toString() and RunState.fromString() do the same in JavaScript (OpenAI Agents SDK Docs). Without serialization, HITL only works for synchronous flows where a human responds in seconds — a tiny fraction of real review workloads.
A typed decision schema. Approve, edit, reject, respond — or whatever discrete vocabulary the platform commits to. The schema must be machine-readable, because the runtime has to translate the human’s decision into either a tool execution, a tool result, or a new model turn. Free-text approvals turn the gate back into prose.
An approval surface for the human. The reviewer needs to see the proposed action, the arguments, the agent’s stated reason, and ideally the upstream context that produced the call. If the reviewer cannot see why the agent wants to do this, the gate degrades into rubber-stamping — which is what happens when oversight workflows are designed for compliance theater rather than judgment.
A resumption hook. The decision flows back into the agent’s context and the loop continues. The hook also writes audit trails: who approved, what the proposed action was, what the modified action ended up being. This is where Agent Evaluation And Testing gets its training data — every resolved interrupt becomes a labeled example that future classifiers and policies can learn from.
The five components compose. Different frameworks build the same five pieces with different APIs, but the structural picture is invariant: classifier, suspension, schema, surface, hook.
The Geometry of Approval
What this architecture actually predicts:
- If you set every tool to require approval, throughput collapses and the human stops reading. Approval fatigue is real, and the EU AI Act explicitly does not require a human to review every AI decision before it takes effect — only that humans retain the ability to monitor, intervene, and halt (EU AI Act Guide). Universal approval is not regulation; it is bad engineering.
- If you set no tool to require approval, the agent’s failure mode becomes its action surface. Any tool with side effects becomes a possible incident.
- If you set approval at the right boundary — typically tools that touch external state, money, or customer-visible communication — the agent’s productivity is preserved and the human reviews the small subset of actions where their judgment is the difference between a good and a costly outcome.
The boundary is the design decision. The classifier — whether allowlist, model, or a Agent Guardrails layer wrapping the action surface — is where the team’s risk tolerance gets encoded into the agent’s runtime.
Rule of thumb: Trigger an interrupt where reversibility ends. Approve cheap-to-undo actions automatically; gate the ones whose side effects survive the response.
When it breaks: Approval gates fail when reviewers cannot see the agent’s reasoning, when interrupts arrive faster than humans can read them, or when the runtime cannot durably suspend long enough for a real review to happen — at which point the system either rubber-stamps approvals or silently degrades into HOTL.
HITL Is Not One Thing
The same word covers two architectures with different guarantees, and the distinction maps directly to regulatory intent.
HITL — true in-loop oversight — blocks until a human responds. The agent cannot proceed; the human’s decision is part of the execution path. This is the regime that satisfies the strongest reading of EU AI Act Article 14, which requires that designated humans retain the ability to understand outputs, intervene without managerial approval or technical workaround, and halt the system in real time (EU AI Act Guide).
HOTL — human-on-the-loop — runs the agent autonomously and exposes the execution to a monitor. The human watches, intervenes when something looks wrong, and signs off after the fact. The agent does not stop on its own; the oversight is reactive.
Both are valid. They sit at different points on a tradeoff curve between throughput and pre-emptive safety. The NIST AI Risk Management Framework’s agentic profile organizes the choice dynamically across four functions — GOVERN classifies the autonomy tier, MAP catalogs tools and their action consequences, MEASURE tracks runtime behavioral metrics, and MANAGE handles agent-compromise incident response (CSA Agentic NIST Profile). The oversight level isn’t a fixed property of the system. It’s a parameter set by risk and policy, adjusted as the agent earns or loses trust.
A team that has built HOTL but reports it as HITL is not lying. It is conflating two architectures whose only difference is whether the gate blocks. That difference is the entire safety story.
The Data Says
Approval gates work because they restore a property the agent loop quietly removes — the inability of the system to complete an irreversible action without a human being part of the causal chain. The four decision types are not UI choices; they are the discrete signal channels through which human judgment is encoded into runtime behavior. Strip the suspension primitive, the typed schema, or the classifier, and the gate stops gating.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors