What Is GraphRAG? Multi-Hop Reasoning with Knowledge Graphs

Table of Contents
ELI5
GraphRAG builds a Knowledge Graph from your documents — entities as nodes, relationships as edges — then uses graph structure plus community summaries to answer questions that vector search alone cannot reach.
Ask a vector-RAG system to surface the dominant themes across an entire dataset and the failure mode is consistent. It returns whichever chunks look most similar to the word “themes,” then summarizes those as if they spoke for the whole corpus. The failure isn’t a bug. It’s a structural consequence of what cosine similarity can and cannot see.
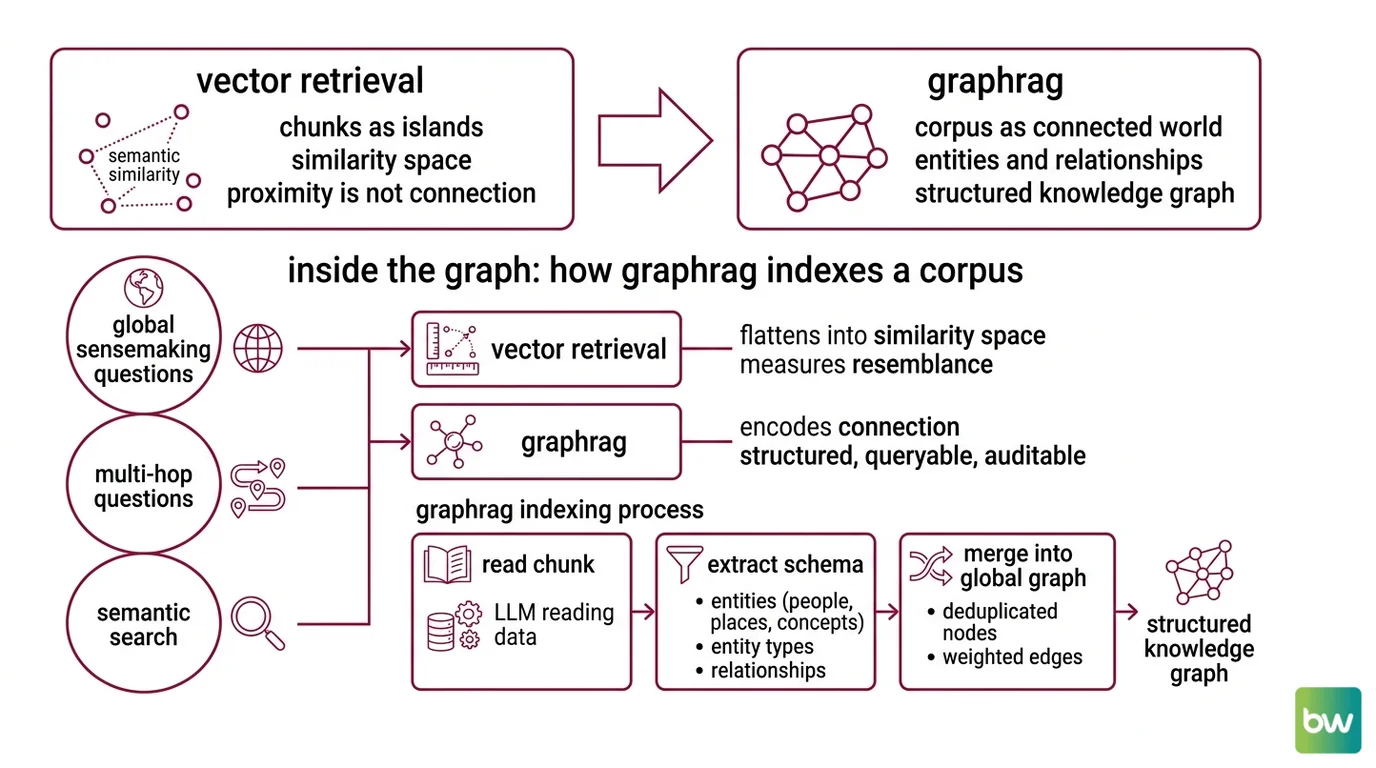
Inside the Graph: How GraphRAG Indexes a Corpus
Vector retrieval treats each chunk as an island in a high-dimensional similarity space. GraphRAG treats the corpus as a connected world — characters, places, concepts, and the relationships between them — built before any user types a query. The indexing phase is where the real work happens; retrieval, by comparison, is cheap.
What is GraphRAG and how do knowledge graphs work in retrieval-augmented generation?
GraphRAG is a retrieval-augmented generation pipeline that replaces or augments flat embedding-based retrieval with a structured Knowledge Graph extracted from the source corpus. Instead of asking “which chunks are semantically nearest to this query?” the system asks “which entities does this query touch, and what is the local and global neighborhood of those entities in the graph?”
The original framing comes from Edge et al. at Microsoft Research, who introduced GraphRAG as a way to handle “global sensemaking” questions that span an entire corpus rather than a single passage (arXiv:2404.16130). The motivation is geometric. Vector retrieval flattens everything into similarity space, where relationships between entities — who reports to whom, which protein binds to which receptor, which character betrayed which other — collapse into proximity. Proximity is not connection.
Vectors measure resemblance; graphs encode connection. That distinction is the whole article in one sentence, and it is the reason multi-hop questions fall through a vector index but settle naturally onto a graph one.
A knowledge graph for RAG is typically built by an LLM that reads each chunk and extracts a small schema: entities (people, places, concepts, products), their types, and the relationships between them. Each extraction is then merged into a global graph with deduplicated nodes and weighted edges. The output is structured, queryable, and — crucially — auditable in a way that an embedding index is not.
What are the core components of a knowledge graph RAG system: entity extraction, graph store, and community summaries?
Three parts of the system do different work.
Entity and relationship extraction is the entry point. An LLM reads each chunk and emits structured triples — (Mona, employed_by, BestAIWeb), (BestAIWeb, hosts, AI Pipeline). The model also writes short descriptions of each entity and each relationship, which become the basis for later summarization. Quality of the entire system is bounded by the quality of this step; ambiguous extraction here propagates silently through every retrieval downstream.
The graph store is where the extracted nodes and edges land.
Neo4j is the production-grade home most teams reach for, with a
Cypher Query Language traversal layer that lets you ask questions like “find all documents within two hops of entity X” directly against the graph rather than against an embedding index. The official neo4j-graphrag Python package wraps this pattern and supports vector, fulltext, hybrid, and Cypher-based retrievers in a single library (Neo4j GraphRAG Python docs).
Community summaries are the GraphRAG-specific innovation. The system runs a community detection algorithm over the graph to find clusters of densely connected nodes, then asks an LLM to write a natural-language summary of each cluster. Microsoft GraphRAG uses the Leiden algorithm — an improvement on Louvain that avoids returning disconnected communities — applied recursively, so you get a hierarchy: small communities at the base level, super-communities at the next level, and so on (Microsoft GraphRAG Docs). The Leiden choice is documented in the Microsoft implementation, not in the original arXiv paper.
What you end up with is two retrieval surfaces glued to the same graph: the entities themselves, and the multi-resolution summaries of how those entities cluster.
Reaching the Answer: From Communities to Multi-Hop Queries
The graph is built. Someone types a question. What now?
How does GraphRAG combine community detection and hierarchical summarization to answer multi-hop questions?
Microsoft GraphRAG distinguishes two query modes — “local” and “global” — and the difference matters because they exploit different parts of the same graph (Microsoft GraphRAG Docs).
Local search is the entity-anchored mode. The system identifies which entities the query mentions, fetches their neighborhoods up to a fixed number of hops away, and feeds the resulting subgraph plus the corresponding text chunks to the LLM. This is the mode that delivers Multi-Hop Reasoning: the model can see the path from “drug X” to “metabolizing enzyme Y” to “patient phenotype Z” because that path is a literal walk on the graph, not a guess made from embedding distances. Vector retrieval has no notion of “walk” — only of nearness — and that is why it tends to surface either X or Y or Z but rarely the chain that connects them.
Global search is the sensemaking mode — the one vector RAG cannot do well. The system performs a map-reduce over the community summaries. Each community is asked the user’s question independently, partial answers are scored and reduced, and a final synthesis is generated from the survivors. Because community summaries already compress thousands of entities into a few paragraphs, the query touches the entire corpus without dragging the entire corpus into the prompt.
The empirical finding from Edge et al. is that, on global sensemaking questions over corpora of roughly one million tokens, this approach substantially improves answer breadth and diversity compared with conventional vector-RAG baselines. The single most important consequence is structural: the work moves from query time to indexing time, which is why GraphRAG can reason over a whole corpus without a million-token context window.
The trade-off is that everything depends on how well the graph was extracted. A vector index is forgiving — a missing relationship just means a slightly worse top-k result. A knowledge graph is brittle — a missing edge means an entire reasoning path does not exist.
Not a softer signal. A deleted one.
What the Graph Predicts
Once you understand that GraphRAG is moving compute from query time to indexing time, several practical predictions fall out:
- If your queries are mostly fact lookups inside a single document, GraphRAG will not pay back its indexing cost — vector search is cheaper and roughly as accurate.
- If your queries cross many documents and require connecting entities, expect local search to outperform vector RAG by a wide margin on multi-hop questions.
- If your queries ask about themes, patterns, or summaries across the whole corpus, vector RAG will give you confident-sounding but partial answers; global GraphRAG will give you something closer to the truth, at materially higher token cost.
- If you re-extract the graph every time a chunk changes, your bill will grow non-linearly. Tools like LightRAG target this case explicitly, supporting incremental updates without full re-index (LightRAG paper, arXiv:2410.05779).
Rule of thumb: Reach for GraphRAG when answers must traverse relationships, not when they only need to retrieve passages.
When it breaks: GraphRAG degrades sharply when the underlying knowledge graph is incomplete — missing edges silently delete reasoning paths, and the BRINK benchmark (EACL 2026) showed that knowledge-graph RAG methods lose significant accuracy under incomplete-knowledge conditions. The system never tells you what it could not see.
Compatibility & maturity notes:
- Microsoft GraphRAG is labeled a “demonstration”, not an officially supported Microsoft product — the repository states this explicitly. Suitable for research and prototypes; production use means you own the operations.
- Major version migrations. The v2.x → v3.x bump introduced output data model changes, and
settings.yamlschema can shift between minor versions. Microsoft recommends runninggraphrag initafter any upgrade (Microsoft GraphRAG breaking-changes).- Cost behavior. Indexing makes one LLM call per chunk for entity and relationship extraction, plus per-community summarization calls. Specific dollar costs are model- and configuration-dependent; assume they are non-trivial and benchmark on a representative slice before committing.
The Data Says
GraphRAG works because it pays its compute up front, in a phase the user never sees, and turns retrieval from a similarity search into a graph walk. The mechanism is documented and reproducible (Edge et al., Microsoft Research). The frontier is no longer “should we extract a graph?” but “how do we keep the graph correct as the corpus changes — and how do we know when it isn’t?”
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors