What Is Fine-Tuning and How Gradient Updates Adapt Pre-Trained LLMs to Specific Tasks
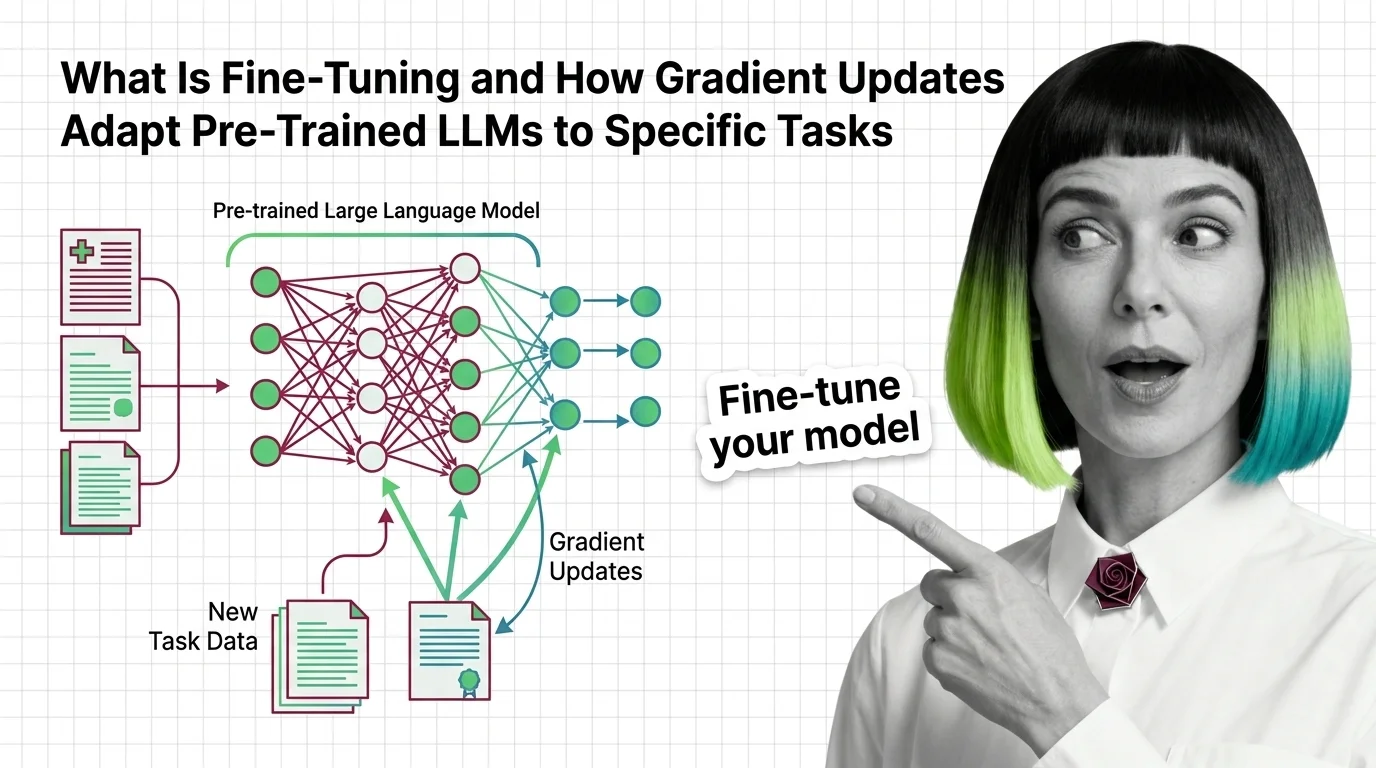
Table of Contents
ELI5
Fine-tuning takes a pre-trained language model and adjusts its internal weights on a smaller, task-specific dataset — teaching it new behavior through targeted gradient updates, without rebuilding the model from scratch.
A model trained on a trillion tokens of internet text can write Shakespearean sonnets, explain quantum entanglement, and generate working Python functions. Ask it to output your company’s five-field JSON schema for medical records — consistently, without hallucinating extra fields — and it stumbles.
Not a knowledge problem. A behavioral one.
The model has seen JSON. It has seen medical terminology. What it hasn’t learned is that your schema matters more than its own preferences about what a record should look like. Fine-tuning closes that gap — not by injecting knowledge, but by adjusting which outputs the model treats as correct.
How Small Gradients Reshape a Giant Model
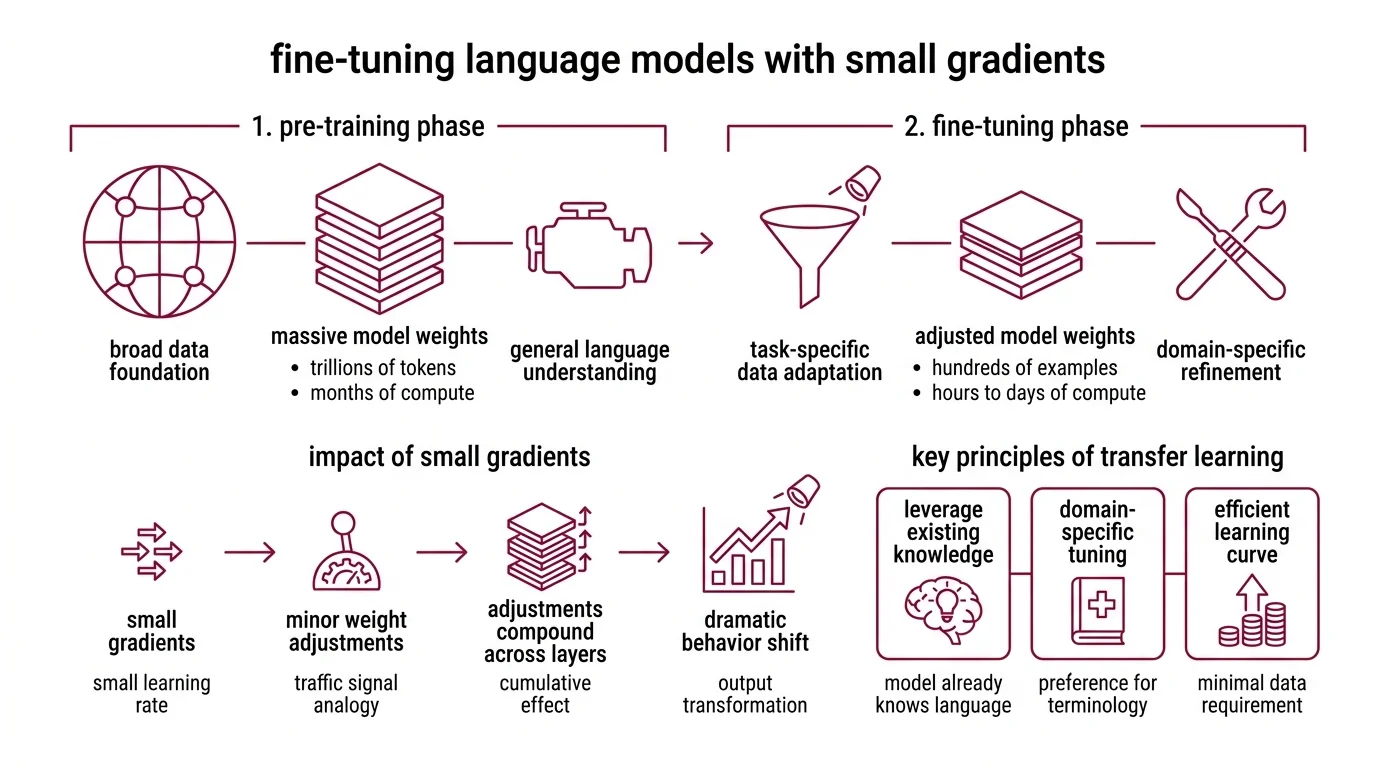
Think of a pre-trained model as a city with millions of roads already paved. Pre-training built those roads — it established the connection patterns between every token the model can produce. Fine-tuning doesn’t build new roads. It adjusts the traffic signals so that certain paths carry more traffic and others go quiet.
The gradient updates during fine-tuning are tiny compared to what pre-training required; the Learning Rate is typically one to two orders of magnitude smaller. But those adjustments compound across layers, and the cumulative effect on output behavior can be dramatic.
What is fine-tuning a large language model
Fine-tuning is the process of continuing a pre-trained model’s training on a narrower, task-specific dataset. The model starts with weights acquired during pre-training — months of compute on trillions of tokens — and adjusts those weights through additional rounds of Supervised Fine Tuning.
This is Transfer Learning in its most direct form: general capabilities developed on broad data get refined for a specific domain. The model doesn’t forget how to construct English sentences when you fine-tune it on medical text — it learns to prefer medical phrasing, structure, and terminology over generic alternatives.
At minimum, you need surprisingly little data. OpenAI’s fine-tuning API accepts as few as 10 examples, though 50-100 produce more reliable results (OpenAI Docs). The asymmetry is stark: pre-training consumes trillions of tokens over weeks of compute, while fine-tuning can meaningfully shift behavior with a dataset measured in hundreds.
Why so few? Because the model already knows the language. Scaling Laws predict that pre-training performance improves as a power law with compute, data, and parameters — and fine-tuning inherits that entire foundation. It teaches which register to use, not how to speak.
The misconception that fine-tuning injects new knowledge is persistent and wrong. The model’s factual knowledge is bounded by pre-training. What fine-tuning changes is how the model prioritizes and formats its outputs — which patterns it amplifies and which it suppresses.
How does fine-tuning change the weights of a pre-trained model
The mechanics are the same as any gradient-based optimization, but the context changes everything.
During fine-tuning, the model processes task-specific examples and computes a loss — the distance between what it predicted and what the training data expected. That loss propagates backward through the network, producing gradients: a direction and magnitude of change for each weight.
The learning rate is decisive here. Too high, and the gradients overwrite pre-trained representations — the model forgets what made it useful in the first place. Too low, and the weights barely shift; the model stays stubbornly general. Typical fine-tuning learning rates sit between 1e-5 and 5e-5, roughly a tenth of what pre-training used.
Each training step nudges millions of weights simultaneously. The effect is not a dramatic rewiring — it’s a statistical tilt. The probability distribution the model samples from shifts so that domain-relevant outputs become more likely and generic outputs fade.
Geometrically, the model’s representations occupy a high-dimensional space shaped by pre-training. Fine-tuning rotates and stretches small regions of that space so that task-relevant inputs land closer to task-relevant outputs. The global structure — the model’s general language ability — stays largely intact.
Three training methods shape how the loss gets computed:
- SFT — labeled input-output pairs, the most direct approach
- RLHF — adds a reward model trained on human preferences, optimizing for outputs humans judge as helpful
- DPO — skips the reward model and optimizes directly from preference pairs, reducing pipeline complexity
OpenAI’s gpt-4.1 family supports all three — SFT, DPO, and reinforcement fine-tuning (OpenAI Docs).
The weight changes are small in absolute terms. But after fine-tuning, the model’s latent space has been gently warped — not demolished and rebuilt, but tilted toward the geometry your task requires.
The Low-Rank Shortcut That Changed the Economics
A reasonable question follows: if fine-tuning touches millions of weights, doesn’t it demand the same GPU resources as pre-training?
It would — if you updated all of them.
Parameter Efficient Fine Tuning sidesteps this by updating only a small fraction of the model’s parameters while freezing the rest. The most influential method is LoRA (Low-Rank Adaptation), introduced by Hu et al. in 2021. LoRA decomposes weight updates into two small matrices whose product approximates the full-rank update.
The reduction is absurd: 10,000x fewer trainable parameters and 3x less GPU memory compared to full fine-tuning on a GPT-3-scale model (Hu et al.). The model barely notices the constraint.
QLoRA, published by Dettmers et al. at NeurIPS 2023, pushed the boundary further. By quantizing frozen weights to 4-bit precision using NormalFloat (NF4) and applying LoRA adapters on top, QLoRA made fine-tuning a 65-billion-parameter model possible on a single 48GB GPU (Dettmers et al.). Three innovations collapsed the hardware barrier: 4-bit NormalFloat quantization, double quantization, and paged optimizers.
The cost gap tells its own story. An 8B open-source model costs roughly $0.48 per million training tokens on hosted platforms; GPT-4o fine-tuning runs $25 per million training tokens (PricePerToken). More than 50x separates API-dependent from self-hosted fine-tuning — and gpt-4.1-specific pricing may differ from these figures, as aggregator data for the newest models lags behind releases.
The Hugging Face PEFT library — v0.18.1 as of January 2026 — has become the de facto standard for open-source parameter-efficient methods, supporting LoRA, QLoRA, AdaLoRA, DoRA, and others (HF PEFT Docs). The range of PEFT variants is evolving rapidly; DoRA is emerging as a recommended default over vanilla LoRA, though specific performance advantages remain version-dependent.
Compatibility notes:
- OpenAI gpt-4o/gpt-4o-mini fine-tuning: New customers must initiate fine-tuning before March 31, 2026 — after this date, new fine-tuning access for these models closes (OpenAI Deprecations). Existing fine-tuned models remain usable. The gpt-4.1 family is the current recommended target for new projects.
What the Gradients Tell You and Where They Lie
If you have a clear, repetitive output format — structured reports, classification labels, consistent tone — fine-tuning will likely outperform prompt engineering. The gradient updates encode the pattern directly into the model’s weights rather than relying on in-context examples that consume your token budget every inference call.
If your task depends on recent or proprietary information absent from pre-training data, fine-tuning alone won’t solve it. The model’s factual knowledge is fixed at training time; fine-tuning adjusts behavior, not facts. For knowledge-dependent tasks, retrieval-augmented generation is typically more appropriate — though the optimal approach depends on the specific use case and the nature of the knowledge involved.
If you reduce your training data to a dozen highly specific examples and train for too many epochs, expect the model to memorize rather than generalize. This is Overfitting in its classic form — and it is easier to trigger with fine-tuning than with pre-training because the dataset is so small relative to the model’s capacity.
If you push the learning rate too high or train for too long, Catastrophic Forgetting degrades general capabilities. The fine-tuning gradients overwrite pre-trained representations so aggressively that the model loses abilities outside your fine-tuning distribution.
What distinguishes a good fine-tuning dataset from a bad one is not size — it’s signal density. Each example must clearly demonstrate the input-output relationship you want the model to internalize. Ambiguous labels or inconsistent formatting produce conflicting gradients that pull the weights in contradictory directions. The model averages them, and the result is mediocre at everything rather than excellent at anything.
Rule of thumb: Fine-tune for behavior; retrieve for knowledge.
When it breaks: Catastrophic forgetting and overfitting are the twin failure modes. A model fine-tuned on a few hundred legal contracts may produce excellent contract clauses — but lose coherent general conversation. The failure is silent: you won’t notice until a user asks something outside your training distribution.
The Data Says
Fine-tuning is not knowledge injection — it is behavioral calibration. The gradient updates are small, the datasets are small, and the effect is precisely targeted: the model learns which outputs to favor, not which facts to store. Parameter-efficient methods have collapsed the hardware barrier to the point where a single consumer GPU and a few hundred curated examples can meaningfully reshape how a billion-parameter model behaves. The hard question was never whether fine-tuning works — it’s knowing when the model needs new behavior versus new information.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors