What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
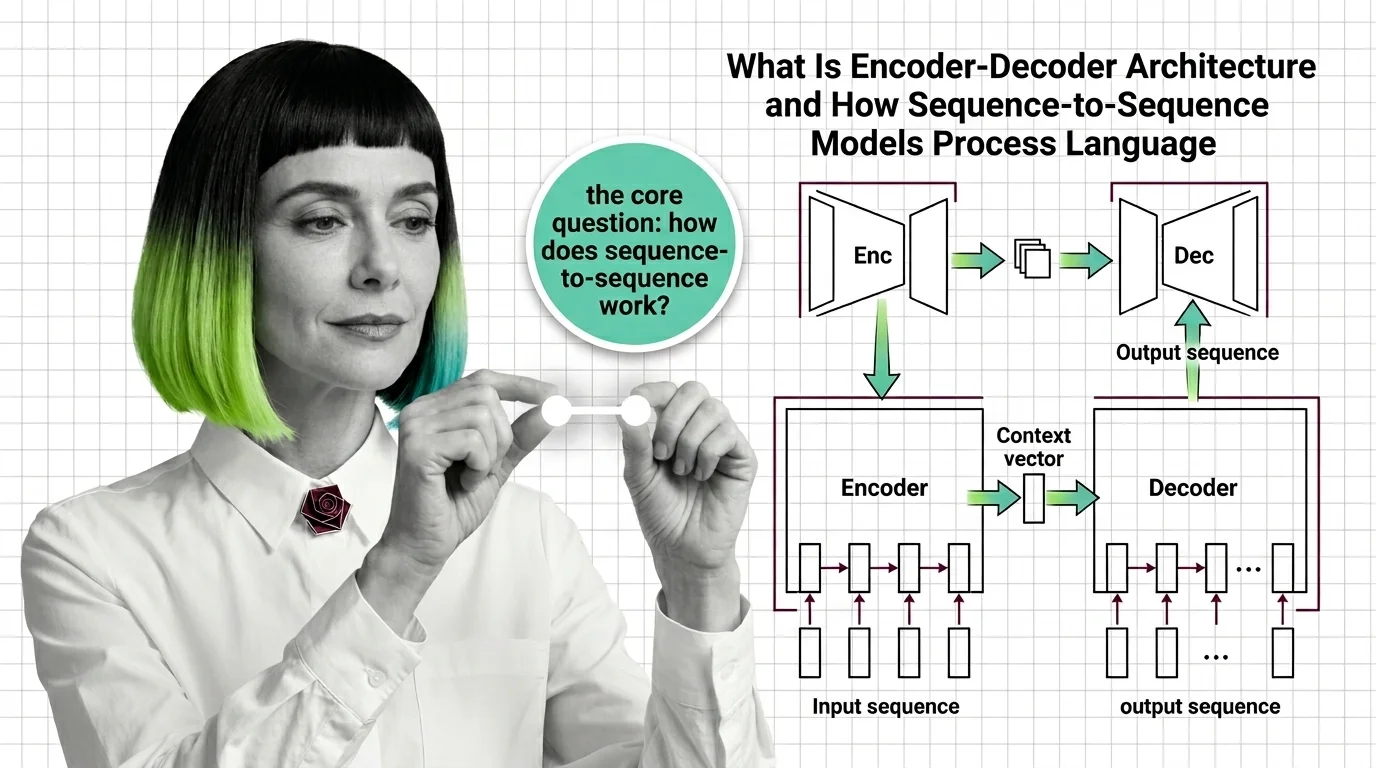
Table of Contents
ELI5
Encoder-decoder architecture splits a neural network into two halves: one reads the input and compresses it into a fixed representation, the other generates output from that compressed point — one token at a time.
In 2014, two research teams — working independently, publishing months apart — demonstrated something that should have failed quietly. They fed variable-length sentences in one language into a neural network, compressed the entire meaning into a single fixed-dimensional vector, and reconstructed coherent sentences in a completely different language on the other side. The information loss should have been catastrophic. It wasn’t.
That improbable compression is the founding trick of encoder-decoder architecture. Understanding why it works — and exactly where it breaks — is the key to understanding how modern sequence-to-sequence models process language.
The Architecture Built on a Lossy Bet
The intuition is deceptively simple: reading is a different skill from writing, so assign each to a separate network. But the real engineering insight is what connects them — a fixed-dimensional vector that must carry every relevant feature of the input across to the other side.
What is encoder-decoder architecture in deep learning?
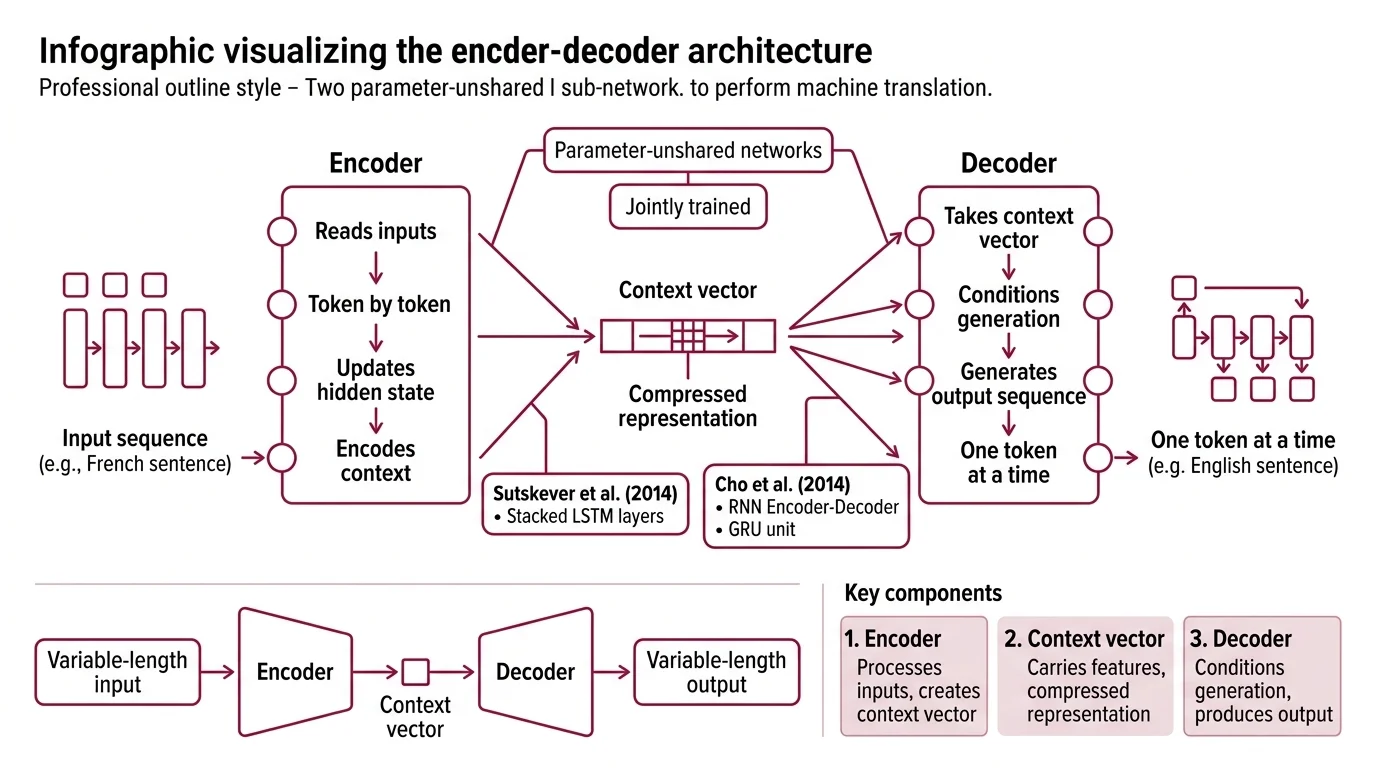
Encoder-decoder architecture is a neural network design pattern where two distinct sub-networks collaborate on a sequence transformation task. The encoder reads an input sequence — a sentence in French, say — and produces a compressed internal representation. The decoder takes that representation and generates an output sequence — the same sentence in English — one token at a time.
The critical detail: the encoder and decoder do not share parameters. They are trained jointly but operate as separate functions. The encoder maps variable-length input into a fixed-length Context Vector, and the decoder conditions its generation on that vector.
Not a single network learning everything. Two specialists, each trained for half the problem.
Sutskever, Vinyals, and Le formalized this in 2014 using stacked LSTM layers for both encoder and decoder (Sutskever et al.). In parallel, Cho and colleagues introduced the RNN Encoder-Decoder framework along with the GRU unit — a lighter recurrent cell that achieves similar expressiveness with fewer parameters.
The architectural pattern was a convergent discovery: a natural consequence of trying to handle variable-length input and output — a problem that fixed-size feedforward networks simply could not address.
What are the main components of an encoder-decoder neural network?
Three components define the classical encoder-decoder.
The encoder processes the input sequence token by token, updating a hidden state at each step. In recurrent variants, the final hidden state becomes the context vector. In Transformer Architecture variants, the encoder produces a full sequence of hidden states — one per input token — using bidirectional self-attention. The encoder sees every position simultaneously; no information is masked.
The decoder generates the output sequence autoregressively. It receives the context representation from the encoder and produces tokens one at a time, feeding each generated token back as input for the next step. In recurrent decoders, Teacher Forcing during training means the decoder receives the correct previous token rather than its own prediction — stabilizing gradient flow at the cost of a train-test distribution mismatch. In transformer decoders, causal masking ensures each position can only attend to earlier positions.
The bridge between them is what changed most dramatically over time. In the original design, a single fixed-length vector carried everything. In the Attention Mechanism design introduced by Bahdanau et al. in 2015, the bridge became a dynamic weighted sum over all encoder hidden states — allowing the decoder to focus on different parts of the input at each generation step (Bahdanau et al.).
That shift — from static bridge to dynamic bridge — turned out to be more consequential than any change to the encoder or decoder themselves.
How Sequences Cross the Bottleneck
Understanding the components explains what the architecture contains. Understanding the data flow explains why it works — and why the original version eventually cracked under pressure.
How does an encoder-decoder model convert input sequences into output sequences?
The conversion happens in three phases, and the mathematics of each phase reveals why encoder-decoder models can handle inputs and outputs of completely different lengths.
Phase 1: Encoding. The input sequence is processed to produce a set of hidden representations. In an RNN encoder, this means sequentially updating a hidden state at each time step. The final state becomes the context vector. In a transformer encoder, all positions are processed in parallel through layers of self-attention and feedforward networks, producing a matrix of contextualized representations.
Phase 2: Bridging. The context representation crosses from encoder to decoder. In the original seq2seq model, this was the bottleneck — literally. One vector, fixed dimensionality, carrying the entire input regardless of whether that input was three words or thirty. The transformer design sidesteps this by passing the full encoder output matrix to the decoder through cross-attention at every layer (Vaswani et al.).
Phase 3: Decoding. The decoder generates tokens sequentially. At each step, it computes a probability distribution over the vocabulary conditioned on the context and all previously generated tokens. The chosen token is selected via greedy search, Beam Search, or sampling. Beam search maintains multiple candidate sequences in parallel, trading computation for output quality.
The critical constraint: the decoder never sees future tokens. It generates left-to-right, each decision permanent once made. A wrong early token warps the probability landscape for everything that follows — which is why decoding strategy matters as much as model capacity.
What should you learn before studying encoder-decoder architecture?
The architecture sits at an intersection of several foundational concepts, and understanding them in advance prevents the common mistake of memorizing the diagram without grasping the dynamics.
The context vector is the central abstraction — the compressed handoff between encoder and decoder. Without understanding what it carries and what it loses, the rest of the architecture is a black box.
Attention mechanisms transformed the architecture from a fixed-bottleneck design to a dynamic-access design. The 2017 transformer paper replaced recurrence entirely with self-attention and cross-attention layers — six encoder layers and six decoder layers, each containing multi-head attention and feedforward sub-networks (Vaswani et al.).
Teacher forcing explains how the decoder trains efficiently despite generating tokens sequentially. Beam search explains how the decoder generates good outputs at inference time despite the left-to-right constraint. And transformer architecture itself is the modern instantiation of the encoder-decoder pattern — where the original RNN-based design was the prototype.
Each concept locks into the others. Skip one, and the architecture feels like memorized notation rather than understood machinery.
When the Fixed Vector Stopped Being Enough
The original encoder-decoder worked. But it worked the way a photograph of a painting works — you get the composition, and you lose the brushstrokes.
Bahdanau et al. demonstrated that the fixed-length context vector was a genuine information bottleneck. As input sentences grew longer, translation quality degraded because the encoder was forced to compress increasingly complex meaning into the same number of dimensions. Their solution — attention — allowed the decoder to compute a weighted combination of all encoder hidden states at each generation step, giving the decoder direct access to the full input at every output position.
Not a minor improvement. A categorical shift in what the architecture could represent.
The transformer formalization in 2017 took this further. Cross-attention between decoder queries and encoder key-value pairs replaced the recurrent bridge entirely. The encoder’s bidirectional self-attention captures input context without the sequential bottleneck of RNNs. The decoder’s causal self-attention maintains the autoregressive property. And cross-attention connects them — each decoder layer asking: which parts of the input matter for the token I am about to generate?
This is the architecture behind T5, Google’s text-to-text encoder-decoder spanning 60 million to 11 billion parameters and treating every NLP task — translation, summarization, question answering — as a sequence-to-sequence problem (Raffel et al.). It is the architecture behind BART, Meta’s denoising encoder-decoder that proved equally strong at comprehension and generation — matching RoBERTa-level understanding while pushing summarization quality beyond prior benchmarks (Lewis et al.).
Why Decoders Inherited the Earth
Here is the uncomfortable pattern: encoder-decoder models won the architecture, then lost the scaling race.
Decoder-only models — GPT-4o, Claude, Llama 3 — dominate general-purpose language modeling as of 2026. The encoder-decoder design persists in specialized sequence-to-sequence tasks like translation and summarization, but the largest models in production are autoregressive decoders with no encoder at all.
The reason is partly economic and partly geometric. An encoder-decoder with 2N total parameters uses roughly the same compute as a decoder-only model with N parameters — a rough heuristic, not a formal benchmark result (Yi Tay). At smaller scales, encoder-decoder models can be more efficient — a smaller T5 outperformed the 62-billion-parameter PaLM-1 on certain tasks because the encoder’s bidirectional attention captures richer input representations than a causal mask permits (Yi Tay). But at the largest scales, the flexibility and simplicity of decoder-only training has dominated.
If you are choosing an architecture for a task where input and output are distinct sequences with different structures — machine translation, document summarization, speech-to-text — encoder-decoder remains the more natural fit. The encoder’s bidirectional processing captures input features that a causal decoder must infer indirectly.
If you are choosing an architecture for open-ended generation, instruction following, or tasks where the boundary between input and output is ambiguous — decoder-only models offer a simpler training pipeline and scale more predictably.
Rule of thumb: When the input is a structured artifact and the output is a transformation of it, the encoder-decoder separation is an architectural advantage. When the task is “continue this text,” the encoder adds complexity without proportional benefit.
When it breaks: The classical fixed-vector encoder-decoder fails on long sequences because the context vector cannot represent fine-grained positional information beyond its dimensionality. Even attention-based encoder-decoders degrade when input length exceeds the attention mechanism’s context window — quadratic memory scaling in standard self-attention means that doubling the input length quadruples the memory requirement.
The Data Says
Encoder-decoder architecture formalized a structural insight that survived every paradigm shift since 2014: reading and writing are separable computations bridged by a compressed representation. That insight carried the design from LSTMs through attention to transformers — and it remains the foundation for every task where input and output are genuinely distinct sequences. The architecture did not disappear. It specialized, while decoder-only models claimed the general case.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors