How OCR, Layout Analysis, and VLMs Turn PDFs Into Clean Text
Table of Contents
ELI5
Document parsing turns PDFs, scans, and images into clean, structured text a language model can actually read. It does this in stages: detect the layout, recognize the characters, reconstruct tables, and rebuild reading order — so meaning survives the conversion.
A PDF looks like a document. It behaves like a drawing. Open one in a hex editor and you will not find paragraphs — you will find positioned glyphs, vector strokes, and embedded images, none of which know they belong together. Most Retrieval Augmented Generation failures that get blamed on the model started here, in the silent gap between what the file contains and what the file appears to contain.
This is a tour of how that gap gets closed, and where it quietly does not.
A PDF Is a Layout Drawing Dressed Up as a Document
The first thing a parser has to confront is that a PDF was never designed for reading. It was designed for printing. Every glyph carries a coordinate, every figure carries a bounding box, but the reading order — the sequence in which a human eye would actually traverse the page — is not stored anywhere. Two-column layouts, footnotes, sidebars, and tables are all just regions sharing space on a canvas. The structure exists in the reader’s head, not in the file.
Document parsing is the engineering discipline that reconstructs that missing structure. A formal definition from the field-defining survey: document parsing transforms unstructured and semi-structured documents — PDFs, images, scans — into structured, machine-readable representations for downstream tasks like RAG and knowledge base construction (Document Parsing Unveiled, arXiv).
That sentence hides a tower of sub-problems.
What is document parsing and extraction in AI pipelines?
In the retrieval-augmented-generation stack, document parsing is the layer that sits between raw files and Chunking Strategy. The layers above — embedders, retrievers, rerankers — assume their input is text with semantic boundaries. Paragraphs that mean something. Tables that retain rows and columns. Headings that mark sections. Document parsing is the discipline that produces that input.
It is best understood as the inverse of typesetting. Where a typesetting engine takes structured content and renders it as a layout, a parser takes a layout and recovers the structure that produced it. The information lost in the forward direction — semantic hierarchy, table topology, reading order — has to be rebuilt from visual evidence alone.
When this layer is sloppy, every downstream component inherits the damage. A chunker cannot find paragraph boundaries that no longer exist. An embedder cannot encode the meaning of a table that has been flattened into a stream of disconnected numbers. A retriever returns matches, but the matches reference content that was destroyed before it ever reached the index. The model is then accused of hallucinating, when in fact the Embedding it indexed was already incoherent.
The mechanism isn’t mysterious. It is just upstream.
How a Page Becomes Structured Text
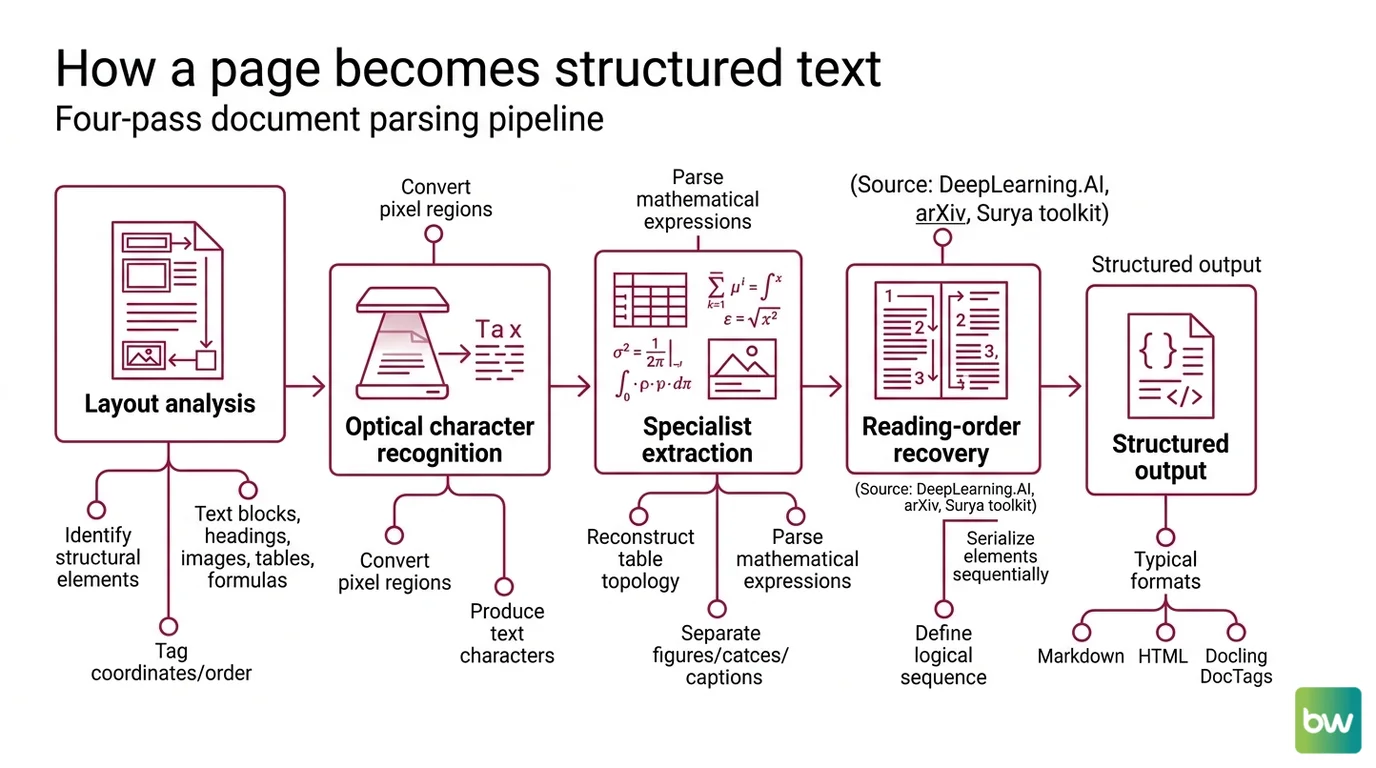
A document parsing pipeline reads a page the way a forensic analyst reads a crime scene: layer by layer, evidence first, interpretation after. The order of the operations matters, because each stage depends on the boundaries the previous stage drew.
How does document parsing convert PDFs and images into structured text?
The classical recipe runs in four passes.
First comes layout analysis. A computer-vision model identifies structural elements on the page — text blocks, headings, images, tables, formulas — and tags each with spatial coordinates and a reading order (DeepLearning.AI Document AI course). This is the structural foundation for everything that follows. If the layout model misses a sidebar, every later stage will treat the sidebar’s content as part of the main column.
Second comes optical character recognition. OCR converts the pixel regions identified by layout analysis into machine-readable text characters (Document Parsing Unveiled, arXiv). Modern OCR models handle dozens of scripts, multiple fonts, and mild distortion. The Surya toolkit, for example, covers more than 90 languages with a unified OCR-plus-layout-plus-reading-order stack.
Third comes specialist extraction. Tables get reconstructed into row-and-column topology. Mathematical expressions get parsed into LaTeX or MathML. Figures get separated from captions. These are different problems with different models because a table is not a paragraph and a formula is not a sentence — the inductive biases that work for one fail for the others.
Fourth comes reading-order recovery. The page elements get serialized into the sequence a human reader would follow: title, then abstract, then section one, footnote three when its anchor appears, and so on. This is where two-column journals and multi-page tables go to die.
The output is typically Markdown, HTML, or a richer structured format like Docling’s DocTags — a markup language that separates content from layout while preserving tables, code, math, and hierarchy, designed specifically for RAG and fine-tuning pipelines (IBM Research, Granite-Docling).
What are the main components of a document parsing pipeline?
The core sub-tasks, in the dependency order most production parsers respect: layout detection, OCR, table structure extraction, mathematical expression parsing, visual element analysis, and reading-order recovery (Document Parsing Unveiled, arXiv).
Each one is itself a research field. Layout detection draws on object-detection architectures originally built for natural images. Table extraction relies on structure-aware models trained on document corpora — IBM’s Docling stack uses DocLayNet for layout and TableFormer for tables, an ensemble of specialized models orchestrated as a pipeline (Docling Docs). Reading-order models often combine geometric heuristics with learned sequence prediction.
The reason the pipeline is fractured into so many specialists is not historical accident. It reflects an engineering judgment: the failure modes of each sub-task are different enough that a single model trained end-to-end on the whole problem will, in many cases, regress on the parts that the specialists handle well. The specialists have inductive biases the generalist does not.
That judgment, however, is now under pressure.
Two Architectures, Two Theories of Reading
The field has converged on two dominant architectural families, and the choice between them is the most consequential decision a parser designer makes.
The first family is the modular pipeline: a chain of specialized models — layout, then OCR, then table and formula extraction, then reading-order reconstruction — each producing intermediate output that the next stage consumes (Document Parsing Unveiled, arXiv). Docling is the canonical open-source example. Its --pipeline standard mode runs DocLayNet plus TableFormer plus an OCR engine, with each model swappable.
The second family is the unified end-to-end Vision-Language Model. A VLM ingests page images and emits structured output directly, with no intermediate layout-then-OCR handoff. The model reasons over layout and meaning jointly — it can infer that a number is “Total Amount Due” from layout, proximity, and formatting, not just from raw coordinates and text content (LlamaIndex Insights). Granite-Docling, IBM’s compact end-to-end model released alongside the Docling toolkit, is one example. Mistral OCR 3, released in late 2025, is another — markdown-first output with HTML tables that preserve column and row spans (Mistral AI News).
The split is a bet on inductive bias. Modular pipelines bake in strong priors: a page has a layout, the layout has regions, regions have content, content has reading order. End-to-end VLMs make a softer bet — that a model trained on enough rendered documents will learn those priors implicitly, and will sometimes find structure the modular pipeline’s pre-defined categories cannot describe. Both bets pay off on different document distributions.
Pure-OCR pipelines — Tesseract plus heuristic table detection — are no longer the safe default for layout-rich documents. End-to-end VLM parsers like Granite-Docling, Nougat, GOT-OCR 2.0, and DeepSeek-OCR are rapidly displacing them in production RAG, particularly for documents with complex tables, formulas, or multi-column layouts (Document Parsing Unveiled, arXiv).
What This Predicts for Your RAG Stack
The mechanism is not abstract. It makes specific predictions about what your pipeline will do under specific conditions.
- If your corpus is dominated by clean digital-native PDFs (white papers, modern manuals), a modular pipeline with strong layout and OCR models will give you the most predictable output and the cheapest re-runs.
- If your corpus contains scanned forms, handwriting, or dense tables — invoices, regulatory filings, scientific papers — an end-to-end VLM is likely to outperform on the long tail, because layout-and-meaning joint reasoning catches structure the modular path discards.
- If you observe that your RAG answers cite numbers that are plausible but wrong, the failure is probably in table reconstruction. Embeddings cannot recover topology that the parser already destroyed.
- If your reranker keeps surfacing fragments that read as half-thoughts, the failure is probably in reading-order recovery. Two-column layouts produce shuffled paragraphs that look fluent but mean nothing.
Vendor benchmarks deserve a separate caveat. LlamaIndex reports its LlamaParse Agentic mode leads on a layout-aware extraction comparison at 80.62%, ahead of Azure Document Intelligence and AWS Textract — but the comparison is published by LlamaIndex, and Unstructured’s SCORE-Bench results are likewise self-published (LlamaIndex Insights). Vendor benchmarks are useful as evidence the system can perform well on the documents the vendor chose. They are not independent rankings. Independent benchmarks like OmniDocBench, presented at CVPR 2025, are the better baseline for cross-system comparisons.
Rule of thumb: Match the parser’s inductive bias to the dominant document type in your corpus. If you cannot, run both and measure on your own pages.
When it breaks: Document parsing fails most often on documents the training distribution under-represents — handwritten annotations on scanned forms, multi-page tables that break across pages, and non-Latin scripts in mixed-language layouts. A VLM that reports 74% win rates on average can still score zero on the specific multi-hundred-page filing your compliance team needs parsed correctly. The failure modes are silent: the parser returns confident text, the embedder indexes it, and the model answers from corrupted context without flagging the corruption.
What the Pipeline Predicts About RAG
Document parsing is the upstream layer that decides what every downstream component is allowed to see. Improvements in chunkers, embedders, and rerankers are bounded by the structural fidelity of whatever the parser produced. This is also where the dependency on richer downstream patterns — including Knowledge Graphs For RAG, where structured extraction is the prerequisite for any node-and-edge model — gets paid for or skipped.
The interesting consequence: as parsers get better at preserving structure (DocTags, HTML tables with colspan and rowspan, reading-order metadata), the next bottleneck migrates downstream. Better parsing exposes weaker chunking. Better chunking exposes weaker rerankers. The RAG stack is a chain in which the upstream link decides what failures the downstream links are allowed to have.
The Data Says
Document parsing is a tower of sub-problems — layout, OCR, table structure, formulas, reading order — and the architecture choice between modular pipelines and end-to-end VLMs is a bet on which inductive biases your documents reward. The right choice depends on the corpus, not on the leaderboard. Vendor benchmarks describe what the parser can do on the vendor’s pages; only your own pages describe what it will do on yours.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors